Este artigo é o terceiro de uma série sobre limites de otimização para agrupamento e agregação de dados. Na Parte 1, abordei o algoritmo Stream Aggregate pré-ordenado. Na Parte 2, abordei o algoritmo Sort + Stream Aggregate não pré-ordenado. Nesta parte, abordo o algoritmo Hash Match (Aggregate), ao qual me referirei simplesmente como Hash Aggregate. Também forneço um resumo e uma comparação entre os algoritmos que abordo na Parte 1, Parte 2 e Parte 3.
Usarei o mesmo banco de dados de exemplo chamado PerformanceV3, que usei nos artigos anteriores da série. Apenas certifique-se de que, antes de executar os exemplos no artigo, execute primeiro o código a seguir para descartar alguns índices desnecessários:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Os únicos dois índices que devem ser deixados nesta tabela são idx_cl_od (agrupados com orderdate como a chave) e PK_Orders (não agrupados com orderid como a chave).
Agregado de hash
O algoritmo Hash Aggregate organiza os grupos em uma tabela de hash com base em alguma função de hash escolhida internamente. Ao contrário do algoritmo Stream Aggregate, ele não precisa consumir as linhas em ordem de grupo. Considere a seguinte consulta (chamaremos de Consulta 1) como exemplo (forçando uma agregação de hash e um plano serial):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
A Figura 1 mostra o plano para a Consulta 1.
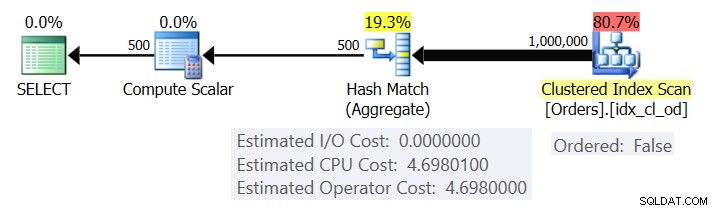
Figura 1:plano para consulta 1
O plano verifica as linhas do índice clusterizado usando uma propriedade Ordered:False (a verificação não é necessária para entregar as linhas ordenadas pela chave de índice). Normalmente, o otimizador preferirá varrer o índice de cobertura mais estreito, que no nosso caso é o índice clusterizado. O plano cria uma tabela de hash com as colunas agrupadas e as agregações. Nossa consulta solicita um agregado COUNT do tipo INT. O plano realmente o calcula como um valor do tipo BIGINT, daí o operador Compute Scalar, aplicando a conversão implícita para INT.
A Microsoft não compartilha publicamente os algoritmos de hash que eles usam. Esta é uma tecnologia muito proprietária. Ainda assim, para ilustrar o conceito, vamos supor que o SQL Server use a função hash % 250 (módulo 250) para nossa consulta acima. Antes de processar qualquer linha, nossa tabela de hash tem 250 buckets representando os 250 resultados possíveis da função de hash (0 a 249). À medida que o SQL Server processa cada linha, ele aplica a função de hash
orderid empid ------- ----- 320 3 30 5 660 253 820 3 850 1 1000 255 700 3 1240 253 350 4 400 255
A Figura 2 mostra três estados da tabela de hash:antes do processamento de qualquer linha, após o processamento das primeiras 5 linhas e após o processamento das primeiras 10 linhas. Cada item na lista encadeada contém a tupla (empid, COUNT(*)).
