Muitas vezes, quando escrevemos um procedimento armazenado, queremos que ele se comporte de maneiras diferentes com base na entrada do usuário. Vejamos o seguinte exemplo:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Esse procedimento armazenado, que criei no banco de dados AdventureWorks2017, tem dois parâmetros:@CustomerID e @SortOrder. O primeiro parâmetro, @CustomerID, afeta as linhas a serem retornadas. Se um ID de cliente específico for passado para o procedimento armazenado, ele retornará todos os pedidos (10 principais) para esse cliente. Caso contrário, se for NULL, o procedimento armazenado retornará todos os pedidos (10 principais), independentemente do cliente. O segundo parâmetro, @SortOrder, determina como os dados serão classificados — por OrderDate ou por SalesOrderID. Observe que apenas as primeiras 10 linhas serão retornadas de acordo com a ordem de classificação.
Assim, os usuários podem afetar o comportamento da consulta de duas maneiras:quais linhas retornar e como classificá-las. Para ser mais preciso, existem 4 comportamentos diferentes para esta consulta:
- Retornar as 10 principais linhas de todos os clientes classificados por OrderDate (o comportamento padrão)
- Retornar as 10 principais linhas de um cliente específico classificado por OrderDate
- Retornar as 10 principais linhas de todos os clientes classificados por SalesOrderID
- Retornar as 10 principais linhas de um cliente específico classificado por SalesOrderID
Vamos testar o procedimento armazenado com todas as 4 opções e examinar o plano de execução e as estatísticas de E/S.
Retorne as 10 principais linhas de todos os clientes classificados por OrderDate
Segue o código para executar o procedimento armazenado:
EXECUTE Sales.GetOrders; GO
Segue o plano de execução:
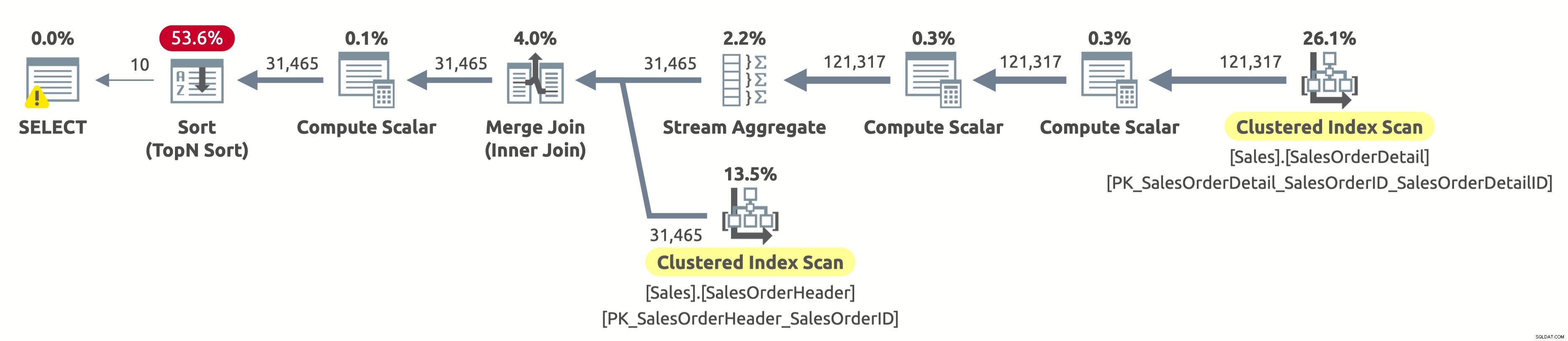
Como não filtramos por cliente, precisamos varrer toda a tabela. O otimizador optou por verificar ambas as tabelas usando índices em SalesOrderID, o que permitiu um Stream Aggregate eficiente, bem como um Merge Join eficiente.
Se você verificar as propriedades do operador Clustered Index Scan na tabela Sales.SalesOrderHeader, encontrará o seguinte predicado:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[ @CustomerID] OU [@CustomerID] É NULO. O processador de consultas precisa avaliar esse predicado para cada linha da tabela, o que não é muito eficiente porque sempre será avaliado como verdadeiro.
