Não é ótimo ter uma nova versão do SQL Server disponível? Isso é algo que só acontece a cada dois anos, e este mês vimos um deles atingir a Disponibilidade Geral. (Ok, eu sei que temos uma nova versão do Banco de Dados SQL no Azure quase continuamente, mas considero isso diferente.) Reconhecendo este novo lançamento, o T-SQL Tuesday deste mês (organizado por Michael Swart – @mjswart) é sobre o assunto do SQL Server 2016!
Não é ótimo ter uma nova versão do SQL Server disponível? Isso é algo que só acontece a cada dois anos, e este mês vimos um deles atingir a Disponibilidade Geral. (Ok, eu sei que temos uma nova versão do Banco de Dados SQL no Azure quase continuamente, mas considero isso diferente.) Reconhecendo este novo lançamento, o T-SQL Tuesday deste mês (organizado por Michael Swart – @mjswart) é sobre o assunto do SQL Server 2016! Então, hoje eu quero ver o recurso de Tabelas Temporais do SQL 2016 e dar uma olhada em algumas situações de plano de consulta que você pode acabar vendo. Eu amo Tabelas Temporais, mas me deparei com uma pegadinha que você pode querer estar ciente.
Agora, apesar do SQL Server 2016 estar agora em RTM, estou usando o AdventureWorks2016CTP3, que você pode baixar aqui – mas não basta baixar
AdventureWorks2016CTP3.bak , também pegue SQLServer2016CTP3Samples.zip do mesmo sítio. Veja, no arquivo Samples, existem alguns scripts úteis para experimentar novos recursos, incluindo alguns para Tabelas Temporais. É ganha-ganha – você pode experimentar um monte de novos recursos, e eu não preciso repetir tanto script neste post. De qualquer forma, vá e pegue os dois scripts sobre Tabelas Temporais, executando
AW 2016 CTP3 Temporal Setup.sql , seguido por Temporal System-Versioning Sample.sql . Esses scripts configuram versões temporais de algumas tabelas, incluindo
HumanResources.Employee . Ele cria HumanResources.Employee_Temporal (embora, tecnicamente, pudesse ser chamado de qualquer coisa). No final do CREATE TABLE declaração, este bit aparece, adicionando duas colunas ocultas para usar para indicar quando a linha é válida e indicando que uma tabela deve ser criada chamada HumanResources.Employee_Temporal_History para armazenar as versões antigas. ... ValidFrom datetime2(7) GERADO SEMPRE COMO ROW START HIDDEN NOT NULL, ValidTo datetime2(7) GENERATED SEMPRE COMO ROW END HIDDEN NOT NULL, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo)) WITH (SYSTEM_VERSIONING =ON (HISTORY_TABLE) =[Recursos Humanos].[Employee_Temporal_History]));
O que quero explorar neste post é o que acontece com os planos de consulta quando o histórico é usado.
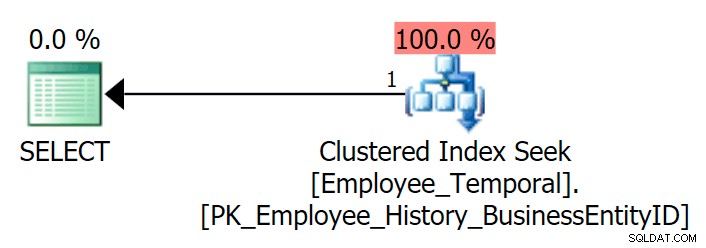
Se eu consultar a tabela para ver a linha mais recente de um determinado
BusinessEntityID , recebo um Clustered Index Seek, conforme o esperado. SELECT e.BusinessEntityID, e.ValidFrom, e.ValidToFROM HumanResources.Employee_Temporal AS eWHERE e.BusinessEntityID =4;
Tenho certeza de que poderia consultar essa tabela usando outros índices, se tivesse algum. Mas neste caso, não. Vamos criar um.
