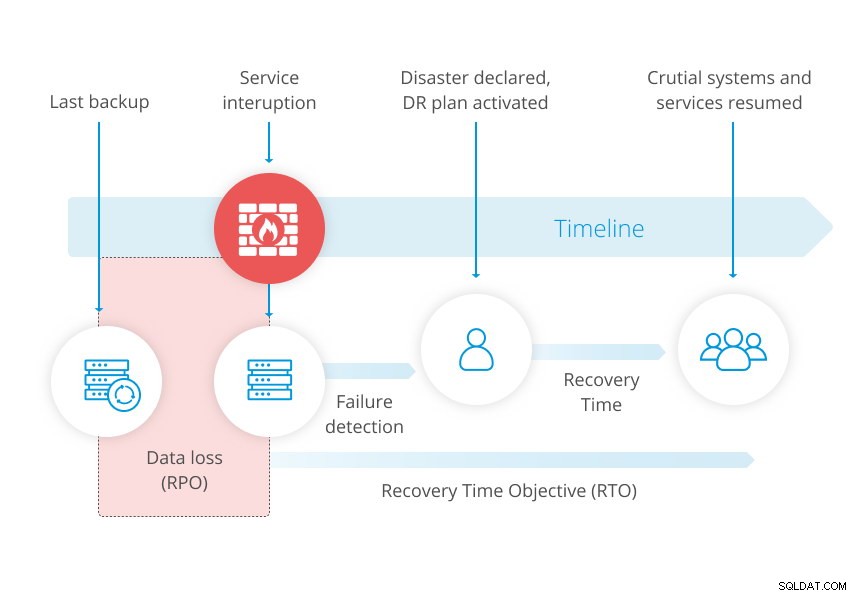
Em um plano de recuperação de desastres, seu objetivo de ponto de recuperação (RPO) é um parâmetro de recuperação chave que determina a quantidade de dados que você pode perder. O RPO é listado no tempo, de segundos a dias. Efetivamente, o RPO depende diretamente do seu sistema de backup. Ele marca a idade dos dados de backup que você deve recuperar para retomar as operações normais.
Se você fizer um backup noturno às 22h. e seu sistema de banco de dados trava além do reparo às 15h. no dia seguinte, você perde tudo o que foi alterado desde seu último backup. Seu RPO nesse contexto específico é o backup do dia anterior, o que significa que você pode perder o valor de um dia de alterações.
O diagrama abaixo do nosso whitepaper sobre recuperação de desastres ilustra o conceito.
Para RPO mais apertado, um backup pode não ser suficiente. Ao fazer backup de seu banco de dados, você está realmente tirando um instantâneo dos dados em um determinado momento. Portanto, ao restaurar um backup, você perderá as alterações que ocorreram entre o último backup e a falha.
É aqui que entra o conceito de Point In Time Recovery (PITR).
O que é PITR?
Point In Time Recovery (PITR), como o nome indica, envolve a restauração do banco de dados em qualquer momento no passado. Para poder fazer isso, precisaremos restaurar um backup e, em seguida, aplicar todas as alterações que ocorreram após o backup até o momento da falha.
Para o PostgreSQL, as alterações são armazenadas nos logs do WAL (para mais detalhes sobre os WALs e os dados que eles armazenam, você pode conferir este blog).
Portanto, há duas coisas que precisamos garantir para poder realizar um PITR:Os backups e os WALs (precisamos configurar o arquivamento contínuo para eles).
Para realizar o PITR, precisaremos recuperar o backup e então aplicar os WALs.
Quando pode ser útil?
Você pode usar essa estratégia sempre que estiver restaurando de um problema que causou a corrupção dos dados. Você precisa ter em mente que está tentando minimizar a perda de dados, mas há alguns problemas que podem fazer com que os dados não sejam mais úteis depois disso.
Alguns exemplos disso podem ser modificações de dados não planejadas (DMLs ou DDLs), falha de mídia ou manutenções de banco de dados (como atualizações) que levam à corrupção de dados. Você não poderá recuperar as alterações de dados que ocorreram após o problema.
Vamos supor que um usuário tenha realizado uma DML incorretamente, fazendo com que os dados de uma tabela inteira sejam alterados ou excluídos incorretamente. Você pode realizar um PITR do banco de dados em um local separado e depois exportar o conteúdo da tabela. Você pode então restaurar essa tabela no banco de dados existente, efetivamente revertendo para uma cópia de como a tabela estava antes do problema ocorrer.
É claro que nem sempre é possível restaurar apenas uma parte do banco de dados dessa maneira, portanto, nesse caso, você precisará restaurar todo o banco de dados para um determinado ponto e terá uma perda de dados mínima, mas inevitável (você perderá quaisquer alterações que ocorreram depois que o problema ocorreu).
Como usá-lo com ClusterControl?
Em um blog anterior, pudemos ver como implementar o PITR manualmente, agora vamos ver como usar o ClusterControl para realizar esta tarefa.