Ainda precisamos classificar todos os dados por OrderDate para retornar as 10 primeiras linhas. Se houvesse um índice em OrderDate, o otimizador provavelmente o teria usado para verificar apenas as 10 primeiras linhas de Sales.SalesOrderHeader, mas não existe tal índice, então o plano parece bom considerando os índices disponíveis.
Aqui está a saída das estatísticas IO:
- Tabela 'SalesOrderHeader'. Contagem de varredura 1, leituras lógicas 689
- Tabela 'Detalhes do pedido de vendas'. Contagem de varredura 1, leituras lógicas 1248
Se você está perguntando por que há um aviso no operador SELECT, então é um aviso de concessão excessiva. Nesse caso, não é porque há um problema no plano de execução, mas porque o processador de consultas solicitou 1.024 KB (que é o mínimo por padrão) e usou apenas 16 KB.
Às vezes, planejar o cache não é uma boa ideia
Em seguida, queremos testar o cenário de retorno das 10 principais linhas de um cliente específico classificado por OrderDate. Abaixo segue o código:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
O plano de execução é exatamente o mesmo de antes. Desta vez, o plano é muito ineficiente porque varre as duas tabelas apenas para retornar 3 pedidos. Existem maneiras muito melhores de executar essa consulta.
A razão, neste caso, é o cache do plano. O plano de execução foi gerado na primeira execução com base nos valores de parâmetro nessa execução específica - um método conhecido como sniffing de parâmetro. Esse plano foi armazenado no cache do plano para reutilização e, a partir de agora, todas as chamadas para esse procedimento armazenado reutilizarão o mesmo plano.
Este é um exemplo em que o cache do plano não é uma boa ideia. Devido à natureza desse procedimento armazenado, que possui 4 comportamentos diferentes, esperamos obter um plano diferente para cada comportamento. Mas estamos presos a um único plano, que serve apenas para uma das 4 opções, com base na opção usada na primeira execução.
