Tenha uma visão geral dos mecanismos disponíveis para fazer backup de dados armazenados no Apache HBase e como restaurar esses dados no caso de vários cenários de recuperação/failover de dados
Com o aumento da adoção e integração do HBase em sistemas críticos de negócios, muitas empresas precisam proteger esse importante ativo de negócios criando estratégias robustas de backup e recuperação de desastres (BDR) para seus clusters HBase. Por mais assustador que possa parecer fazer backup e restaurar com rapidez e facilidade potencialmente petabytes de dados, o HBase e o ecossistema Apache Hadoop fornecem muitos mecanismos integrados para fazer exatamente isso.
Neste post, você terá uma visão geral de alto nível dos mecanismos disponíveis para fazer backup de dados armazenados no HBase e como restaurar esses dados no caso de vários cenários de recuperação/failover de dados. Depois de ler este post, você deve ser capaz de tomar uma decisão informada sobre qual estratégia de BDR é melhor para suas necessidades de negócios. Você também deve entender os prós, contras e implicações de desempenho de cada mecanismo. (Os detalhes aqui se aplicam ao CDH 4.3.0/HBase 0.94.6 e posterior.)
Observação:no momento da redação deste artigo, o Cloudera Enterprise 4 oferece backup pronto para produção e funcionalidade de recuperação de desastres para HDFS e Hive Metastore via Cloudera BDR 1.0 como um recurso licenciado individualmente. HBase não está incluído nessa versão GA; portanto, os vários mecanismos descritos neste blog são necessários. (Cloudera Enterprise 5, atualmente em versão beta, oferece gerenciamento de snapshots HBase via Cloudera BDR.)
Backup
O HBase é um armazenamento de dados distribuído de árvore de mesclagem estruturado em log com mecanismos internos complexos para garantir a precisão dos dados, consistência, controle de versão e assim por diante. Então, como você pode obter uma cópia de backup consistente desses dados que residem em uma combinação de HFiles e Write-Ahead-Logs (WALs) no HDFS e na memória em dezenas de servidores regionais?
Vamos começar com o menos disruptivo, o menor volume de dados, o mecanismo de menor impacto no desempenho e trabalhar até a ferramenta mais disruptiva do estilo empilhadeira:
- Fotos
- Replicação
- Exportar
- Copiar tabela
- API HTable
- Backup offline de dados HDFS
A tabela a seguir fornece uma visão geral para comparar rapidamente essas abordagens, que descreverei em detalhes abaixo.
| Impacto no desempenho | Pegada de dados | Tempo de inatividade | Backups incrementais | Facilidade de implementação | Tempo médio para recuperação (MTTR) | |
| Instantâneos | Mínimo | Pequeno | Breve (Somente na Restauração) | Não | Fácil | Segundos |
| Replicação | Mínimo | Grande | Nenhum | Intrínseco | Médio | Segundos |
| Exportar | Alto | Grande | Nenhum | Sim | Fácil | Alto |
| CopiarTabela | Alto | Grande | Nenhum | Sim | Fácil | Alto |
| API | Médio | Grande | Nenhum | Sim | Difícil | Até você |
| Manual | N/A | Grande | Longo | Não | Médio | Alto |
Fotos
A partir do CDH 4.3.0, os snapshots do HBase são totalmente funcionais, ricos em recursos e não requerem tempo de inatividade do cluster durante sua criação. Meu colega Matteo Bertozzi cobriu muito bem os instantâneos em sua entrada no blog e mergulhou mais fundo. Aqui vou fornecer apenas uma visão geral de alto nível.
Os instantâneos simplesmente capturam um momento da sua tabela criando o equivalente dos links físicos do UNIX para os arquivos de armazenamento da sua tabela no HDFS (Figura 1). Esses instantâneos são concluídos em segundos, quase não sobrecarregam o desempenho do cluster e criam um volume de dados minúsculo. Seus dados não são duplicados, mas meramente catalogados em pequenos arquivos de metadados, o que permite que o sistema retorne a esse momento caso você precise restaurar esse instantâneo.
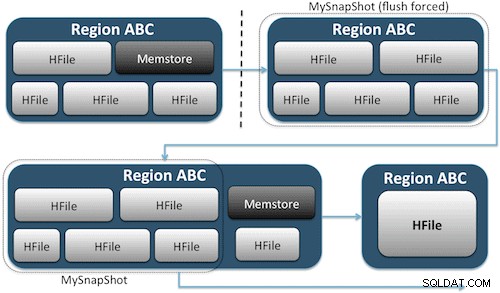
Criar um instantâneo de uma tabela é tão simples quanto executar este comando no shell do HBase:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Após emitir este comando, você encontrará alguns pequenos arquivos de dados localizados em /hbase/.snapshot/myTable (CDH4) ou /hbase/.hbase-snapshots (Apache 0.94.6.1) no HDFS que contêm as informações necessárias para restaurar seu instantâneo . Restaurar é tão simples quanto emitir estes comandos do shell:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Observação:como você pode ver, a restauração de um instantâneo requer uma breve interrupção, pois a tabela deve estar offline. Quaisquer dados adicionados/atualizados após a captura do instantâneo restaurado serão perdidos.