CRIAR ÍNDICE ÚNICO rf_ix_Login em HumanResources.Employee_Temporal(LoginID);
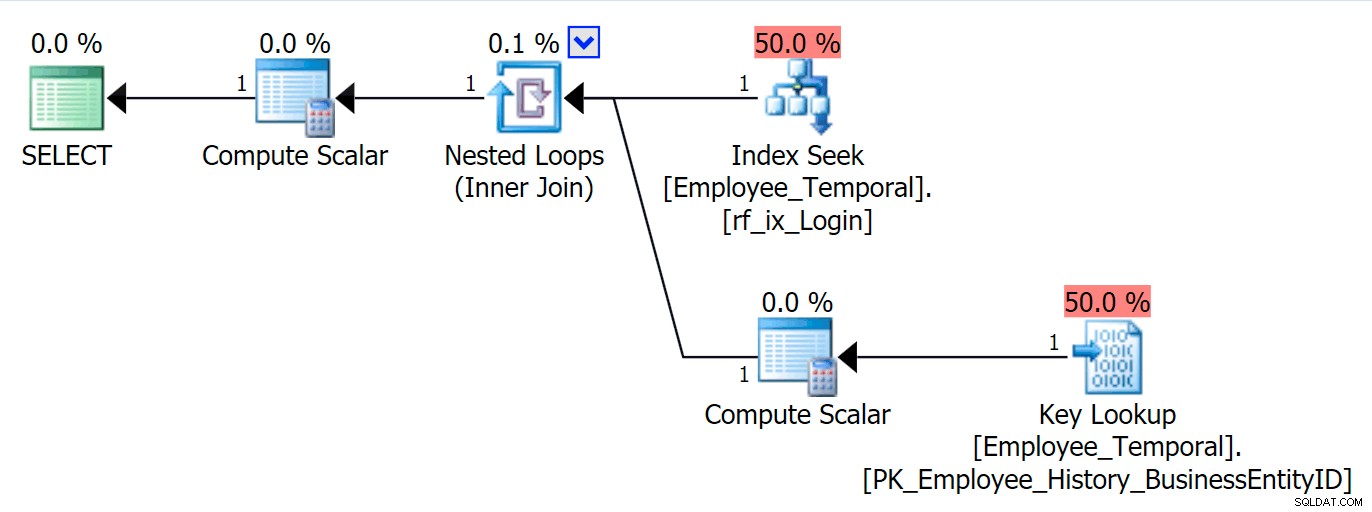
Agora posso consultar a tabela por
LoginID , e verá uma pesquisa de chave se eu solicitar colunas diferentes de Loginid ou BusinessEntityID . Nada disso é surpreendente. SELECT * FROM HumanResources.Employee_Temporal eWHERE e.LoginID =N'adventure-works\rob0';
Vamos usar o SQL Server Management Studio por um minuto e dar uma olhada na aparência dessa tabela no Pesquisador de Objetos.

Podemos ver a tabela de histórico mencionada em
HumanResources.Employee_Temporal , e as colunas e índices da própria tabela e da tabela de histórico. Mas enquanto os índices na tabela apropriada são a Chave Primária (em BusinessEntityID ) e o índice que acabei de criar, a tabela History não possui índices correspondentes. O índice na tabela de histórico está em
ValidTo e ValidFrom . Podemos clicar com o botão direito do mouse no índice e selecionar Propriedades, e vemos esta caixa de diálogo: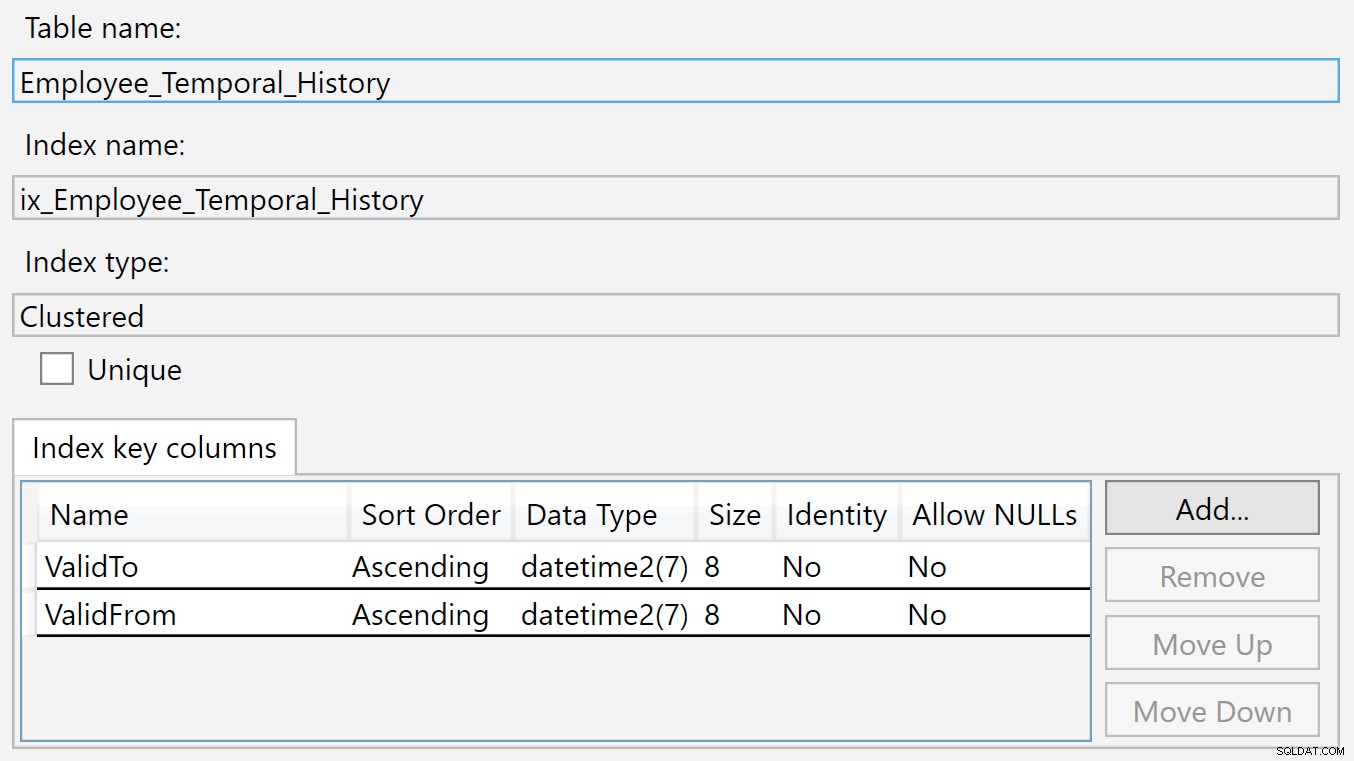
Uma nova linha é inserida nesta tabela de Histórico quando não é mais válida na tabela principal, pois acabou de ser excluída ou alterada. Os valores no