Vamos desabilitar o cache do plano para este procedimento armazenado, apenas para que possamos ver o melhor plano que o otimizador pode criar para cada um dos outros 3 comportamentos. Faremos isso adicionando WITH RECOMPILE ao comando EXECUTE.
Retorne as 10 principais linhas de um cliente específico classificadas por OrderDate
Veja a seguir o código para retornar as 10 principais linhas de um cliente específico classificado por OrderDate:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Segue o plano de execução:
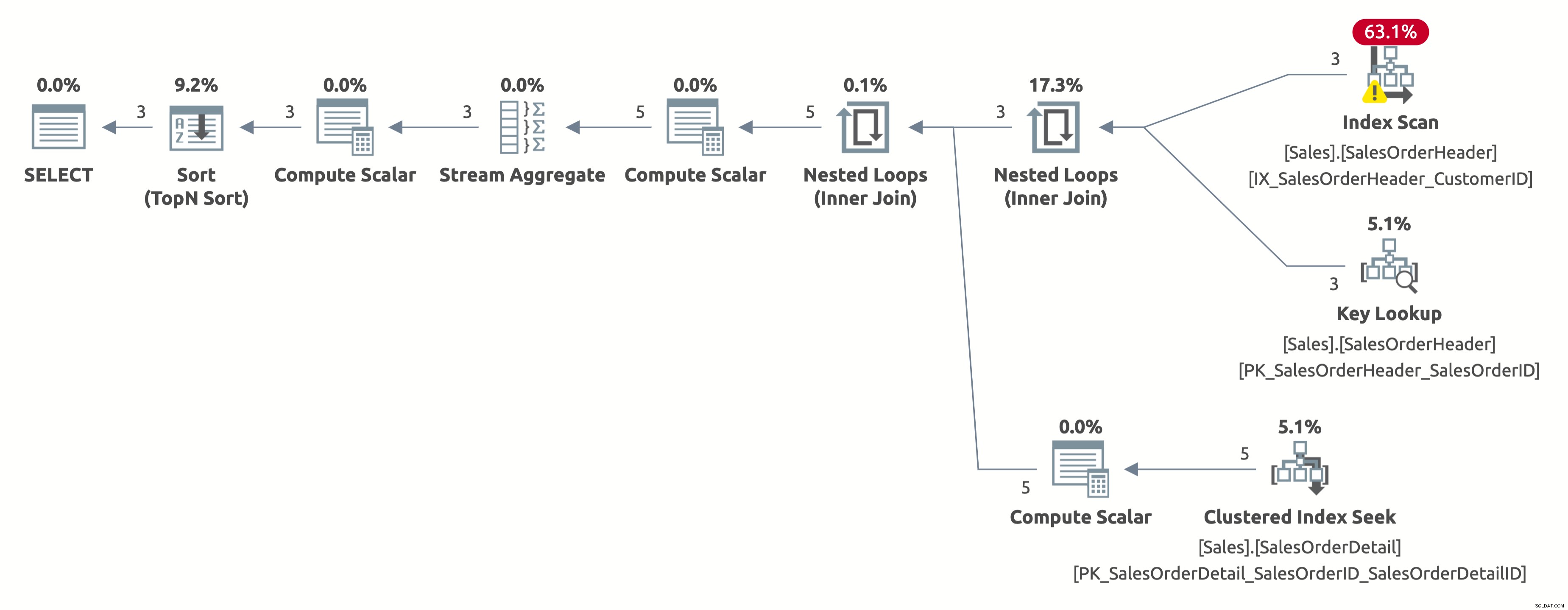
Desta vez, temos um plano melhor, que usa um índice no CustomerID. O otimizador estima corretamente 2,6 linhas para CustomerID =11006 (o número real é 3). Mas observe que ele executa uma varredura de índice em vez de uma busca de índice. Ele não pode realizar uma busca de índice porque precisa avaliar o seguinte predicado para cada linha na tabela:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[@CustomerID ] OU [@CustomerID] É NULO.
Aqui está a saída das estatísticas IO:
- Tabela 'Detalhes do pedido de vendas'. Contagem de varredura 3, leituras lógicas 9
- Tabela 'SalesOrderHeader'. Contagem de varredura 1, leituras lógicas 66
Retorne as 10 principais linhas de todos os clientes classificados por SalesOrderID
Veja a seguir o código para retornar as 10 principais linhas de todos os clientes classificados por SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Segue o plano de execução:
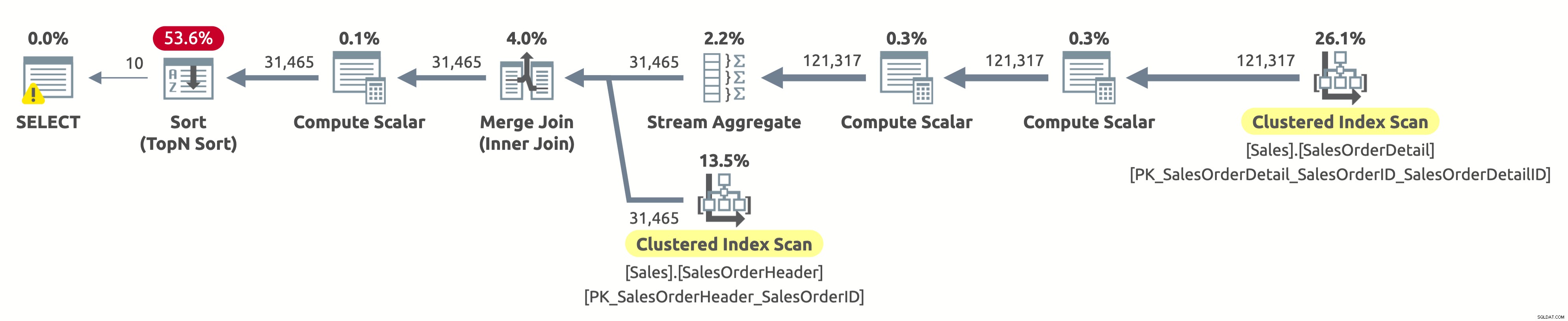
Ei, este é o mesmo plano de execução da primeira opção. Mas desta vez, algo está errado. Já sabemos que os índices clusterizados em ambas as tabelas são classificados por SalesOrderID. Também sabemos que o plano verifica ambos na ordem lógica para manter a ordem de classificação (a propriedade Ordered é definida como True). O operador Merge Join também mantém a ordem de classificação. Como agora estamos pedindo para classificar o resultado por SalesOrderID, e ele já está classificado dessa maneira, por que temos que pagar por um operador Sort caro?
