E agora chegamos ao segundo artigo em nossa migração da série Oracle para PostgreSQL. Desta vez, veremos o
START WITH/CONNECT BY construir. No Oracle,
START WITH/CONNECT BY é usado para criar uma estrutura de lista vinculada individualmente começando em uma determinada linha sentinela. A lista encadeada pode ter a forma de uma árvore e não tem nenhum requisito de balanceamento. Para ilustrar, vamos começar com uma consulta e presumir que a tabela tenha 5 linhas.
SELECT * FROM person;
last_name | first_name | id | parent_id
------------+------------+----+-----------
Dunstan | Andrew | 1 | (null)
Roybal | Kirk | 2 | 1
Riggs | Simon | 3 | 1
Eisentraut | Peter | 4 | 1
Thomas | Shaun | 5 | 3
(5 rows)Aqui está a consulta hierárquica da tabela usando a sintaxe Oracle.
select id, parent_id
from person
start with parent_id IS NULL
connect by prior id = parent_id;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3E aqui está novamente usando o PostgreSQL.
WITH RECURSIVE a AS (
SELECT id, parent_id
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT id, parent_id FROM a;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3
(5 rows)Essa consulta faz uso de muitos recursos do PostgreSQL, então vamos analisá-la lentamente.
WITH RECURSIVEEsta é uma “Expressão de Tabela Comum” (CTE). Ele define um conjunto de consultas que serão executadas na mesma instrução, não apenas na mesma transação. Você pode ter qualquer número de expressões entre parênteses e uma declaração final. Para este uso, precisamos apenas de um. Ao declarar essa instrução como
RECURSIVE , ele será executado iterativamente até que não sejam retornadas mais linhas. SELECT
UNION ALL
SELECTEsta é uma frase prescrita para uma consulta recursiva. Ele é definido na documentação como o método para distinguir o ponto de partida e o algoritmo de recursão. Nos termos do Oracle, você pode pensar neles como a cláusula START WITH unida à cláusula CONNECT BY.
JOIN a ON a.id = d.parent_idEssa é uma associação automática à instrução CTE que fornece os dados da linha anterior para a iteração subsequente.
Para ilustrar como isso funciona, vamos adicionar um indicador de iteração à consulta.
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT * FROM a;
id | parent_id | recursion_level
----+-----------+-----------------
1 | (null) | 1
4 | 1 | 2
3 | 1 | 2
2 | 1 | 2
5 | 3 | 3
(5 rows)Inicializamos o indicador de nível de recursão com um valor. Observe que nas linhas que são retornadas, o primeiro nível de recursão ocorre apenas uma vez. Isso porque a primeira cláusula é executada apenas uma vez.
A segunda cláusula é onde a mágica iterativa acontece. Aqui, temos visibilidade dos dados da linha anterior, juntamente com os dados da linha atual. Isso nos permite realizar os cálculos recursivos.
Simon Riggs tem um vídeo muito bom sobre como usar esse recurso para o design de banco de dados gráfico. É altamente informativo e você deve dar uma olhada.

Você deve ter notado que essa consulta pode levar a uma condição circular. Está correto. Cabe ao desenvolvedor adicionar uma cláusula de limitação à segunda consulta para evitar essa recursão sem fim. Por exemplo, apenas recuando 4 níveis de profundidade antes de desistir.
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level --<-- initialize it here
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1 --<-- iteration increment
FROM person d
JOIN a ON a.id = d.parent_id
WHERE d.recursion_level <= 4 --<-- bail out here
) SELECT * FROM a;Os nomes das colunas e os tipos de dados são determinados pela primeira cláusula. Observe que o exemplo usa um operador de conversão para o nível de recursão. Em um gráfico muito profundo, esse tipo de dados também pode ser definido como
1::bigint recursion_level . Este gráfico é muito fácil de visualizar com um pequeno script de shell e o utilitário graphviz.
#!/bin/bash -
#===============================================================================
#
# FILE: pggraph
#
# USAGE: ./pggraph
#
# DESCRIPTION:
#
# OPTIONS: ---
# REQUIREMENTS: ---
# BUGS: ---
# NOTES: ---
# AUTHOR: Kirk Roybal (), example@sqldat.com
# ORGANIZATION:
# CREATED: 04/21/2020 14:09
# REVISION: ---
#===============================================================================
set -o nounset # Treat unset variables as an error
dbhost=localhost
dbport=5432
dbuser=$USER
dbname=$USER
ScriptVersion="1.0"
output=$(basename $0).dot
#=== FUNCTION ================================================================
# NAME: usage
# DESCRIPTION: Display usage information.
#===============================================================================
function usage ()
{
cat <<- EOT
Usage : ${0##/*/} [options] [--]
Options:
-h|host name Database Host Name default:localhost
-n|name name Database Name default:$USER
-o|output file Output file default:$output.dot
-p|port number TCP/IP port default:5432
-u|user name User name default:$USER
-v|version Display script version
EOT
} # ---------- end of function usage ----------
#-----------------------------------------------------------------------
# Handle command line arguments
#-----------------------------------------------------------------------
while getopts ":dh:n:o:p:u:v" opt
do
case $opt in
d|debug ) set -x ;;
h|host ) dbhost="$OPTARG" ;;
n|name ) dbname="$OPTARG" ;;
o|output ) output="$OPTARG" ;;
p|port ) dbport=$OPTARG ;;
u|user ) dbuser=$OPTARG ;;
v|version ) echo "$0 -- Version $ScriptVersion"; exit 0 ;;
\? ) echo -e "\n Option does not exist : $OPTARG\n"
usage; exit 1 ;;
esac # --- end of case ---
done
shift $(($OPTIND-1))
[[ -f "$output" ]] && rm "$output"
tee "$output" <<eof< span="">
digraph g {
node [shape=rectangle]
rankdir=LR
EOF
psql -h $dbhost -U $dbuser -d $dbname -p $dbport -qtAf cte.sql |
sed -e 's/^/node/' -e 's/.*(null)|/node/' -e 's/^/\t/' -e 's/|[[:digit:]]*$//' |
sed -e 's/|/ -> node/' | tee -a "$output"
tee -a "$output" <<eof< span="">
}
EOF
dot -Tpng "$output" > "${output/dot/png}"
[[ -f "$output" ]] && rm "$output"
open "${output/dot/png}"</eof<></eof<>Este script requer esta instrução SQL em um arquivo chamado cte.sql
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT parent_id, id, recursion_level FROM a;Então você invoca assim:
chmod +x pggraph
./pggraphE você verá o gráfico resultante.

INSERT INTO person (id, parent_id) VALUES (6,2);Execute o utilitário novamente e veja as alterações imediatas em seu gráfico direcionado:

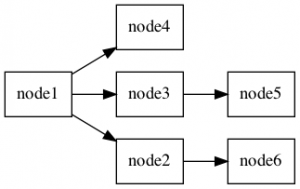
Agora, isso não era tão difícil agora, era?