Ativando a recuperação pontual
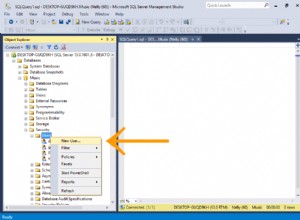
Para habilitar o recurso PITR devemos ter o WAL Archiving habilitado. Para isso podemos ir em ClusterControl -> Select PostgreSQL Cluster -> Node actions -> Enable WAL Archiving, ou simplesmente ir em ClusterControl -> Select PostgreSQL Cluster -> Backup -> Settings e habilitar a opção “Enable Point-In-Time Recovery (WAL Archiving)”, como veremos na imagem a seguir.
Devemos ter em mente que para habilitar o WAL Archiving, devemos reiniciar nosso banco de dados. O ClusterControl também pode fazer isso por nós.
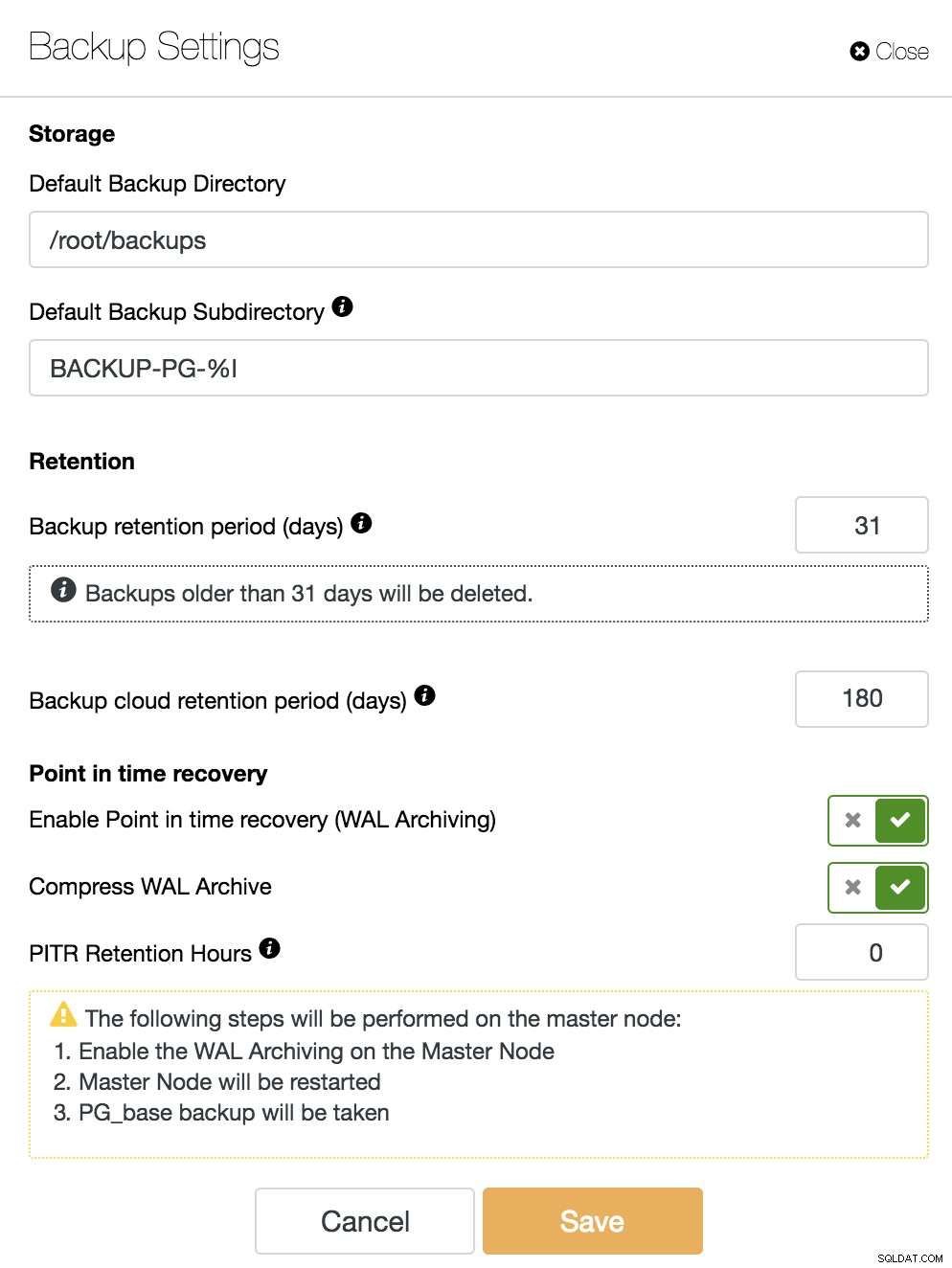
Além das opções comuns a todos os backups como o “Diretório de Backup” e o “Período de Retenção de Backup”, aqui também podemos especificar o Período de Retenção do WAL. Por padrão é 0, o que significa para sempre.
Para confirmar que temos o WAL Archiving habilitado, podemos selecionar nosso nó Master em ClusterControl -> Select PostgreSQL Cluster -> Nodes, e devemos ver a mensagem WAL Archiving Enabled, como podemos ver na imagem a seguir.