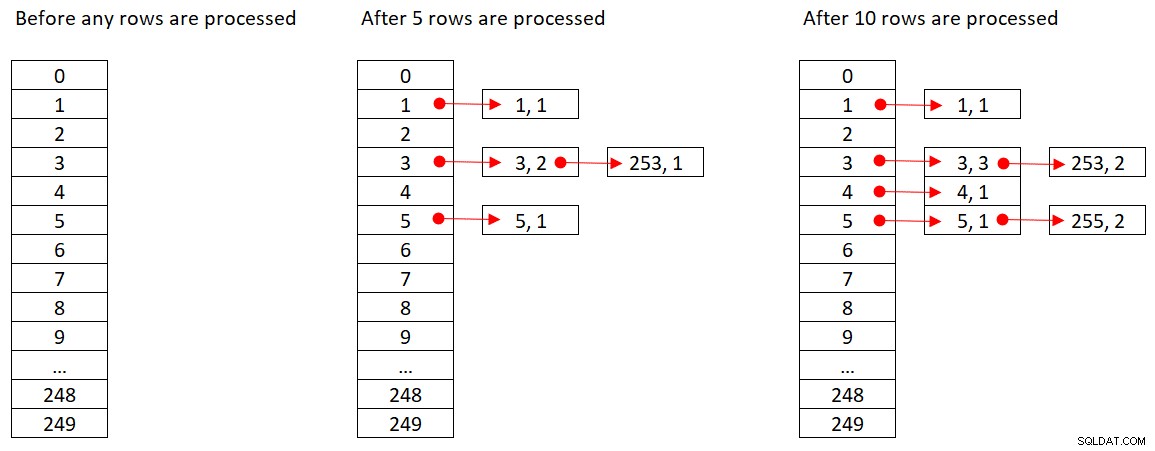
Figura 2:estados da tabela de hash
Assim que o operador Hash Aggregate terminar de consumir todas as linhas de entrada, a tabela de hash terá todos os grupos com o estado final da agregação.
Assim como o operador Sort, o operador Hash Aggregate requer uma concessão de memória e, se ficar sem memória, precisa ser derramado para tempdb; no entanto, enquanto a classificação requer uma concessão de memória proporcional ao número de linhas a serem classificadas, o hash requer uma concessão de memória proporcional ao número de grupos. Portanto, especialmente quando o conjunto de agrupamento tem alta densidade (pequeno número de grupos), esse algoritmo requer significativamente menos memória do que quando a classificação explícita é necessária.
Considere as duas consultas a seguir (chame-as de Consulta 1 e Consulta 2):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
A Figura 3 compara as concessões de memória para essas consultas.

Figura 3:planos para consulta 1 e consulta 2
Observe a grande diferença entre as concessões de memória nos dois casos.
Quanto ao custo do operador Hash Aggregate, voltando à Figura 1, observe que não há custo de E/S, apenas um custo de CPU. Em seguida, tente fazer a engenharia reversa da fórmula de custeio da CPU usando técnicas semelhantes às que abordei nas partes anteriores da série. Os fatores que podem afetar potencialmente o custo do operador são o número de linhas de entrada, o número de grupos de saída, a função agregada usada e o que você agrupa (cardinalidade do conjunto de agrupamento, tipos de dados usados).
Você esperaria que esse operador tivesse um custo inicial na preparação para construir a tabela de hash. Você também espera que ele seja dimensionado linearmente em relação ao número de linhas e grupos. Realmente foi isso que encontrei. No entanto, enquanto os custos dos operadores Stream Aggregate e Sort não são afetados pelo que você agrupa, parece que o custo do operador Hash Aggregate é, tanto em termos de cardinalidade do conjunto de agrupamento quanto dos tipos de dados usados.
Para observar que a cardinalidade do conjunto de agrupamento afeta o custo do operador, verifique os custos de CPU dos operadores Hash Aggregate nos planos para as seguintes consultas (chame-as de Consulta 3 e Consulta 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1);
Obviamente, você deseja garantir que o número estimado de linhas de entrada e grupos de saída seja o mesmo em ambos os casos. Os planos estimados para essas consultas são mostrados na Figura 4.
Figura 4:planos para consulta 3 e consulta 4
Como você pode ver, o custo de CPU do operador Hash Aggregate é 0,16903 ao agrupar por uma coluna inteira e 0,174016 ao agrupar por duas colunas inteiras, com todo o resto igual. Isso significa que a cardinalidade do conjunto de agrupamento realmente afeta o custo.
Quanto ao tipo de dados do elemento agrupado afetar o custo, usei as seguintes consultas para verificar isso (chame-as de Consulta 5, Consulta 6 e Consulta 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT)
OPTION(HASH GROUP, MAXDOP 1);
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY orderid % 1000
OPTION(HASH GROUP, MAXDOP 1);
SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT)
OPTION(HASH GROUP, MAXDOP 1); Os planos para todas as três consultas têm o mesmo número estimado de linhas de entrada e grupos de saída, mas todos obtêm custos estimados de CPU diferentes (0,121766, 0,16903 e 0,171716), portanto, o tipo de dados usado afeta o custo.