Bem, se você verificar o operador Sort, notará que ele ordena os dados de acordo com Expr1004. E, se você verificar o operador Compute Scalar à direita do operador Sort, descobrirá que Expr1004 é o seguinte:

Não é uma visão bonita, eu sei. Esta é a expressão que temos na cláusula ORDER BY da nossa consulta. O problema é que o otimizador não pode avaliar essa expressão em tempo de compilação, portanto, ele precisa calculá-la para cada linha em tempo de execução e, em seguida, classificar todo o conjunto de registros com base nisso.
A saída das estatísticas IO é como na primeira execução:
- Tabela 'SalesOrderHeader'. Contagem de varredura 1, leituras lógicas 689
- Tabela 'Detalhes do pedido de vendas'. Contagem de varredura 1, leituras lógicas 1248
Retorne as 10 principais linhas de um cliente específico classificado por SalesOrderID
Veja a seguir o código para retornar as 10 principais linhas de um cliente específico classificado por SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
O plano de execução é o mesmo da segunda opção (retorne as 10 principais linhas de um cliente específico classificado por OrderDate). O plano tem os mesmos dois problemas, que já mencionamos. O primeiro problema é executar uma varredura de índice em vez de uma busca de índice devido à expressão na cláusula WHERE. O segundo problema é realizar uma classificação cara devido à expressão na cláusula ORDER BY.
Então, o que devemos fazer?
Vamos nos lembrar primeiro com o que estamos lidando. Temos parâmetros, que determinam a estrutura da consulta. Para cada combinação de valores de parâmetro, obtemos uma estrutura de consulta diferente. No caso do parâmetro @CustomerID, os dois comportamentos diferentes são NULL ou NOT NULL e afetam a cláusula WHERE. No caso do parâmetro @SortOrder, existem dois valores possíveis e eles afetam a cláusula ORDER BY. O resultado são 4 estruturas de consulta possíveis, e gostaríamos de obter um plano diferente para cada uma.
Então temos dois problemas distintos. O primeiro é o cache do plano. Existe apenas um único plano para o procedimento armazenado e ele será gerado com base nos valores dos parâmetros na primeira execução. O segundo problema é que mesmo quando um novo plano é gerado, ele não é eficiente porque o otimizador não pode avaliar as expressões "dinâmicas" na cláusula WHERE e na cláusula ORDER BY em tempo de compilação.
Podemos tentar resolver esses problemas de várias maneiras:
- Use uma série de instruções IF-ELSE
- Divida o procedimento em procedimentos armazenados separados
- Usar OPÇÃO (RECOMPILAR)
- Gere a consulta dinamicamente
Use uma série de declarações IF-ELSE
A ideia é simples:em vez das expressões "dinâmicas" na cláusula WHERE e na cláusula ORDER BY, podemos dividir a execução em 4 ramificações usando instruções IF-ELSE - uma ramificação para cada comportamento possível.
Por exemplo, o seguinte é o código para a primeira ramificação:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Essa abordagem pode ajudar a gerar planos melhores, mas tem algumas limitações.
Primeiro, o procedimento armazenado se torna bastante longo e é mais difícil escrever, ler e manter. E isso é quando temos apenas dois parâmetros. Se tivéssemos 3 parâmetros, teríamos 8 ramos. Imagine que você precisa adicionar uma coluna à cláusula SELECT. Você teria que adicionar a coluna em 8 consultas diferentes. Torna-se um pesadelo de manutenção, com alto risco de erro humano.