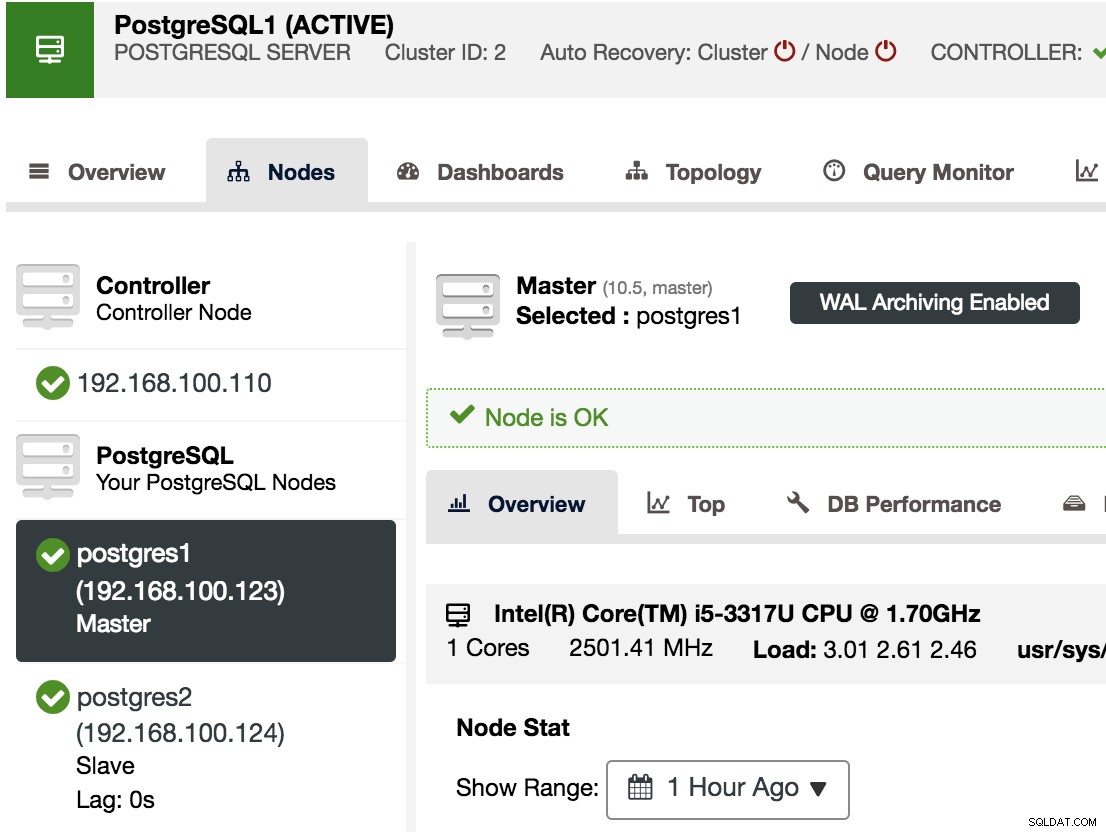
Criando um backup compatível com recuperação pontual
Com o WAL Archiving habilitado, como vimos no passo anterior, podemos criar nosso backup compatível com PITR. Para isso, vá para ClusterControl -> Select PostgreSQL Cluster -> Backup -> Create Backup.
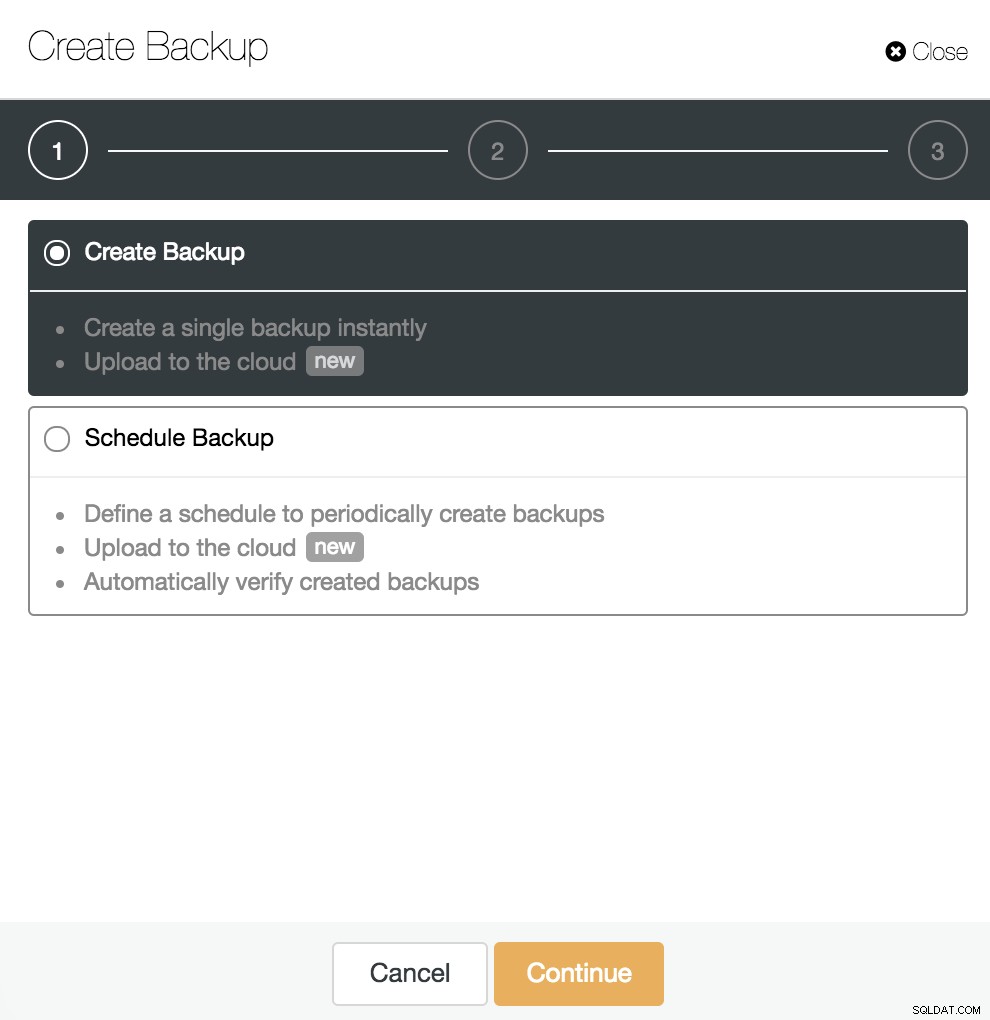
Podemos criar um novo backup ou configurar um agendado. Para o nosso exemplo, criaremos um único backup instantaneamente.
