Às vezes é difícil gerenciar uma grande quantidade de dados em uma empresa, principalmente com o incremento exponencial do uso de Data Analytics e IoT. Dependendo do tamanho, essa quantidade de dados pode afetar o desempenho de seus sistemas e você provavelmente precisará dimensionar seus bancos de dados ou encontrar uma maneira de corrigir isso. Existem diferentes maneiras de dimensionar seus bancos de dados PostgreSQL e uma delas é o Sharding. Neste blog, veremos o que é o Sharding e como configurá-lo no PostgreSQL usando o ClusterControl para simplificar a tarefa.
O que é fragmentação?
Sharding é a ação de otimizar um banco de dados separando os dados de uma grande tabela em várias pequenas. Tabelas menores são Shards (ou partições). Particionamento e fragmentação são conceitos semelhantes. A principal diferença é que a fragmentação implica que os dados estão espalhados por vários computadores, enquanto o particionamento consiste em agrupar subconjuntos de dados em uma única instância de banco de dados.
Existem dois tipos de fragmentação:
-
Fragmentação horizontal:Cada nova tabela tem o mesmo esquema da tabela grande, mas linhas exclusivas. É útil quando as consultas tendem a retornar um subconjunto de linhas que geralmente são agrupadas.
-
Fragmentação vertical:cada nova tabela tem um esquema que é um subconjunto do esquema da tabela original. É útil quando as consultas tendem a retornar apenas um subconjunto de colunas dos dados.
Vamos ver um exemplo:
Tabela original
| ID | Nome | Idade | País |
|---|---|---|---|
| 1 | James Smith | 26 | EUA |
| 2 | Mary Johnson | 31 | Alemanha |
| 3 | Robert Williams | 54 | Canadá |
| 4 | Jennifer Brown | 47 | França |
Fragmentação vertical
| Fragmento1 | Shard2 | |||
|---|---|---|---|---|
| ID | Nome | Idade | ID | País |
| 1 | James Smith | 26 | 1 | EUA |
| 2 | Mary Johnson | 31 | 2 | Alemanha |
| 3 | Robert Williams | 54 | 3 | Canadá |
| 4 | Jennifer Brown | 47 | 4 | França |
Fragmentação horizontal
| Fragmento1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Nome | Idade | País | ID | Nome | Idade | País |
| 1 | James Smith | 26 | EUA | 3 | Robert Williams | 54 | Canadá |
| 2 | Mary Johnson | 31 | Alemanha | 4 | Jennifer Brown | 47 | França |
Agora que analisamos alguns conceitos de fragmentação, vamos para a próxima etapa.
Como implantar um cluster PostgreSQL?
Usaremos o ClusterControl para esta tarefa. Se você ainda não está usando o ClusterControl, você pode instalá-lo e implantar ou importar seu banco de dados PostgreSQL atual selecionando a opção “Importar” e seguir os passos para aproveitar todos os recursos do ClusterControl como backups, failover automático, alertas, monitoramento e muito mais .
Para realizar um deployment a partir do ClusterControl, basta selecionar a opção “Deploy” e seguir as instruções que aparecem.