Em segundo lugar, ainda temos o problema de cache de planos e sniffing de parâmetros até certo ponto. Isso porque na primeira execução, o otimizador vai gerar um plano para todas as 4 consultas com base nos valores dos parâmetros dessa execução. Digamos que a primeira execução usará os valores padrão para os parâmetros. Especificamente, o valor de @CustomerID será NULL. Todas as consultas serão otimizadas com base nesse valor, incluindo a consulta com a cláusula WHERE (SalesOrders.CustomerID =@CustomerID). O otimizador estimará 0 linhas para essas consultas. Agora, digamos que a segunda execução usará um valor não nulo para @CustomerID. O plano em cache, que estima 0 linhas, será usado, mesmo que o cliente tenha muitos pedidos na tabela.
Divida o procedimento em procedimentos armazenados separados
Em vez de 4 ramificações dentro do mesmo procedimento armazenado, podemos criar 4 procedimentos armazenados separados, cada um com os parâmetros relevantes e a consulta correspondente. Em seguida, podemos reescrever o aplicativo para decidir qual procedimento armazenado executar de acordo com os comportamentos desejados. Ou, se quisermos que seja transparente para o aplicativo, podemos reescrever o procedimento armazenado original para decidir qual procedimento executar com base nos valores dos parâmetros. Vamos usar as mesmas instruções IF-ELSE, mas em vez de executar uma consulta em cada ramificação, executaremos um procedimento armazenado separado.
A vantagem é que resolvemos o problema de cache de plano porque cada procedimento armazenado agora tem seu próprio plano, e o plano para cada procedimento armazenado será gerado em sua primeira execução com base na detecção de parâmetros.
Mas ainda temos o problema de manutenção. Algumas pessoas podem dizer que agora é ainda pior, porque precisamos manter vários procedimentos armazenados. Novamente, se aumentarmos o número de parâmetros para 3, acabaríamos com 8 procedimentos armazenados distintos.
Usar OPÇÃO (RECOMPILAR)
OPÇÃO (RECOMPILAR) funciona como mágica. Você só precisa dizer as palavras (ou anexá-las à consulta) e a mágica acontece. Realmente, ele resolve muitos problemas porque compila a consulta em tempo de execução e faz isso para todas as execuções.