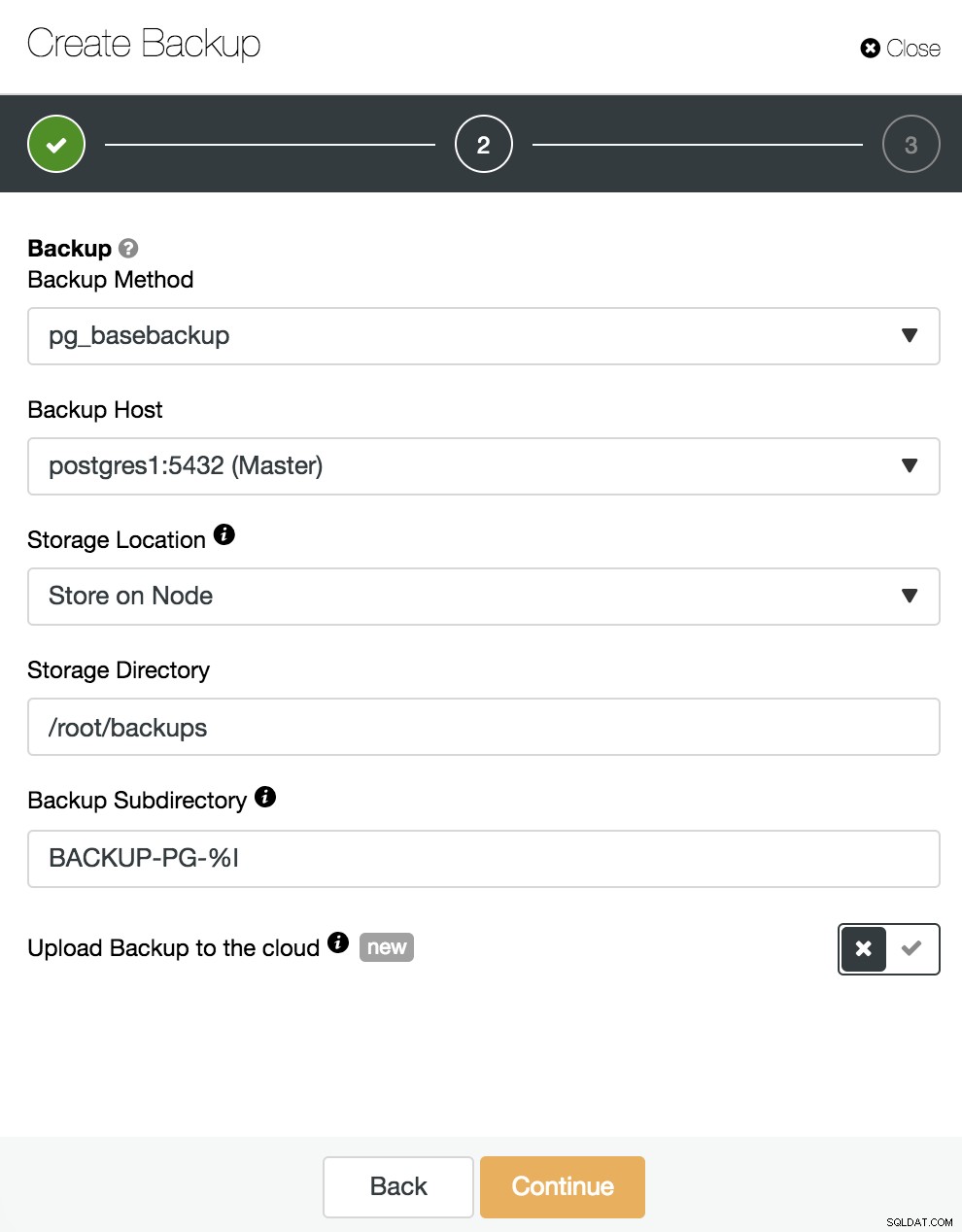
Aqui devemos escolher o método “pg_basebackup”, compatível com PITR, o servidor do qual o backup será feito (para ser compatível com PITR, deve ser o mestre), e onde queremos armazenar o backup. Também podemos enviar nosso backup para a nuvem (AWS, Google ou Azure) ativando o botão correspondente.