O tipo de função agregada também parece ter impacto no custo. Por exemplo, considere as duas consultas a seguir (chame-as de Consulta 8 e Consulta 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
O custo estimado da CPU para o Hash Aggregate no plano da Consulta 8 é 0,166344 e na Consulta 9 é 0,16903.
Pode ser um exercício interessante tentar descobrir exatamente de que maneira a cardinalidade do conjunto de agrupamento, os tipos de dados e a função agregada usada afetam o custo; Eu simplesmente não busquei esse aspecto do custo. Assim, depois de escolher o conjunto de agrupamento e a função agregada para sua consulta, você pode fazer engenharia reversa da fórmula de custeio. Por exemplo, vamos fazer a engenharia reversa da fórmula de custeio da CPU para o operador Hash Aggregate ao agrupar por uma única coluna inteira e retornar o agregado MAX(orderdate). A fórmula deve ser:
Custo de CPU do operador =
Usando as técnicas que demonstrei nos artigos anteriores da série, obtive a seguinte fórmula de engenharia reversa:
Custo da CPU do operador =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087
Você pode verificar a precisão da fórmula usando as seguintes consultas:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Obtenho os seguintes resultados:
numrows numgroups predictedcost estimatedcost ----------- ----------- -------------- -------------- 100000 1000 0.703315 0.703316 100000 2000 0.721023 0.721024 200000 3000 1.40659 1.40659 200000 6000 1.45972 1.45972 500000 5000 3.44558 3.44558 500000 10000 3.53412 3.53412
A fórmula parece acertada.
Resumo e comparação de custos
Agora temos as fórmulas de custeio para as três estratégias disponíveis:Stream Aggregate pré-ordenado, Sort + Stream Aggregate e Hash Aggregate. A tabela a seguir resume e compara as características de custeio dos três algoritmos:
| Agregado de stream encomendado | Classificar + Agregar stream | Agregado de hash | |
| Fórmula | @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,0112613 + Número pequeno de linhas: 9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06 Grande número de linhas: 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06 + @numrows * 0,0000006 + @numgrupos * 0,0000005 | 0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087 * Agrupamento por coluna de inteiro único, retornando MAX( |
| Escalonamento | linear | n log n | linear |
| Custo de E/S de inicialização | nenhum | 0,0112613 | nenhum |
| Custo da CPU de inicialização | nenhum | ~ 0,0001 | 0,017749 |
De acordo com essas fórmulas, a Figura 5 mostra a maneira como cada uma das estratégias é dimensionada para diferentes números de linhas de entrada, usando um número fixo de grupos de 500 como exemplo.
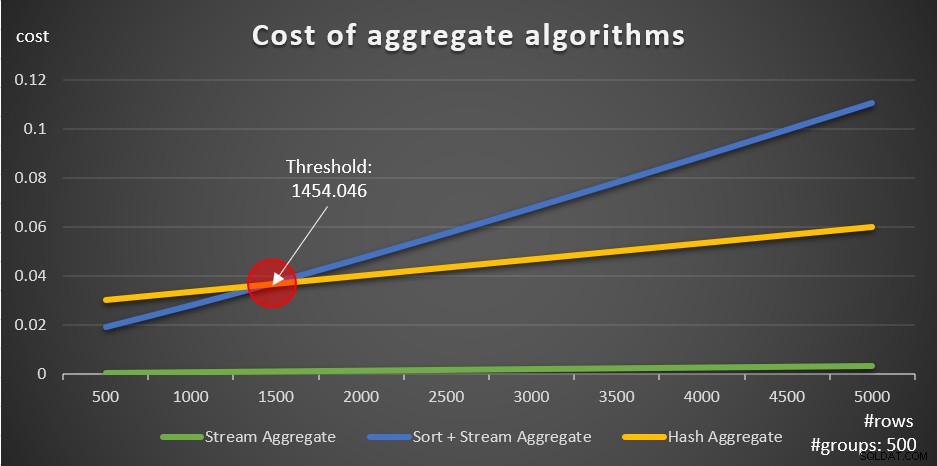
Figura 5:Custo de algoritmos agregados
Você pode ver claramente que, se os dados forem pré-ordenados, por exemplo, em um índice de cobertura, a estratégia Stream Aggregate pré-ordenada é a melhor opção, independentemente de quantas linhas estejam envolvidas. Por exemplo, suponha que você precise consultar a tabela Pedidos e calcular a data máxima do pedido para cada funcionário. Você cria o seguinte índice de cobertura:
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);
Aqui estão cinco consultas, emulando uma tabela Orders com diferentes números de linhas (10.000, 20.000, 30.000, 40.000 e 50.000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
A Figura 6 mostra os planos para essas consultas.