Mas você deve ter cuidado porque sabe o que dizem:"Com grandes poderes vêm grandes responsabilidades". Se você usar OPTION (RECOMPILE) em uma consulta que é executada com muita frequência em um sistema OLTP ocupado, poderá matar o sistema porque o servidor precisa compilar e gerar um novo plano em cada execução, usando muitos recursos da CPU. Isso é realmente perigoso. No entanto, se a consulta for executada apenas de vez em quando, digamos uma vez a cada poucos minutos, provavelmente é seguro. Mas sempre teste o impacto em seu ambiente específico.
No nosso caso, supondo que podemos usar OPTION (RECOMPILE) com segurança, tudo o que precisamos fazer é adicionar as palavras mágicas no final de nossa consulta, conforme mostrado abaixo:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Agora, vamos ver a magia em ação. Por exemplo, o seguinte é o plano para o segundo comportamento:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
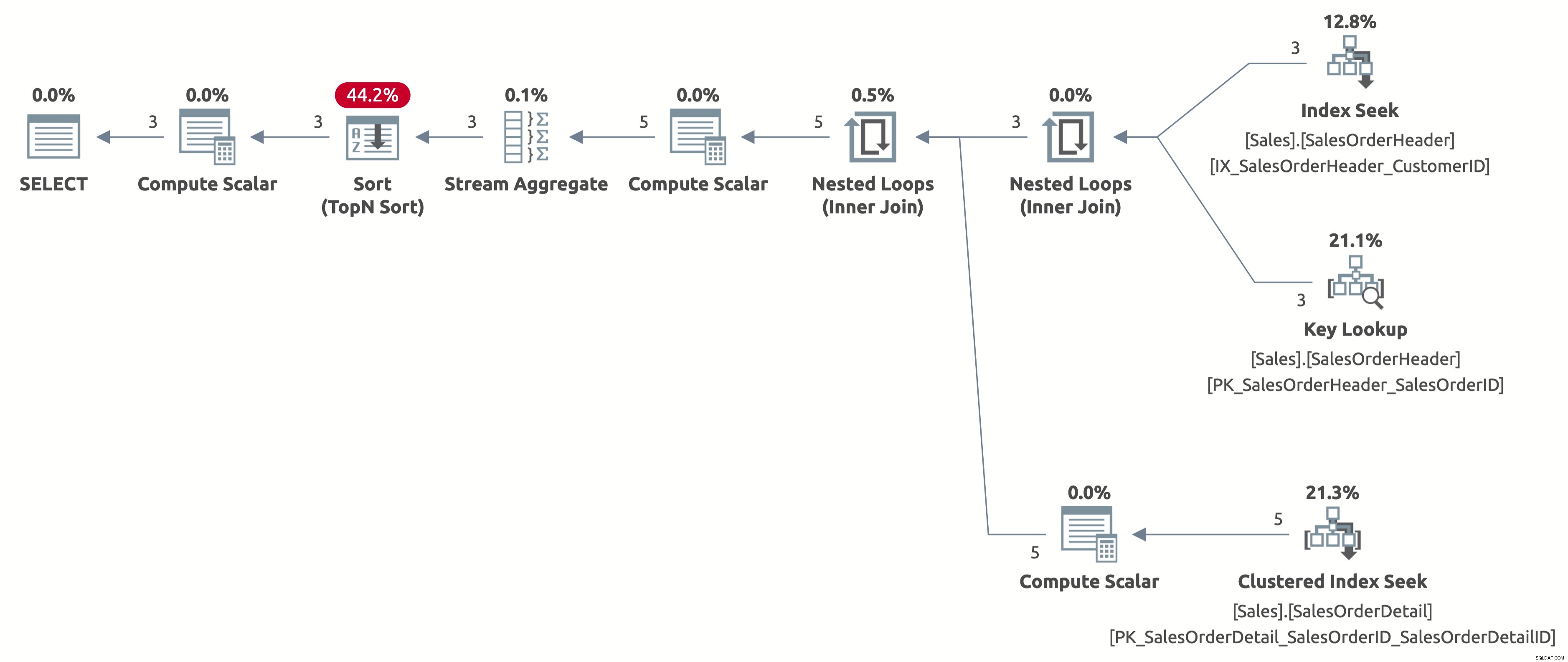
Agora obtemos uma busca de índice eficiente com uma estimativa correta de 2,6 linhas. Ainda precisamos classificar por OrderDate, mas agora a classificação é feita diretamente por Order Date e não precisamos mais calcular a expressão CASE na cláusula ORDER BY. Este é o melhor plano possível para este comportamento de consulta com base nos índices disponíveis.
Aqui está a saída das estatísticas IO:
- Tabela 'Detalhes do pedido de vendas'. Contagem de varredura 3, leituras lógicas 9
- Tabela 'SalesOrderHeader'. Contagem de varredura 1, leituras lógicas 11
A razão pela qual OPTION (RECOMPILE) é tão eficiente neste caso é que resolve exatamente os dois problemas que temos aqui. Lembre-se de que o primeiro problema é o cache do plano. OPTION (RECOMPILE) elimina esse problema completamente porque recompila a consulta sempre. O segundo problema é a incapacidade do otimizador de avaliar a expressão complexa na cláusula WHERE e na cláusula ORDER BY em tempo de compilação. Como OPTION (RECOMPILE) acontece em tempo de execução, ele resolve o problema. Porque em tempo de execução, o otimizador tem muito mais informações em relação ao tempo de compilação, e isso faz toda a diferença.