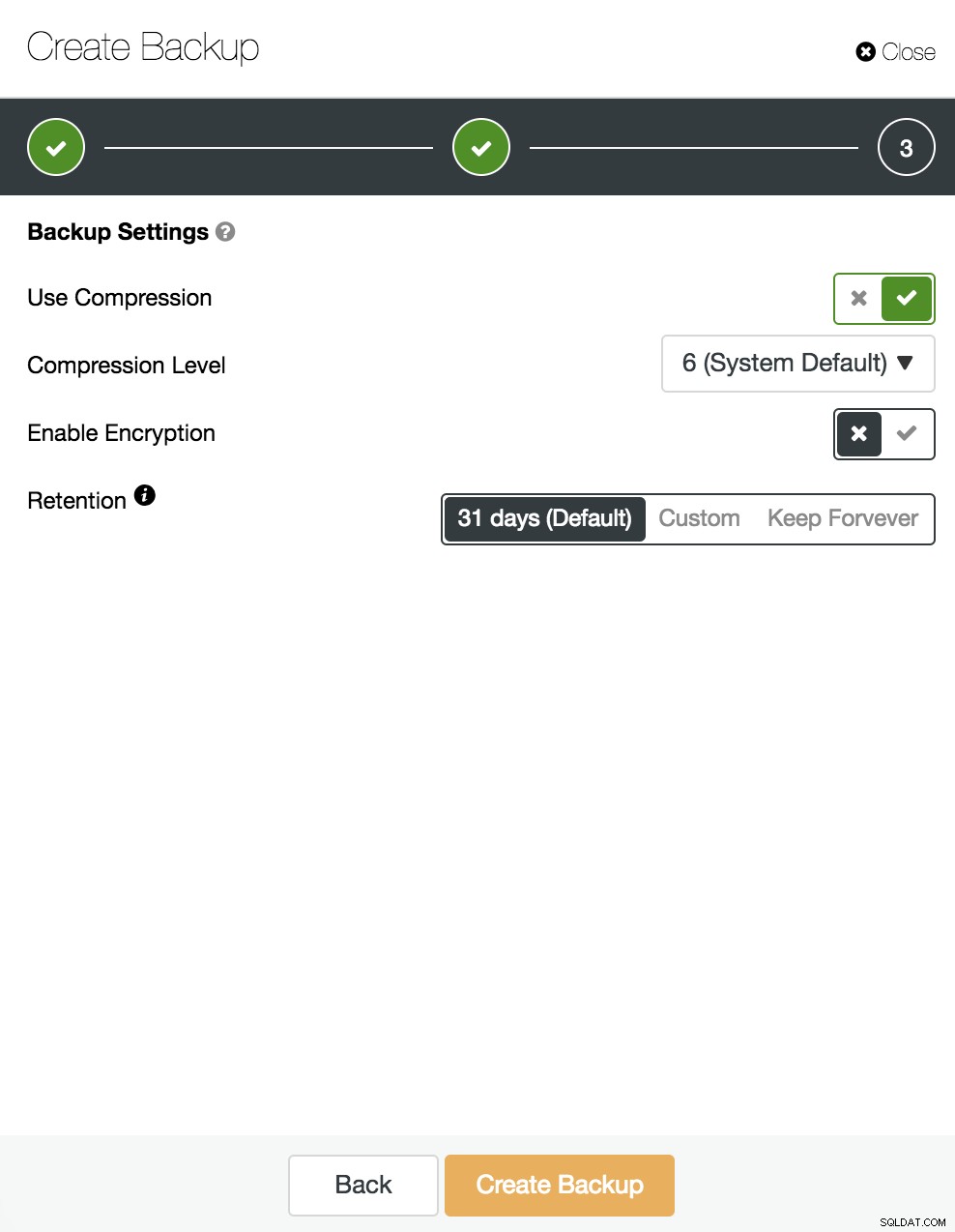
Em seguida, especificamos o uso de compactação, criptografia e retenção de nosso backup.