Se seus requisitos de negócios são tais que você deve ter um backup externo de seus dados, você pode utilizar o comando exportSnapshot para duplicar os dados de uma tabela em seu cluster HDFS local ou um cluster HDFS remoto de sua escolha.
Os instantâneos são uma imagem completa da sua mesa a cada vez; nenhuma funcionalidade de instantâneo incremental está disponível no momento.
Replicação HBase
A replicação do HBase é outra ferramenta de backup com sobrecarga muito baixa. (Meu colega Himanshu Vashishtha aborda a replicação em detalhes nesta postagem do blog.) Em resumo, a replicação pode ser definida no nível da família de colunas, funciona em segundo plano e mantém todas as edições sincronizadas entre os clusters na cadeia de replicação.
A replicação tem três modos:mestre->escravo, mestre<->mestre e cíclico. Essa abordagem oferece flexibilidade para ingerir dados de qualquer datacenter e garante que eles sejam replicados em todas as cópias dessa tabela em outros datacenters. No caso de uma interrupção catastrófica em um data center, os aplicativos cliente podem ser redirecionados para um local alternativo para os dados utilizando ferramentas de DNS.
A replicação é um processo robusto e tolerante a falhas que fornece “consistência eventual”, o que significa que, a qualquer momento, as edições recentes de uma tabela podem não estar disponíveis em todas as réplicas dessa tabela, mas com certeza chegarão lá.
Observação:para tabelas existentes, você deve primeiro copiar manualmente a tabela de origem para a tabela de destino por meio de um dos outros meios descritos neste post. A replicação só atua em novas gravações/edições depois que você a habilita.

(Da página de replicação do Apache)
Exportar
A ferramenta Export do HBase é um utilitário HBase integrado que permite a exportação fácil de dados de uma tabela HBase para SequenceFiles simples em um diretório HDFS. Ele cria um trabalho MapReduce que faz uma série de chamadas de API do HBase para seu cluster e, uma a uma, obtém cada linha de dados da tabela especificada e grava esses dados no diretório HDFS especificado. Essa ferramenta é mais intensiva em desempenho para seu cluster porque utiliza MapReduce e a API do cliente HBase, mas é rica em recursos e suporta a filtragem de dados por versão ou intervalo de datas, permitindo assim backups incrementais.
Aqui está uma amostra do comando em sua forma mais simples:
hbase org.apache.hadoop.hbase.mapreduce.Export
Depois que sua tabela for exportada, você poderá copiar os arquivos de dados resultantes para qualquer lugar que desejar (como armazenamento externo/fora do cluster). Você também pode especificar um cluster/diretório HDFS remoto como o local de saída do comando, e Export gravará diretamente o conteúdo no cluster remoto. Observe que essa abordagem introduzirá um elemento de rede no caminho de gravação da exportação, portanto, você deve confirmar que sua conexão de rede com o cluster remoto é confiável e rápida.
Copiar tabela
O utilitário CopyTable é bem abordado na entrada do blog de Jon Hsieh, mas vou resumir o básico aqui. Semelhante ao Export, CopyTable cria um trabalho MapReduce que utiliza a API do HBase para ler uma tabela de origem. A principal diferença é que CopyTable grava sua saída diretamente em uma tabela de destino no HBase, que pode ser local em seu cluster de origem ou em um cluster remoto.
Um exemplo da forma mais simples do comando é:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Este comando copiará o conteúdo de uma tabela chamada “test” para uma tabela no mesmo cluster chamada “testCopy”.
Observe que há uma sobrecarga de desempenho significativa para CopyTable, pois ele usa “puts” individuais para gravar os dados, linha por linha, na tabela de destino. Se sua tabela for muito grande, CopyTable pode fazer com que o memstore nos servidores da região de destino fique cheio, exigindo liberações de memstore que eventualmente levarão a compactações, coleta de lixo e assim por diante.
Além disso, você deve levar em consideração as implicações de desempenho da execução do MapReduce sobre o HBase. Com grandes conjuntos de dados, essa abordagem pode não ser ideal.
API HTable (como um aplicativo Java personalizado)
Como sempre acontece com o Hadoop, você sempre pode escrever seu próprio aplicativo personalizado que utiliza a API pública e consulta a tabela diretamente. Você pode fazer isso por meio de trabalhos MapReduce para utilizar as vantagens de processamento em lote distribuído dessa estrutura ou por qualquer outro meio de seu próprio design. No entanto, essa abordagem requer uma compreensão profunda do desenvolvimento do Hadoop e de todas as APIs e implicações de desempenho de usá-las em seu cluster de produção.