ValidTo coluna são naturalmente preenchidas com a hora atual, então ValidTo atua como uma chave ascendente, como uma coluna de identidade, para que novas inserções apareçam no final da estrutura b-tree. Mas como isso funciona quando você deseja consultar a tabela?
Se quisermos consultar nossa tabela para saber o que estava atual em um determinado momento, devemos usar uma estrutura de consulta como:
SELECT * FROM HumanResources.Employee_TemporalFOR SYSTEM_TIME AS OF '20160612 11:22';
Essa consulta precisa concatenar as linhas apropriadas da tabela principal com as linhas apropriadas da tabela de histórico.
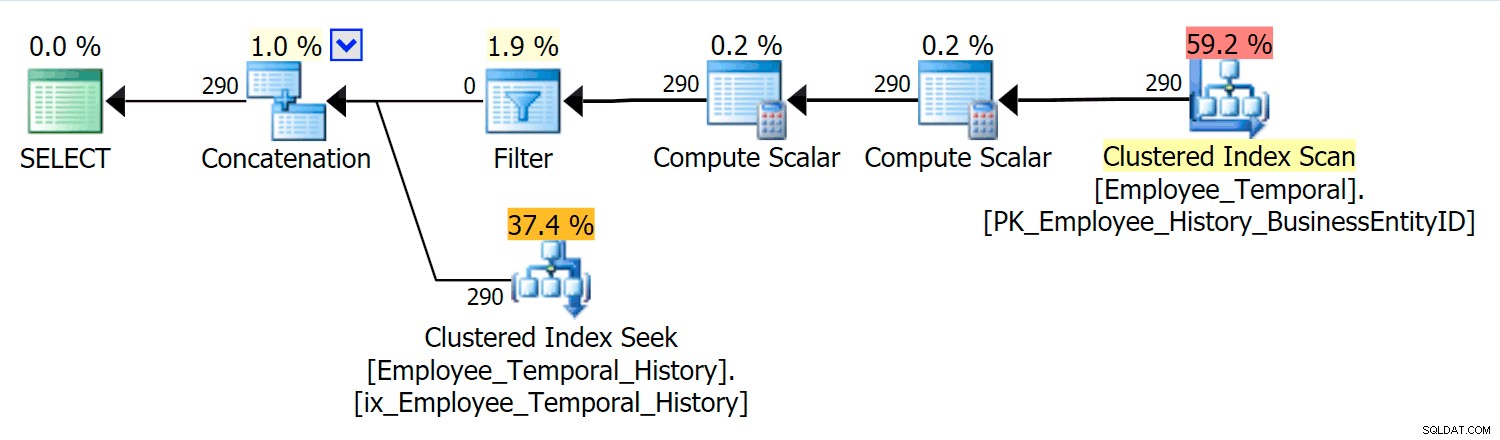
Nesse cenário, as linhas que eram válidas no momento que eu escolhi eram todas da tabela de histórico, mas mesmo assim, vemos uma Verificação de Índice Agrupado na tabela principal, que foi filtrada por um operador Filtro. O predicado deste filtro é:
[HumanResources].[Employee_Temporal].[ValidFrom] <='2016-06-12 11:22:00.0000000' E [HumanResources].[Employee_Temporal].[ValidTo]> '2016-06-12 11:22 :00.0000000'
Vamos revisitar isso em um momento.