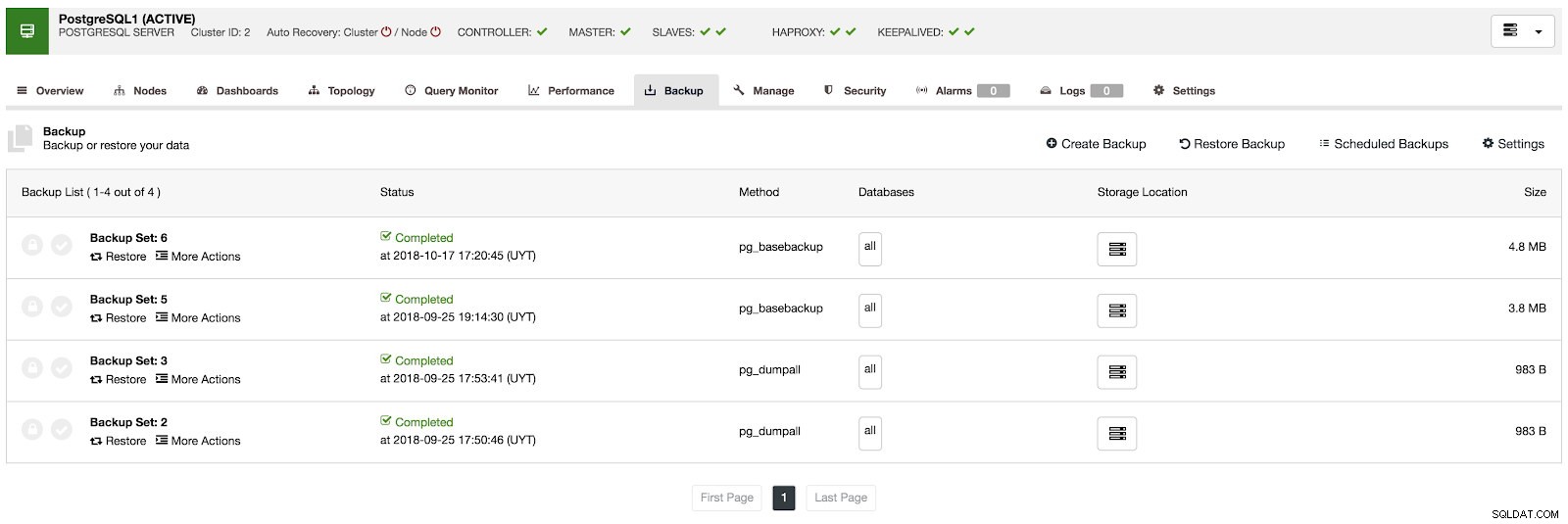
Na seção de backup, podemos ver o andamento do backup e informações como método, tamanho, local e muito mais.
Recuperação pontual de um backup
Quando o backup estiver concluído, podemos restaurá-lo usando o recurso ClusterControl PITR. Para isso, em nossa seção de backup (ClusterControl -> Select