Este artigo é a décima segunda parte de uma série sobre expressões de tabela nomeada. Até agora, abordei tabelas derivadas e CTEs, que são expressões de tabela nomeada com escopo de instrução, e exibições, que são expressões de tabela nomeada reutilizáveis. Este mês, apresento funções com valor de tabela em linha, ou iTVFs, e descrevo seus benefícios em comparação com outras expressões de tabela nomeadas. Eu também os comparo com procedimentos armazenados, focando principalmente nas diferenças em termos de estratégia de otimização padrão, e planejo o armazenamento em cache e o comportamento de reutilização. Há muito o que abordar em termos de otimização, então começarei a discussão este mês e continuarei no próximo mês.
Em meus exemplos, usarei um banco de dados de exemplo chamado TSQLV5. Você pode encontrar o script que o cria e o preenche aqui e seu diagrama ER aqui.
O que é uma função com valor de tabela embutido?
Em comparação com as expressões de tabela nomeadas cobertas anteriormente, os iTVFs se assemelham principalmente a visualizações. Assim como as visualizações, os iTVFs são criados como um objeto permanente no banco de dados e, portanto, são reutilizáveis por usuários que têm permissão para interagir com eles. A principal vantagem dos iTVFs em relação às visualizações é o fato de suportarem parâmetros de entrada. Portanto, a maneira mais fácil de descrever uma iTVF é como uma visualização parametrizada, embora tecnicamente você a crie com uma instrução CREATE FUNCTION e não com uma instrução CREATE VIEW.
É importante não confundir iTVFs com funções com valor de tabela de várias instruções (MSTVFs). A primeira é uma expressão de tabela nomeada inlinável baseada em uma única consulta semelhante a uma exibição e é o foco deste artigo. Este último é um módulo programático que retorna uma variável de tabela como sua saída, com fluxo de multi-instruções em seu corpo cuja finalidade é preencher a variável de tabela retornada com dados.
Sintaxe
Aqui está a sintaxe T-SQL para criar um iTVF:
CREATE [ OR ALTER ] FUNCTION [
[ (
TABELA DE DEVOLUÇÕES
[ WITH
COMO
RETORNA
Observe na sintaxe a capacidade de definir parâmetros de entrada.
A finalidade do atributo SCHEMABIDNING é a mesma das visualizações e deve ser avaliada com base em considerações semelhantes. Para obter detalhes, consulte a Parte 10 da série.
Um exemplo
Como exemplo para um iTVF, suponha que você precise criar uma expressão de tabela nomeada reutilizável que aceite como entradas um ID de cliente (@custid) e um número (@n) e retorne o número solicitado de pedidos mais recentes da tabela Sales.Orders para o cliente de entrada.
Você não pode implementar esta tarefa com uma visualização, pois as visualizações não têm suporte para parâmetros de entrada. Como mencionado, você pode pensar em um iTVF como uma visualização parametrizada e, como tal, é a ferramenta certa para essa tarefa.
Antes de implementar a função em si, aqui está o código para criar um índice de suporte na tabela Sales.Orders:
USE TSQLV5; GO CREATE INDEX idx_nc_cid_odD_oidD_i_eid ON Sales.Orders(custid, orderdate DESC, orderid DESC) INCLUDE(empid);
E aqui está o código para criar a função, chamada Sales.GetTopCustOrders:
CREATE OR ALTER FUNCTION Sales.GetTopCustOrders ( @custid AS INT, @n AS BIGINT ) RETURNS TABLE AS RETURN SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Assim como nas tabelas e visualizações base, quando você está recuperando dados, especifica iTVFs na cláusula FROM de uma instrução SELECT. Aqui está um exemplo solicitando os três pedidos mais recentes para o cliente 1:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
Vou me referir a este exemplo como Consulta 1. O plano para a Consulta 1 é mostrado na Figura 1.
 Figura 1:plano para a consulta 1
Figura 1:plano para a consulta 1 O que há de inline sobre iTVFs?
Se você está se perguntando sobre a origem do termo inline em funções com valor de tabela inline, tem a ver com como elas são otimizadas. O conceito de inlining é aplicável a todos os quatro tipos de expressões de tabela nomeadas que o T-SQL suporta e, em parte, envolve o que descrevi na Parte 4 da série como desaninhamento/substituição. Certifique-se de revisitar a seção relevante na Parte 4 se precisar de uma atualização.