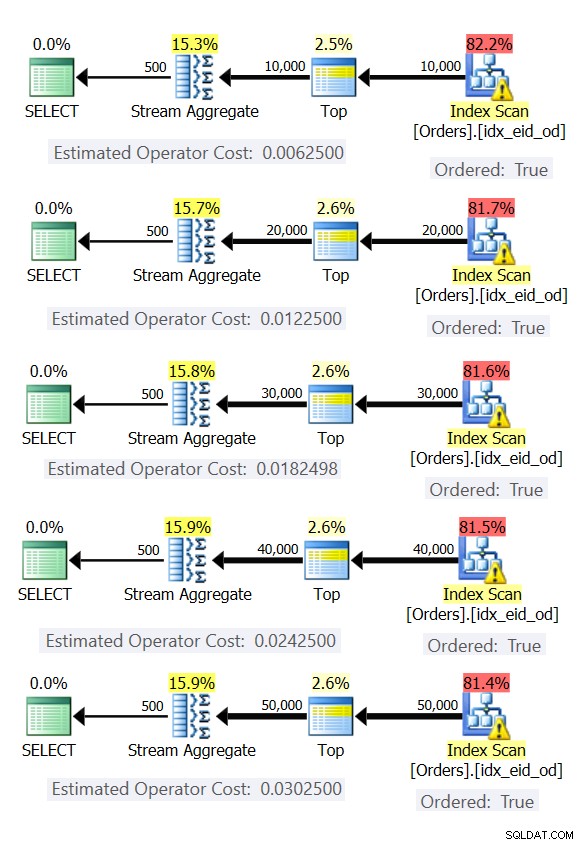
Figura 6:planos com estratégia de Stream Aggregate pré-ordenada
Em todos os casos, os planos executam uma varredura ordenada do índice de cobertura e aplicam o operador Stream Aggregate sem a necessidade de classificação explícita.
Use o código a seguir para descartar o índice que você criou para este exemplo:
DROP INDEX idx_eid_od ON dbo.Orders;
A outra coisa importante a ser observada sobre os gráficos da Figura 5 é o que acontece quando os dados não são pré-ordenados. Isso acontece quando não há índice de cobertura no local, bem como quando você agrupa por expressões manipuladas em vez de colunas de base. Há um limite de otimização - em nosso caso, 1.454.046 linhas - abaixo do qual a estratégia Sort + Stream Aggregate tem um custo menor e acima ou acima do qual a estratégia Hash Aggregate tem um custo menor. Isso tem a ver com o fato de que o primeiro tem um custo inicial menor, mas escala de maneira n log n, enquanto o último tem um custo inicial mais alto, mas escala linearmente. Isso torna o primeiro preferido com um pequeno número de linhas de entrada. Se nossas fórmulas de engenharia reversa forem precisas, as duas consultas a seguir (chamadas de Consulta 10 e Consulta 11) devem ter planos diferentes:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Os planos para essas consultas são mostrados na Figura 7.
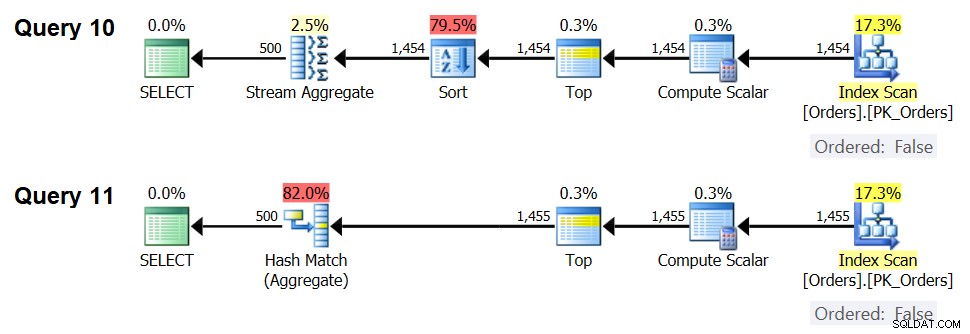
Figura 7:planos para consulta 10 e consulta 11
De fato, com 1.454 linhas de entrada (abaixo do limite de otimização), o otimizador naturalmente prefere o algoritmo Sort + Stream Aggregate para a consulta 10 e, com 1.455 linhas de entrada (acima do limite de otimização), o otimizador naturalmente prefere o algoritmo Hash Aggregate para a consulta 11 .