PostgreSQL Cluster -> Backup), podemos selecionar "Restaurar Backup", ou diretamente "Restaurar" no backup que desejamos restaurar.
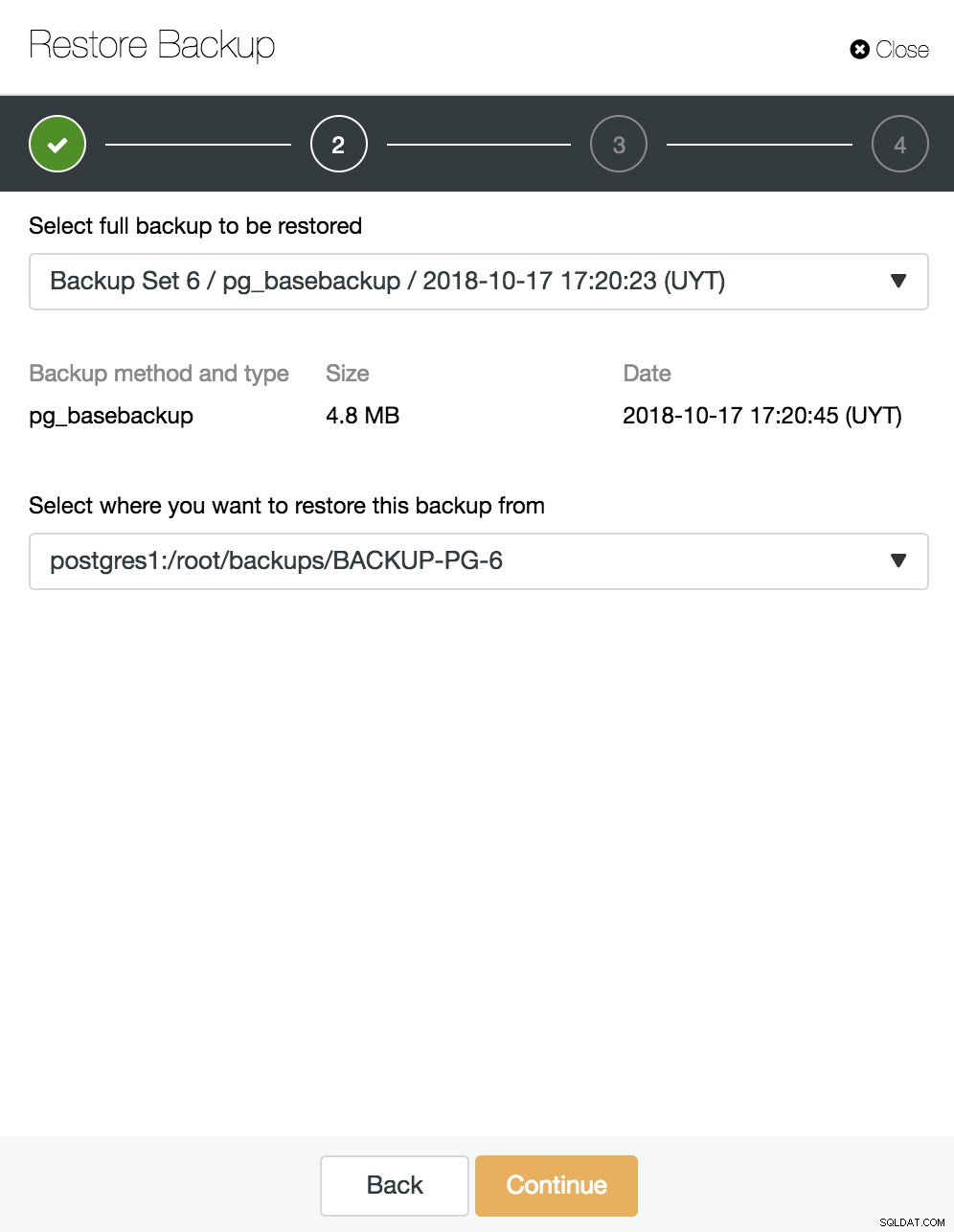
Aqui escolhemos qual backup queremos restaurar e de qual diretório.
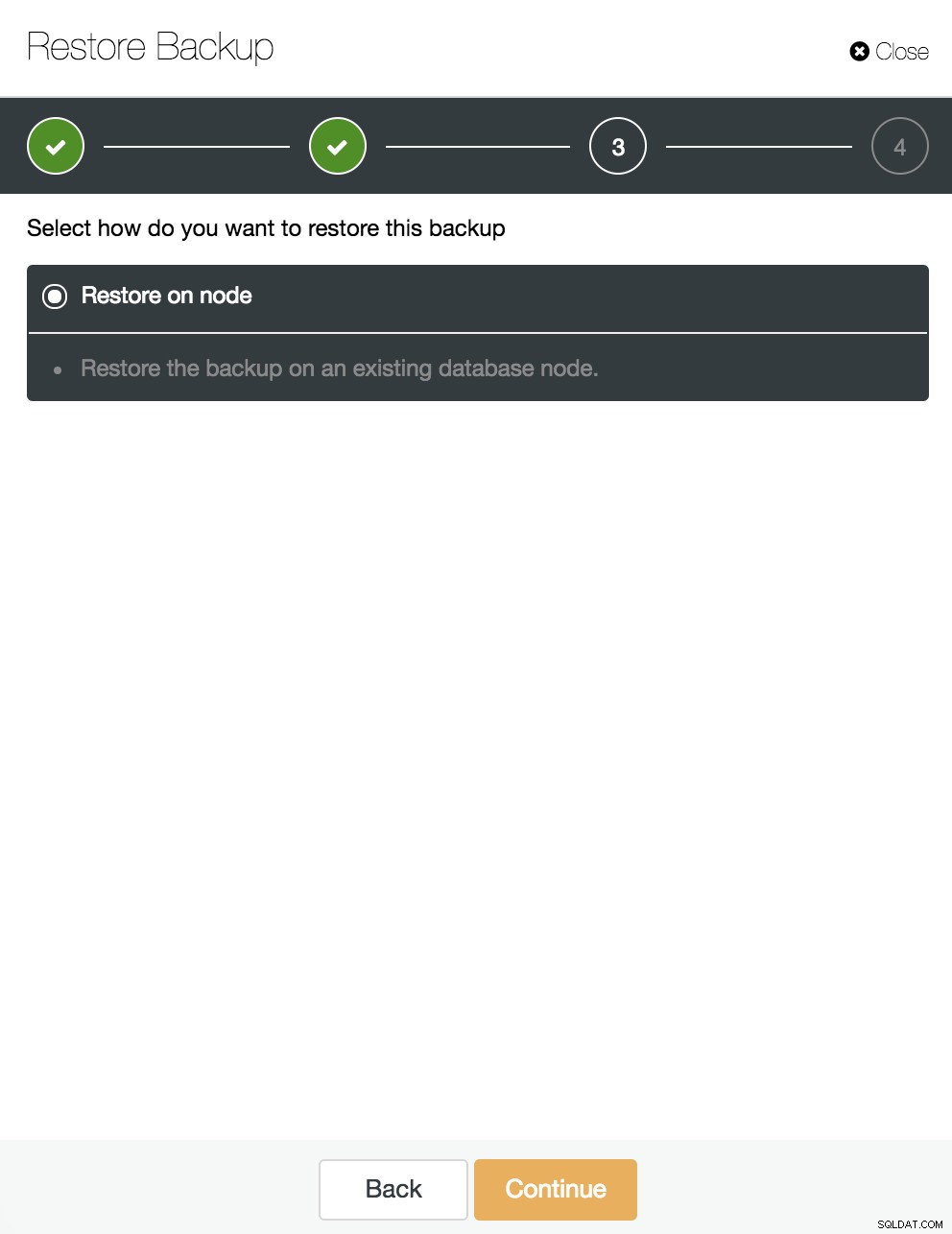
Deixamos a opção “Restaurar no nó” selecionada e continuamos.