Como você pode ver na Figura 1, graças ao fato de a função ter sido incorporada, o SQL Server conseguiu criar um plano ideal que interage diretamente com os índices da tabela base subjacente. No nosso caso, o plano realiza uma busca no índice de suporte que você criou anteriormente.
Os iTVFs levam o conceito de inlining um passo adiante, aplicando a otimização de incorporação de parâmetros por padrão. Paul White descreve a otimização de incorporação de parâmetros em seu excelente artigo Parameter Sniffing, Embedding, and the RECOMPILE Options. Com a otimização de incorporação de parâmetros, as referências de parâmetros de consulta são substituídas pelos valores de constantes literais da execução atual e, em seguida, o código com as constantes é otimizado.
Observe no plano da Figura 1 que tanto o predicado seek do operador Index Seek quanto a expressão top do operador Top mostram os valores constantes literais incorporados 1 e 3 da execução da consulta atual. Eles não mostram os parâmetros @custid e @n, respectivamente.
Com iTVFs, a otimização de incorporação de parâmetros é usada por padrão. Com procedimentos armazenados, as consultas parametrizadas são otimizadas por padrão. Você precisa adicionar OPTION(RECOMPILE) à consulta de um procedimento armazenado para solicitar a otimização de incorporação de parâmetros. Mais detalhes sobre otimização de iTVFs versus procedimentos armazenados, incluindo implicações, em breve.
Modificação de dados por meio de iTVFs
Lembre-se da Parte 11 da série que, desde que certos requisitos sejam atendidos, as expressões de tabela nomeada podem ser alvo de instruções de modificação. Essa capacidade se aplica a iTVFs da mesma forma que se aplica a visualizações. Por exemplo, aqui está o código que você pode usar para excluir os três pedidos mais recentes do cliente 1 (na verdade, não execute isso):
DELETE FROM Sales.GetTopCustOrders(1, 3);
Especificamente em nosso banco de dados, a tentativa de executar esse código falharia devido à aplicação de integridade referencial (os pedidos afetados têm linhas de pedido relacionadas na tabela Sales.OrderDetails), mas é um código válido e com suporte.
iTVFs x procedimentos armazenados
Conforme mencionado anteriormente, a estratégia de otimização de consulta padrão para iTVFs é diferente daquela para procedimentos armazenados. Com iTVFs, o padrão é usar a otimização de incorporação de parâmetros. Com procedimentos armazenados, o padrão é otimizar consultas parametrizadas ao aplicar a detecção de parâmetros. Para obter a incorporação de parâmetros para uma consulta de procedimento armazenado, você precisa adicionar OPTION(RECOMPILE).
Tal como acontece com muitas estratégias e técnicas de otimização, a incorporação de parâmetros tem seus prós e contras.
A principal vantagem é que permite simplificações de consulta que às vezes podem resultar em planos mais eficientes. Algumas dessas simplificações são realmente fascinantes. Paul demonstra isso com procedimentos armazenados em seu artigo, e vou demonstrar isso com iTVFs no próximo mês.
A principal desvantagem da otimização de incorporação de parâmetros é que você não obtém um cache de plano eficiente e um comportamento de reutilização como faz para planos parametrizados. Com cada combinação distinta de valores de parâmetro, você obtém uma string de consulta distinta e, portanto, uma compilação separada que resulta em um plano separado em cache. Com iTVFs com entradas constantes, você pode obter o comportamento de reutilização do plano, mas somente se os mesmos valores de parâmetro forem repetidos. Obviamente, uma consulta de procedimento armazenado com OPTION(RECOMPILE) não reutilizará um plano mesmo ao repetir os mesmos valores de parâmetro, por solicitação.
Vou demonstrar três casos:
- Planos reutilizáveis com constantes resultantes da otimização de incorporação de parâmetros padrão para consultas iTVF com constantes
- Planos parametrizados reutilizáveis resultantes da otimização padrão de consultas de procedimento armazenado parametrizado
- Planos não reutilizáveis com constantes resultantes da otimização de incorporação de parâmetros para consultas de procedimento armazenado com OPTION(RECOMPILE)
Vamos começar com o caso nº 1.