Agora, vamos ver o que acontece quando tentamos o terceiro comportamento:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
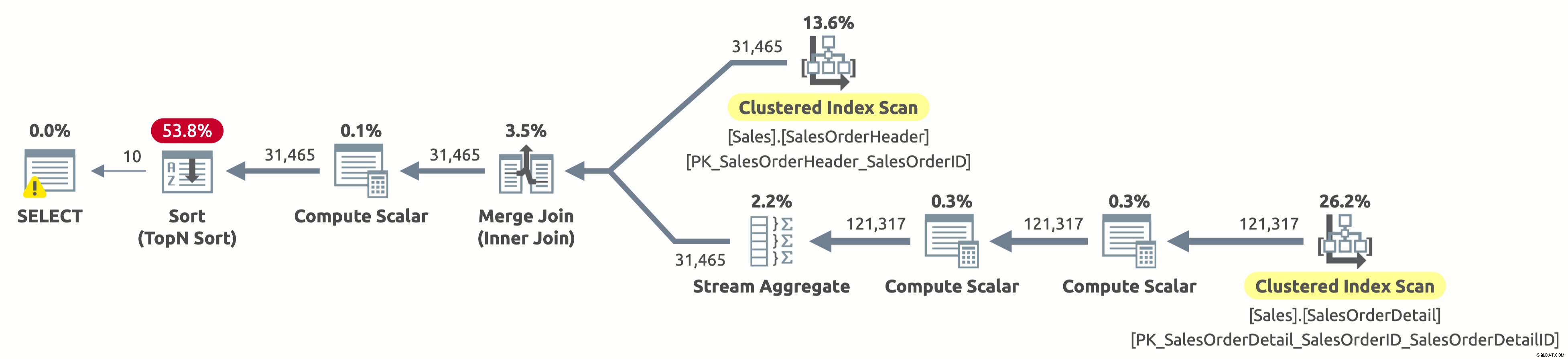
Houston, nós temos um problema. O plano ainda verifica ambas as tabelas inteiramente e, em seguida, classifica tudo, em vez de verificar apenas as primeiras 10 linhas de Sales.SalesOrderHeader e evitar a classificação completamente. O que aconteceu?
Este é um "caso" interessante e tem a ver com a expressão CASE na cláusula ORDER BY. A expressão CASE avalia uma lista de condições e retorna uma das expressões de resultado. Mas as expressões de resultado podem ter diferentes tipos de dados. Então, qual seria o tipo de dados de toda a expressão CASE? Bem, a expressão CASE sempre retorna o tipo de dados de maior precedência. No nosso caso, a coluna OrderDate tem o tipo de dados DATETIME, enquanto a coluna SalesOrderID tem o tipo de dados INT. O tipo de dados DATETIME tem uma precedência mais alta, portanto, a expressão CASE sempre retorna DATETIME.
Isso significa que, se quisermos classificar por SalesOrderID, a expressão CASE precisa primeiro converter implicitamente o valor de SalesOrderID em DATETIME para cada linha antes de classificá-la. Veja o operador Compute Scalar à direita do operador Sort no plano acima? É exatamente isso que faz.
Este é um problema por si só e demonstra o quão perigoso pode ser misturar diferentes tipos de dados em uma única expressão CASE.
Podemos contornar esse problema reescrevendo a cláusula ORDER BY de outras maneiras, mas isso tornaria o código ainda mais feio e difícil de ler e manter. Então, não vou nessa direção.
Em vez disso, vamos tentar o próximo método…
Gerar a consulta dinamicamente
Como nosso objetivo é gerar 4 estruturas de consulta diferentes em uma única consulta, o SQL dinâmico pode ser muito útil nesse caso. A ideia é construir a consulta dinamicamente com base nos valores dos parâmetros. Dessa forma, podemos construir as 4 estruturas de consulta diferentes em um único código, sem precisar manter 4 cópias da consulta. Cada estrutura de consulta compilará uma vez, quando for executada pela primeira vez, e obterá o melhor plano porque não contém nenhuma expressão complexa.
Esta solução é muito semelhante à solução com os vários procedimentos armazenados, mas em vez de manter 8 procedimentos armazenados para 3 parâmetros, mantemos apenas um único código que constrói a consulta dinamicamente.
Eu sei, o SQL dinâmico também é feio e às vezes pode ser bastante difícil de manter, mas acho que ainda é mais fácil do que manter vários procedimentos armazenados e não aumenta exponencialmente à medida que o número de parâmetros aumenta.