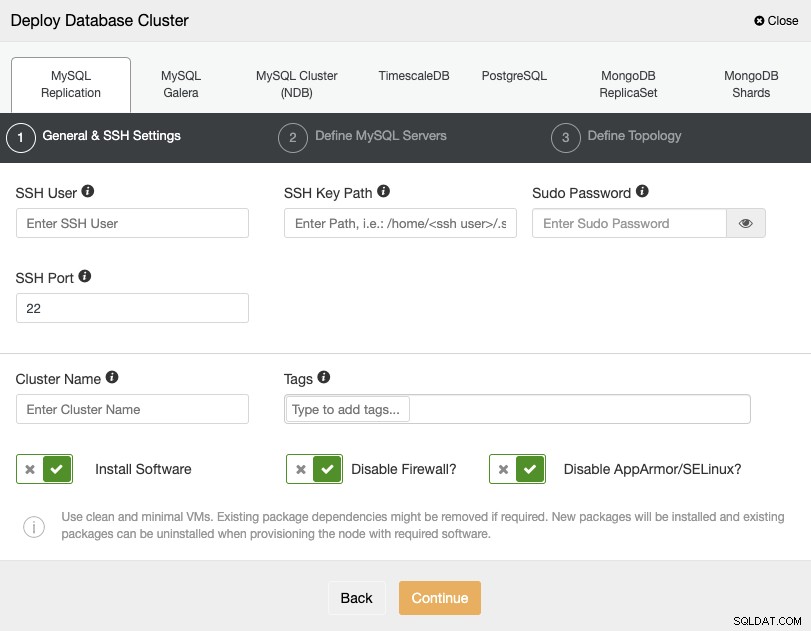
Ao selecionar PostgreSQL, você deve especificar seu usuário, chave ou senha e Porta para conectar por SSH aos seus servidores. Você também pode adicionar um nome para seu novo cluster e, se desejar, também pode usar o ClusterControl para instalar o software e as configurações correspondentes para você.
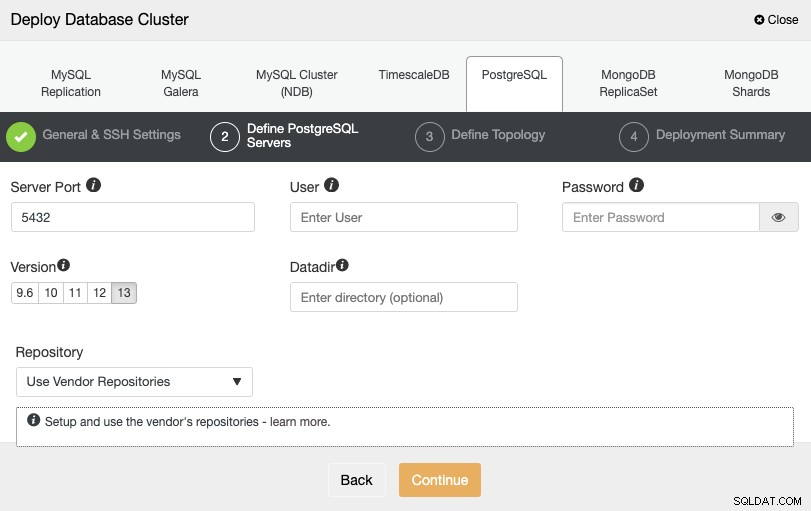
Após configurar as informações de acesso SSH, você precisa definir as credenciais do banco de dados , versão e datadir (opcional). Você também pode especificar qual repositório usar.
Para a próxima etapa, você precisa adicionar seus servidores ao cluster que você criará usando o endereço IP ou o nome do host.
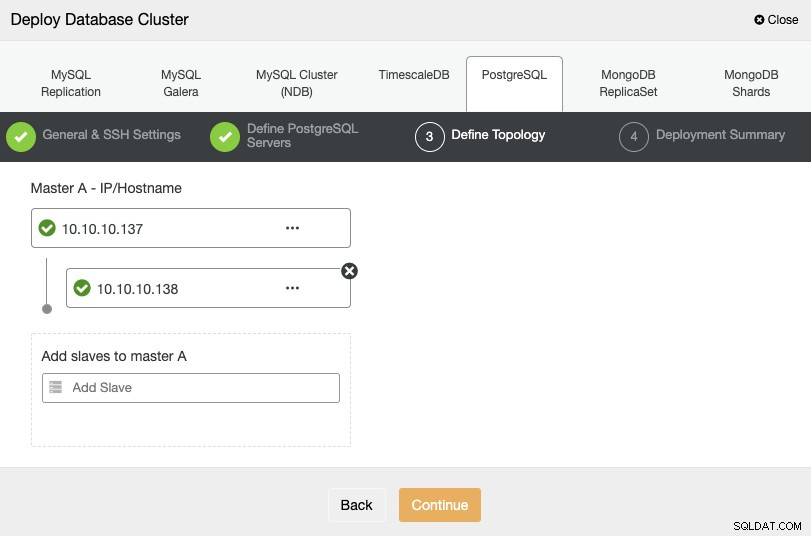
Na última etapa, você pode escolher se sua replicação será síncrona ou Assíncrono e, em seguida, basta pressionar “Implantar”.