Use o código a seguir para consultar nosso iTVF com @custid =1 e @n =3:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
Como lembrete, esta seria a segunda execução do mesmo código, pois você já o executou uma vez com os mesmos valores de parâmetro anteriormente, resultando no plano mostrado na Figura 1.
Use o seguinte código para consultar o iTVF com @custid =2 e @n =3 uma vez:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(2, 3);
Vou me referir a este código como Query 2. O plano para Query 2 é mostrado na Figura 2.
 Figura 2:plano para consulta 2
Figura 2:plano para consulta 2 Lembre-se de que o plano na Figura 1 para a Consulta 1 se refere à constante ID do cliente 1 no predicado de busca, enquanto esse plano se refere à constante ID do cliente 2.
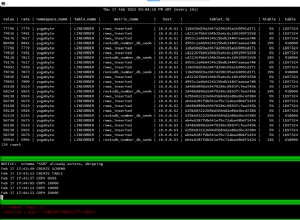
Use o código a seguir para examinar as estatísticas de execução da consulta:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders(%';
Este código gera a seguinte saída:
plan_handle execution_count text query_plan ------------------- --------------- ---------------------------------------------- ---------------- 0x06000B00FD9A1... 1 SELECT ... FROM Sales.GetTopCustOrders(2, 3); <ShowPlanXML...> 0x06000B00F5C34... 2 SELECT ... FROM Sales.GetTopCustOrders(1, 3); <ShowPlanXML...> (2 rows affected)
Existem dois planos separados criados aqui:um para a consulta com o ID do cliente 1, que foi usado duas vezes, e outro para a consulta com o ID do cliente 2, que foi usado uma vez. Com um número muito grande de combinações distintas de valores de parâmetros, você terá um grande número de compilações e planos em cache.
Vamos prosseguir com o caso nº 2:a estratégia de otimização padrão de consultas de procedimento armazenado parametrizado. Use o código a seguir para encapsular nossa consulta em um procedimento armazenado chamado Sales.GetTopCustOrders2:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Use o código a seguir para executar o procedimento armazenado com @custid =1 e @n =3 duas vezes:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
A primeira execução aciona a otimização da consulta, resultando no plano parametrizado mostrado na Figura 3:
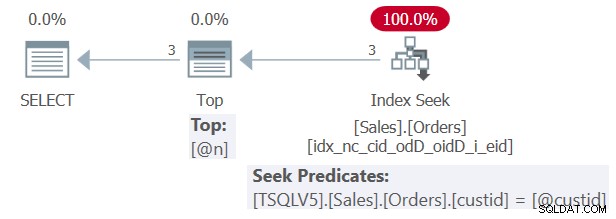 Figura 3:Plan for Sales.GetTopCustOrders2 proc
Figura 3:Plan for Sales.GetTopCustOrders2 proc Observe a referência ao parâmetro @custid no predicado de busca e ao parâmetro @n na expressão superior.
Use o código a seguir para executar o procedimento armazenado com @custid =2 e @n =3 uma vez:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
O plano parametrizado em cache mostrado na Figura 3 é reutilizado novamente.
Use o código a seguir para examinar as estatísticas de execução da consulta:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Este código gera a seguinte saída:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 3 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
Apenas um plano parametrizado foi criado e armazenado em cache e usado três vezes, apesar da alteração dos valores de ID do cliente.
Vamos para o caso nº 3. Como mencionado, com consultas de procedimento armazenado, você pode obter otimização de incorporação de parâmetros ao usar OPTION(RECOMPILE). Use o código a seguir para alterar a consulta do procedimento para incluir esta opção:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC OPTION(RECOMPILE); GO
Execute o proc com @custid =1 e @n =3 duas vezes:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
Você obtém o mesmo plano mostrado anteriormente na Figura 1 com as constantes incorporadas.
Execute o proc com @custid =2 e @n =3 uma vez:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
Você obtém o mesmo plano mostrado anteriormente na Figura 2 com as constantes incorporadas.
Examine as estatísticas de execução da consulta:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Este código gera a seguinte saída:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 1 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
A contagem de execução mostra 1, refletindo apenas a última execução. O SQL Server armazena em cache o último plano executado, para que possa mostrar estatísticas dessa execução, mas, por solicitação, não reutiliza o plano. Se você verificar o plano mostrado no atributo query_plan, descobrirá que é aquele criado para as constantes na última execução, mostrada anteriormente na Figura 2.