Segue o código:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Observe que ainda uso um parâmetro interno para o ID do cliente e executo o código dinâmico usando
sys.sp_executesql para passar o valor do parâmetro. Isto é importante por duas razões. Primeiro, para evitar várias compilações da mesma estrutura de consulta para valores diferentes de @CustomerID. Segundo, para evitar injeção de SQL. Se você tentar executar o procedimento armazenado agora usando valores de parâmetro diferentes, verá que cada comportamento de consulta ou estrutura de consulta obtém o melhor plano de execução, e cada um dos 4 planos é compilado apenas uma vez.
Como exemplo, o seguinte é o plano para o terceiro comportamento:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
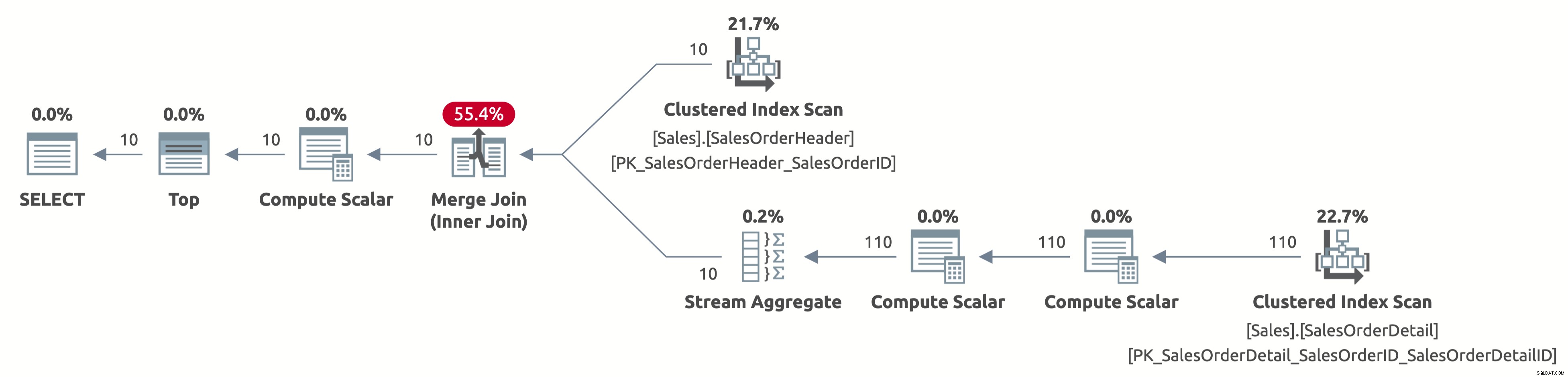
Agora, verificamos apenas as primeiras 10 linhas da tabela Sales.SalesOrderHeader e também verificamos apenas as primeiras 110 linhas da tabela Sales.SalesOrderDetail. Além disso, não há operador Sort porque os dados já estão classificados por SalesOrderID.
Aqui está a saída das estatísticas IO:
- Tabela 'Detalhes do pedido de vendas'. Contagem de varredura 1, leituras lógicas 4
- Tabela 'SalesOrderHeader'. Contagem de varredura 1, leituras lógicas 3
Conclusão
Ao usar parâmetros para alterar a estrutura de sua consulta, não use expressões complexas na consulta para derivar o comportamento esperado. Na maioria dos casos, isso levará a um desempenho ruim e por boas razões. A primeira razão é que o plano será gerado com base na primeira execução e, em seguida, todas as execuções subsequentes reutilizarão o mesmo plano, que é apropriado apenas para uma estrutura de consulta. A segunda razão é que o otimizador é limitado em sua capacidade de avaliar essas expressões complexas em tempo de compilação.
Existem várias maneiras de superar esses problemas, e nós as examinamos neste artigo. Na maioria dos casos, o melhor método seria construir a consulta dinamicamente com base nos valores dos parâmetros. Dessa forma, cada estrutura de consulta será compilada uma vez com o melhor plano possível.
Ao construir a consulta usando SQL dinâmico, certifique-se de usar parâmetros onde apropriado e verifique se seu código é seguro.