A Busca de Índice Agrupado na tabela Histórico deve claramente estar aproveitando um Predicado de Busca em ValidTo. O início da varredura de alcance da busca é
HumanResources.Employee_Temporal_History.ValidTo > Operador escalar('2016-06-12 11:22:00') , mas não há End, porque cada linha que tem um ValidTo após o tempo que nos interessa é uma linha candidata e deve ser testada para um ValidFrom apropriado valor pelo Predicado Residual, que é HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' . Agora, os intervalos são difíceis de indexar; isso é uma coisa conhecida que tem sido discutida em muitos blogs. As soluções mais eficazes consideram maneiras criativas de escrever consultas, mas nenhuma dessas inteligências foi incorporada às Tabelas Temporais. Você pode, no entanto, colocar índices em outras colunas também, como em ValidFrom, ou até mesmo ter índices que correspondam aos tipos de consultas que você pode ter na tabela principal. Com um índice clusterizado sendo uma chave composta em ambos
ValidTo e ValidFrom , essas duas colunas são incluídas em todas as outras colunas, oferecendo uma boa oportunidade para alguns testes de Predicado Residual. Se eu souber em qual loginid estou interessado, meu plano terá uma forma diferente.
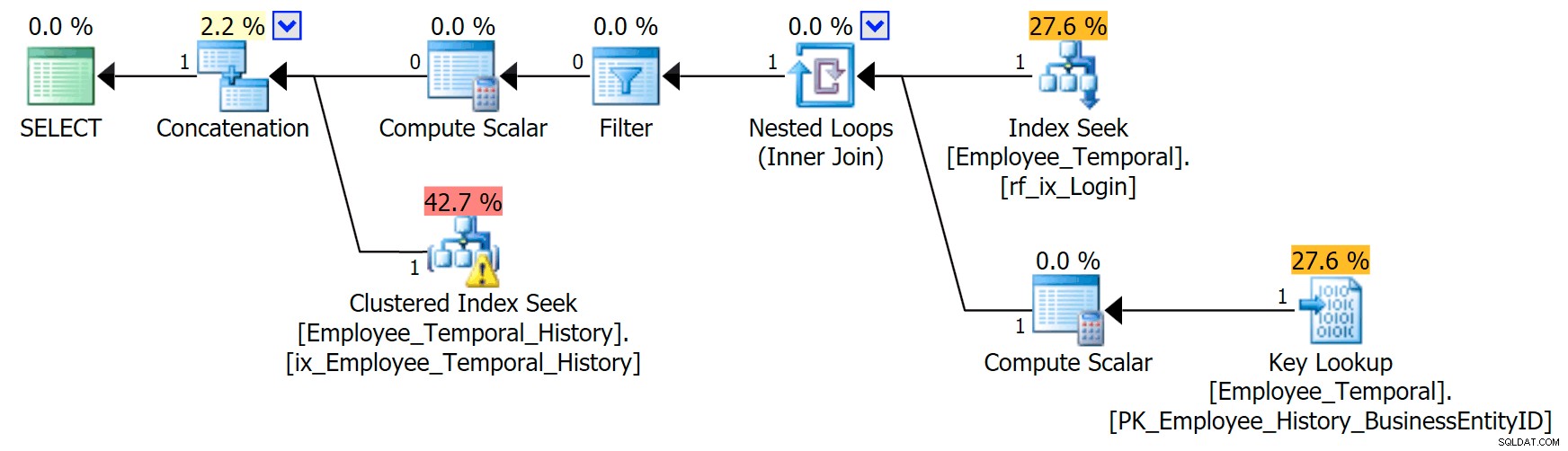
A ramificação superior do operador Concatenação é semelhante à anterior, embora o operador Filtro tenha entrado na briga para remover todas as linhas que não são válidas, mas a Busca de Índice Agrupado na ramificação inferior tem um Aviso. Este é um aviso de Predicado Residual, como os exemplos em um post anterior meu. Ele é capaz de filtrar as entradas que são válidas até algum ponto após o tempo que nos interessa, mas o Predicado Residual agora filtra para o