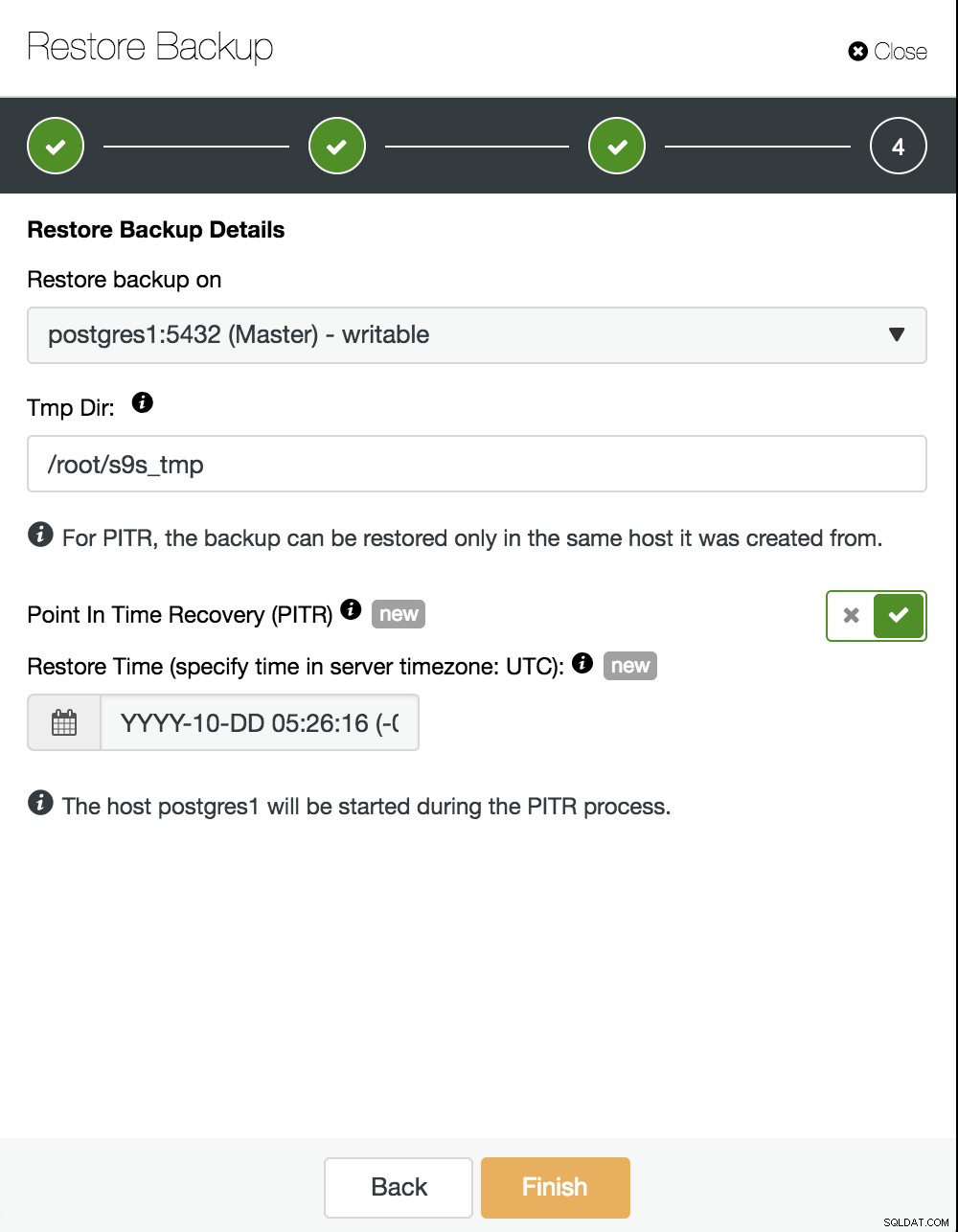
Agora devemos escolher onde restaurar nosso backup e habilitar a opção PITR. Ao especificar o tempo, será o tempo até quando nos recuperaremos. Leve em consideração que o fuso horário UTC é usado e que nosso serviço PostgreSQL no mestre será reiniciado.
Podemos monitorar o progresso de nossa restauração na seção Activity em nosso ClusterControl.
Conclusão
PITR é um recurso necessário para atender a um RPO apertado. Precisamos configurá-lo corretamente para garantir um plano de recuperação de desastres correto. O ClusterControl fornece uma interface fácil de usar para ajudá-lo a implementar o PITR para seus bancos de dados PostgreSQL.