Se você está atrás de menos compilações e comportamento eficiente de armazenamento em cache e reutilização, a abordagem padrão de otimização de procedimento armazenado de consultas parametrizadas é o caminho a seguir.
Há uma grande vantagem que uma implementação baseada em iTVF tem sobre uma baseada em procedimento armazenado – quando você precisa aplicar a função a cada linha em uma tabela e passar colunas da tabela como entradas. Por exemplo, suponha que você precise retornar os três pedidos mais recentes para cada cliente na tabela Sales.Customers. Nenhuma construção de consulta permite que você aplique um procedimento armazenado por linha em uma tabela. Você pode implementar uma solução iterativa com um cursor, mas é sempre um bom dia quando você pode evitar cursores. Combinando o operador APPLY com uma chamada iTVF, você pode realizar a tarefa de forma agradável e limpa, assim:
SELECT C.custid, O.orderid, O.orderdate, O.empid FROM Sales.Customers AS C CROSS APPLY Sales.GetTopCustOrders( C.custid, 3 ) AS O;
Este código gera a seguinte saída (abreviada):
custid orderid orderdate empid ----------- ----------- ---------- ----------- 1 11011 2019-04-09 3 1 10952 2019-03-16 1 1 10835 2019-01-15 1 2 10926 2019-03-04 4 2 10759 2018-11-28 3 2 10625 2018-08-08 3 ... (263 rows affected)
A chamada de função é incorporada e a referência ao parâmetro @custid é substituída pela correlação C.custid. Isso resulta no plano mostrado na Figura 4.
 Figura 4:planejar a consulta com APPLY e Sales.GetTopCustOrders iTVF
Figura 4:planejar a consulta com APPLY e Sales.GetTopCustOrders iTVF O plano verifica algum índice na tabela Sales.Customers para obter o conjunto de IDs de cliente e aplica uma busca no índice de suporte criado anteriormente em Sales.Orders per customer. Há apenas um plano desde que a função foi incorporada na consulta externa, transformando-se em uma junção correlacionada ou lateral. Esse plano é altamente eficiente, especialmente quando a coluna custid em Sales.Orders é muito densa, ou seja, quando há um pequeno número de IDs de clientes distintos.
Claro, existem outras maneiras de implementar essa tarefa, como usar um CTE com a função ROW_NUMBER. Essa solução tende a funcionar melhor do que a baseada em APPLY quando a coluna custid na tabela Sales.Orders tem baixa densidade. De qualquer forma, a tarefa específica que usei em meus exemplos não é tão importante para os propósitos de nossa discussão. Meu ponto era explicar as diferentes estratégias de otimização que o SQL Server emprega com as diferentes ferramentas.
Quando terminar, use o seguinte código para limpeza:
DROP INDEX IF EXISTS idx_nc_cid_odD_oidD_i_eid ON Sales.Orders;
Resumo e o que vem a seguir
Então, o que aprendemos com isso?
Um iTVF é uma expressão de tabela nomeada parametrizada reutilizável.
O SQL Server usa uma estratégia de otimização de incorporação de parâmetros com iTVFs por padrão e uma estratégia de otimização de consulta parametrizada com consultas de procedimento armazenado. Adicionar OPTION(RECOMPILE) a uma consulta de procedimento armazenado pode resultar na otimização de incorporação de parâmetros.
Se você deseja obter menos compilações e um cache de plano eficiente e comportamento de reutilização, os planos de consulta de procedimento parametrizado são o caminho a percorrer.
Os planos para consultas iTVF são armazenados em cache e podem ser reutilizados, desde que os mesmos valores de parâmetro sejam repetidos.
Você pode combinar convenientemente o uso do operador APPLY e um iTVF para aplicar o iTVF a cada linha da tabela esquerda, passando colunas da tabela esquerda como entradas para o iTVF.
Como mencionado, há muito o que cobrir sobre a otimização de iTVFs. Este mês, comparei iTVFs e procedimentos armazenados em termos da estratégia de otimização padrão e planejei o armazenamento em cache e o comportamento de reutilização. No próximo mês, aprofundarei as simplificações resultantes da otimização de incorporação de parâmetros.