LoginID bem como ValidFrom . [HumanResources].[Employee_Temporal_History].[ValidFrom] <='2016-06-12 11:22:00.0000000' E [HumanResources].[Employee_Temporal_History].[LoginID] =N'adventure-works\rob0'
As alterações nas linhas de rob0 serão uma pequena proporção das linhas no Histórico. Esta coluna não será única como na tabela principal, porque a linha pode ter sido alterada várias vezes, mas ainda há um bom candidato para indexação.
CRIAR ÍNDICE rf_ixHist_loginidON HumanResources.Employee_Temporal_History(LoginID);
Este novo índice tem um efeito notável em nosso plano.
Agora, nossa busca de índice clusterizado mudou para uma verificação de índice clusterizado!!
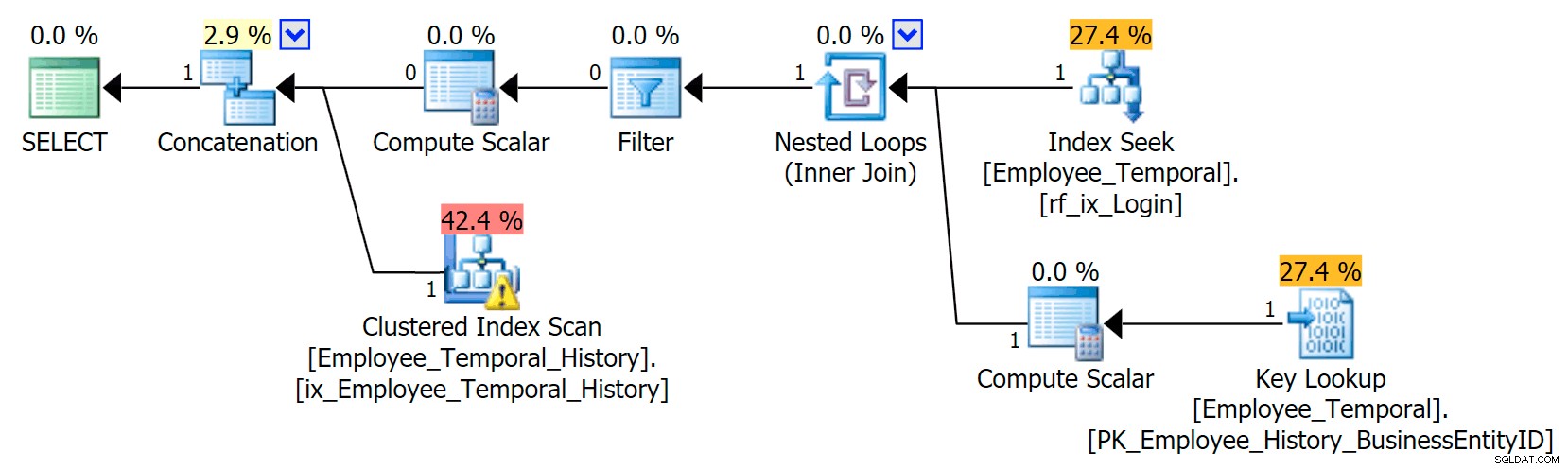
Você vê, o Otimizador de Consulta agora descobre que a melhor coisa a fazer seria usar o novo índice. Mas também decide que o esforço de ter que fazer pesquisas para obter todas as outras colunas (porque eu estava pedindo todas as colunas) seria simplesmente muito trabalho. O ponto de inflexão foi alcançado (infelizmente, uma suposição incorreta neste caso) e um SCAN de índice agrupado foi escolhido. Mesmo sem o índice não clusterizado, a melhor opção teria sido usar uma Busca de Índice Clusterizado, quando o índice não clusterizado foi considerado e rejeitado por motivos de ponto de inflexão, ele escolhe fazer a varredura.