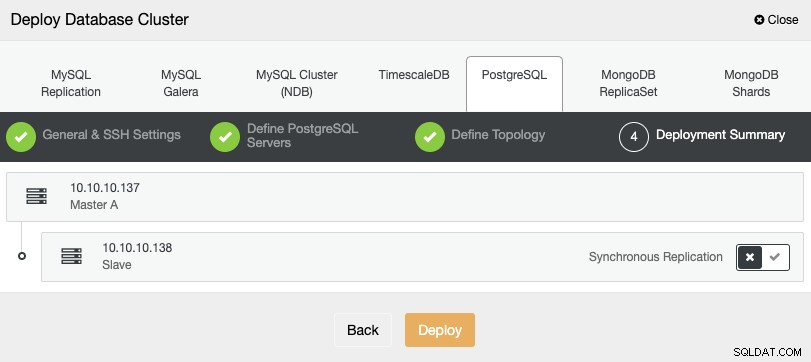
Quando a tarefa for concluída, você verá seu novo cluster PostgreSQL no tela principal do ClusterControl.

Agora que seu cluster foi criado, você pode executar várias tarefas nele como adicionar um balanceador de carga (HAProxy), pool de conexões (pgBouncer) ou uma nova réplica.
Repita o processo para ter pelo menos dois clusters PostgreSQL separados para configurar o Sharding, que é o próximo passo.
Como configurar a fragmentação do PostgreSQL?
Agora vamos configurar o Sharding usando o PostgreSQL Partitions e o Foreign Data Wrapper (FDW). Essa funcionalidade permite que o PostgreSQL acesse dados armazenados em outros servidores. É uma extensão disponível por padrão na instalação comum do PostgreSQL.
Usaremos o seguinte ambiente:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersPara habilitar a extensão FDW, basta executar o seguinte comando em seu servidor principal, neste caso, Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONAgora vamos criar a tabela clientes particionados por data cadastrada:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);E as seguintes partições:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Estas partições são locais. Agora vamos inserir alguns valores de teste e verificá-los:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Aqui você pode consultar a partição principal para ver todos os dados:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Ou mesmo consultar a partição correspondente:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Como você pode ver, os dados foram inseridos em diferentes partições, de acordo com a data cadastrada. Agora, no nó remoto, neste caso Shard2, vamos criar outra tabela:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Você precisa criar este servidor Shard2 no Shard1 desta forma:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');E o usuário para acessá-lo:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Agora, crie a FOREIGN TABLE em Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;E vamos inserir dados nesta nova tabela remota do Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Se tudo correu bem, você poderá acessar os dados de Shard1 e Shard2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Fragmento2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)É isso. Agora você está usando Sharding em seu cluster PostgreSQL.
Conclusão
Particionamento e fragmentação no PostgreSQL são bons recursos. Ele te ajuda caso você precise separar os dados em uma grande tabela para melhorar o desempenho, ou até mesmo limpar os dados de forma fácil, entre outras situações. Um ponto importante ao usar o Sharding é escolher uma boa chave de fragmentação que distribua os dados entre os nós da melhor maneira. Além disso, você pode usar o ClusterControl para simplificar a implantação do PostgreSQL e aproveitar alguns recursos como monitoramento, alerta, failover automático, backup, recuperação pontual e muito mais.