Backup off-line de dados HDFS brutos
O mecanismo de backup de força bruta – também o mais disruptivo – envolve a maior pegada de dados. Você pode desligar seu cluster HBase e copiar manualmente todos os dados e estruturas de diretório que residem em /hbase em seu cluster HDFS. Como o HBase está inativo, isso garantirá que todos os dados sejam mantidos no HFiles no HDFS e você obterá uma cópia precisa dos dados. No entanto, será quase impossível obter backups incrementais, pois você não poderá verificar quais dados foram alterados ou adicionados ao tentar backups futuros.
Também é importante observar que a restauração de seus dados exigiria um meta-reparo offline porque o arquivo .META. tabela conteria informações potencialmente inválidas no momento da restauração. Essa abordagem também requer uma rede rápida e confiável para transferir os dados para fora do local e restaurá-los posteriormente, se necessário.
Por esses motivos, a Cloudera desencoraja fortemente essa abordagem para backups do HBase.
Recuperação de desastres
O HBase foi projetado para ser um sistema distribuído extremamente tolerante a falhas com redundância nativa, assumindo que o hardware falhará com frequência. A recuperação de desastres no HBase geralmente vem de várias formas:
- Falha catastrófica no nível do data center, exigindo failover para um local de backup
- Necessidade de restaurar uma cópia anterior de seus dados devido a erro do usuário ou exclusão acidental
- A capacidade de restaurar uma cópia pontual de seus dados para fins de auditoria
Como em qualquer plano de recuperação de desastres, os requisitos de negócios determinarão como o plano é arquitetado e quanto dinheiro investir nele. Depois de estabelecer os backups de sua escolha, a restauração assume diferentes formas, dependendo do tipo de recuperação necessário:
- Failover para cluster de backup
- Importar tabela/restaurar um instantâneo
- Aponte o diretório raiz do HBase para o local de backup
Se sua estratégia de backup for tal que você replicou seus dados do HBase para um cluster de backup em um data center diferente, o failover é tão fácil quanto apontar seus aplicativos de usuário final para o cluster de backup com técnicas de DNS.
No entanto, lembre-se de que, se você planeja permitir que os dados sejam gravados no cluster de backup durante o período de interrupção, será necessário garantir que os dados retornem ao cluster primário quando a interrupção terminar. A replicação mestre a mestre ou cíclica tratará desse processo automaticamente para você, mas um esquema de replicação mestre-escravo deixará seu cluster mestre fora de sincronia, exigindo intervenção manual após a interrupção.
Junto com o recurso de exportação descrito anteriormente, há uma ferramenta de importação correspondente que pode recuperar os dados previamente copiados pelo Export e restaurá-los em uma tabela HBase. As mesmas implicações de desempenho aplicadas ao Export também estão em jogo com o Import. Se o seu esquema de backup envolveu a captura de instantâneos, reverter para uma cópia anterior de seus dados é tão simples quanto restaurar esse instantâneo.
Você também pode se recuperar de um desastre simplesmente modificando a propriedade hbase.root.dir em hbase-site.xml e apontando-a para uma cópia de backup do seu diretório /hbase se você tiver feito a cópia offline de força bruta das estruturas de dados HDFS . No entanto, essa também é a menos desejável das opções de restauração, pois requer uma interrupção estendida enquanto você copia toda a estrutura de dados de volta para o cluster de produção e, como mencionado anteriormente, .META. pode estar fora de sincronia.
Conclusão
Em resumo, a recuperação de dados após algum tipo de perda ou interrupção requer um plano de BDR bem projetado. Eu recomendo que você entenda completamente seus requisitos de negócios para tempo de atividade, precisão/disponibilidade de dados e recuperação de desastres. Armado com um conhecimento detalhado de seus requisitos de negócios, você pode escolher cuidadosamente as ferramentas que melhor atendem a essas necessidades.
No entanto, selecionar as ferramentas é apenas o começo. Você deve executar testes em larga escala de sua estratégia de BDR para garantir que ela funcione funcionalmente em sua infraestrutura, atenda às suas necessidades de negócios e que suas equipes de operações estejam muito familiarizadas com as etapas necessárias antes que ocorra uma interrupção e você descubra da maneira mais difícil que seu plano BDR não funcionará.
Se você quiser comentar ou discutir mais sobre esse tópico, use nosso fórum da comunidade para HBase.
Leitura adicional:
- Apresentação Strata + Hadoop World 2012 de Jon Hsieh
- HBase:o guia definitivo (Lars George)
- HBase em ação (Nick Dimiduk/Amandeep Khurana)