Frustrantemente, acabei de criar este índice e suas estatísticas devem ser boas. Ele deve saber que um Seek que requer exatamente uma pesquisa deve ser melhor do que um Clustered Index Scan (somente por estatísticas - se você estava pensando que deveria saber isso porqueLoginIDé único na tabela principal, lembre-se que nem sempre foi). Portanto, suspeito que as pesquisas devam ser evitadas nas tabelas de histórico, embora ainda não tenha feito pesquisas suficientes sobre isso.
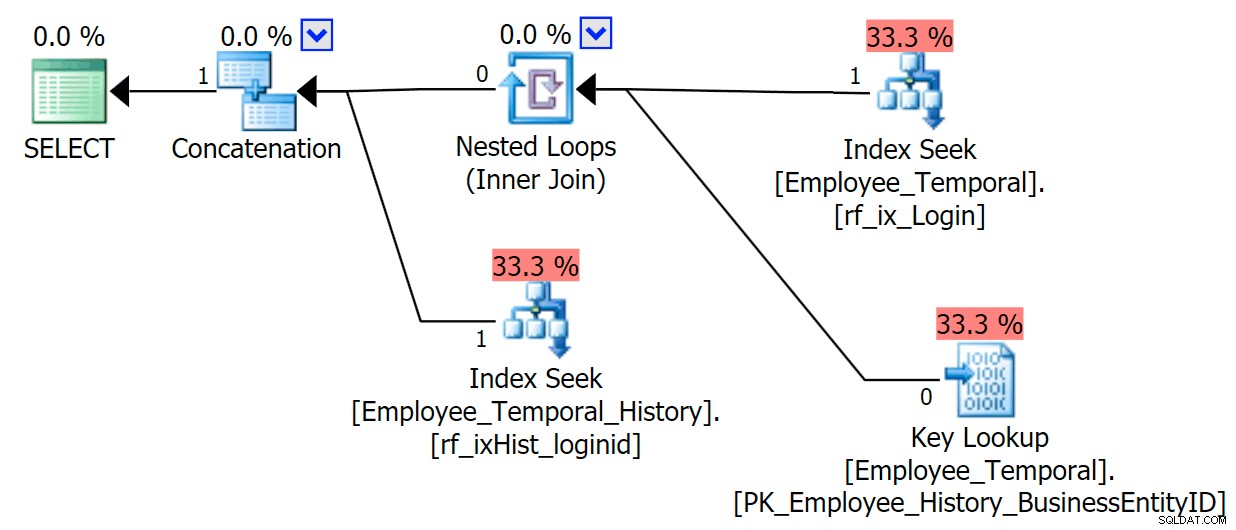
Agora, se formos consultar apenas as colunas que aparecem em nosso índice não clusterizado, obteremos um comportamento muito melhor. Agora que nenhuma pesquisa é necessária, nosso novo índice na tabela de histórico é usado com satisfação. Ele ainda precisa aplicar um Predicado Residual baseado apenas em poder filtrar paraLoginIDeValidTo, mas ele se comporta muito melhor do que cair em um Clustered Index Scan.
SELECT LoginID, ValidFrom, ValidToFROM HumanResources.Employee_TemporalFOR SYSTEM_TIME AS OF '20160612 11:22'WHERE LoginID =N'adventure-works\rob0'
Portanto, indexe suas tabelas de histórico de maneiras extras, considerando como você as consultará. Inclua as colunas necessárias para evitar pesquisas, pois você está realmente evitando Scans.
Essas tabelas de histórico podem ficar grandes se os dados forem alterados com frequência. Portanto, fique atento à forma como eles estão sendo tratados. Esta mesma situação ocorre ao usar o outroFOR SYSTEM_TIMEconstruções, então você deve (como sempre) revisar os planos que suas consultas estão produzindo e indexar para ter certeza de que está bem posicionado para aproveitar o que é um recurso muito poderoso do SQL Server 2016.