Potencial para o operador Adaptive Aggregate
Um dos aspectos complicados dos limites de otimização são os problemas de detecção de parâmetros ao usar consultas sensíveis a parâmetros em procedimentos armazenados. Considere o seguinte procedimento armazenado como um exemplo:
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INT AS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= @initialorderid GROUP BY empid; GO
Você cria o seguinte índice ideal para dar suporte à consulta de procedimento armazenado:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
Você criou o índice com orderid como a chave para dar suporte ao filtro de intervalo da consulta e incluiu empid para cobertura. Essa é uma situação em que você não pode realmente criar um índice que dê suporte ao filtro de intervalo e tenha as linhas filtradas pré-ordenadas pelo conjunto de agrupamento. Isso significa que o otimizador terá que escolher entre os algoritmos Sort + stream Aggregate e Hash Aggregate. Com base em nossas fórmulas de custo, o limite de otimização está entre 937 e 938 linhas de entrada (digamos, 937,5 linhas).
Suponha que você execute o procedimento armazenado pela primeira vez com um ID de pedido inicial de entrada que fornece um pequeno número de correspondências (abaixo do limite):
EXEC dbo.EmpOrders @initialorderid = 999991;
O SQL Server produz um plano que usa o algoritmo Sort + Stream Aggregate e armazena em cache o plano. As execuções subsequentes reutilizam o plano armazenado em cache, independentemente de quantas linhas estejam envolvidas. Por exemplo, a execução a seguir tem várias correspondências acima do limite de otimização:
EXEC dbo.EmpOrders @initialorderid = 990001;
Ainda assim, ele reutiliza o plano em cache, apesar de não ser o ideal para essa execução. Esse é um problema clássico de sniffing de parâmetros.
O SQL Server 2017 apresenta recursos de processamento de consulta adaptável, projetados para lidar com essas situações, determinando durante a execução da consulta qual estratégia empregar. Entre essas melhorias está um operador Adaptive Join que durante a execução determina se deve ativar um algoritmo de Loop ou Hash com base em um limite de otimização calculado. Nossa história agregada implora por um operador Adaptive Aggregate semelhante, que durante a execução faria uma escolha entre uma estratégia Sort + Stream Aggregate e uma estratégia Hash Aggregate, com base em um limite de otimização calculado. A Figura 8 ilustra um pseudoplano baseado nessa ideia.
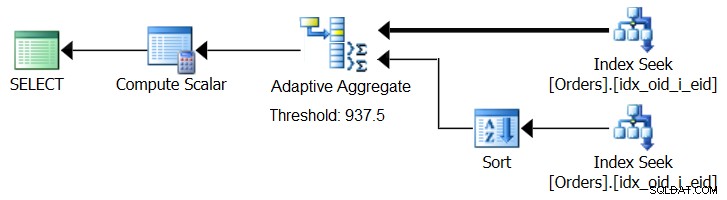
Figura 8:Pseudoplano com operador Adaptive Aggregate
Por enquanto, para obter esse plano, você precisa usar o Microsoft Paint. Mas como o conceito de processamento de consulta adaptável é tão inteligente e funciona tão bem, é razoável esperar ver mais melhorias nessa área no futuro.
Execute o seguinte código para descartar o índice que você criou para este exemplo:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
Conclusão
Neste artigo, abordei o custo e o dimensionamento do algoritmo Hash Aggregate e o comparei com as estratégias Stream Aggregate e Sort + Stream Aggregate. Descrevi o limite de otimização que existe entre as estratégias Sort + Stream Aggregate e Hash Aggregate. Com números pequenos de linhas de entrada, o primeiro é preferido e com números grandes, o último. Também descrevi o potencial para adicionar um operador Adaptive Aggregate, semelhante ao operador Adaptive Join já implementado, para ajudar a lidar com problemas de detecção de parâmetros ao usar consultas sensíveis a parâmetros. No próximo mês, continuarei a discussão abordando considerações de paralelismo e casos que exigem reescritas de consulta.



