Em nosso blog anterior, estudamos Introdução ao Hadoop e Recursos do Hadoop , Agora, neste blog, abordaremos o recurso HDFS NameNode High Availability em detalhes.
Em primeiro lugar, discutiremos a arquitetura de alta disponibilidade do HDFS NemNode, em seguida, a implementação da arquitetura de alta disponibilidade do Hadoop usando o Quorum Journal Nodes e o armazenamento compartilhado.
Alta disponibilidade do HDFS NameNode
Em HDFS , os dados estão altamente disponíveis e acessíveis apesar da falha de hardware. HDFS é o sistema de armazenamento mais confiável projetado para armazenar arquivos muito grandes.
O HDFS segue a topologia mestre/escravo. Em qual mestre é NameNode e slaves é DataNode . NameNode armazena metadados. Os metadados incluem o número de blocos, sua localização, réplicas e outros detalhes. Para a recuperação mais rápida de dados, os metadados estão disponíveis no mestre. NameNode mantém e atribui tarefas ao nó escravo.
NameNode era o ponto único de falha (SPOF) antes do Hadoop 2.0. O cluster HDFS tinha um único NameNode. Se o NameNode falhar, todo o cluster ficará inativo.
O ponto único de falha limita a alta disponibilidade das seguintes maneiras:
- Se algum evento não planejado for acionado, como falha de nó, o cluster ficará indisponível, a menos que um operador reinicie o novo namenode.
- Além disso, atividades de manutenção planejadas, como atualizações de hardware no NameNode, resultarão em tempo de inatividade do cluster Hadoop.
Arquitetura de alta disponibilidade do HDFS NameNode
A introdução do Hadoop 2.0 supera esse SPOF fornecendo suporte a vários NameNode. A arquitetura HDFS NameNode High Availability oferece a opção de executar dois NameNodes redundantes no mesmo cluster em uma configuração ativa/passiva com hot standby.
- Node NameNode ativo – Ele lida com todas as operações do cliente HDFS no cluster HDFS.
- Passive NameNode – É um namenode em espera. Ele tem dados semelhantes ao NameNode ativo.
Portanto, sempre que o Active NameNode falhar, o NameNode passivo assumirá toda a responsabilidade do nó ativo. Assim, o cluster HDFS continua a funcionar.
Os problemas para manter a consistência no cluster de alta disponibilidade do HDFS são os seguintes:
- O NameNode ativo e de espera devem estar sempre sincronizados, ou seja, devem ter os mesmos metadados. Isso permite restabelecer o cluster do Hadoop no mesmo estado de namespace em que ele falhou. E isso nos proporcionará um failover rápido.
- Deve haver apenas um NameNode ativo por vez. Caso contrário, dois NameNode levarão à corrupção dos dados. Chamamos esse cenário de “cenário de cérebro dividido ”, onde um cluster é dividido no cluster menor. Cada um acredita que é o único cluster ativo. "Fencing" evita tal Fencing é um processo para garantir que apenas um NameNode permaneça ativo em um determinado momento.
Implementação da arquitetura de alta disponibilidade do Hadoop
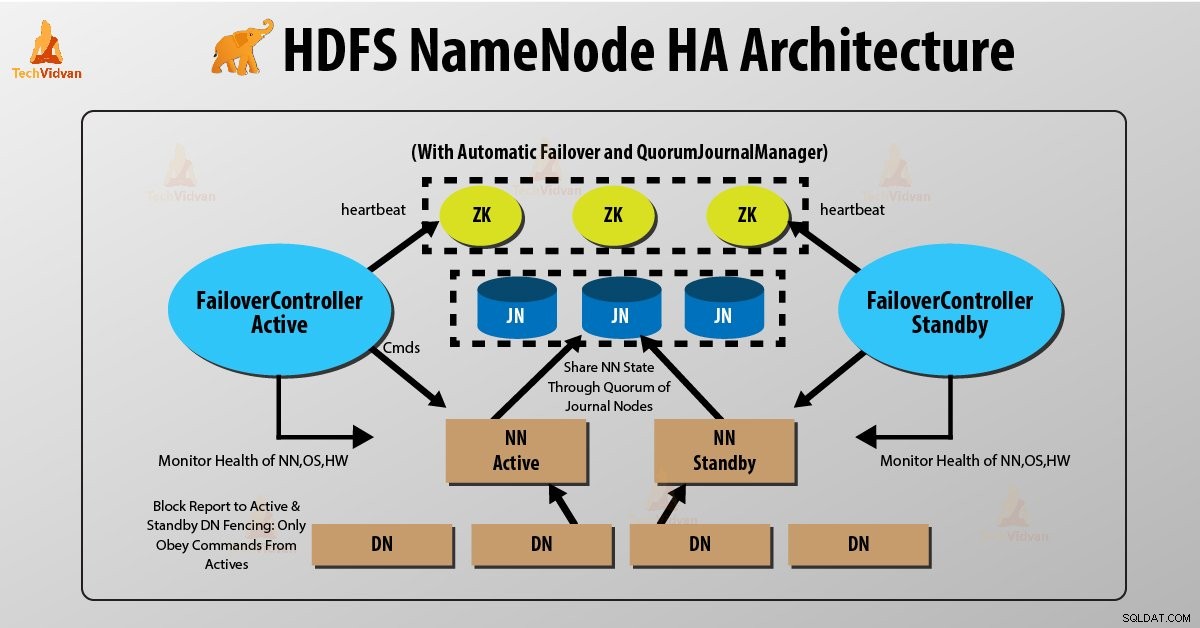
Dois NameNodes são executados ao mesmo tempo na arquitetura de alta disponibilidade HDFS NameNode. O cliente HDFS pode implementar a configuração Active e Standby NameNode das duas maneiras a seguir:
- Usando nós de diário de quórum
- Usando o armazenamento compartilhado
1. Usando nós de diário de quórum
Nós do diário de quórum é uma implementação HDFS. QJN fornece logs de edição. Ele permite compartilhar esses logs de edição entre o NameNode ativo e o de espera.
O Namenode de espera se comunica e sincroniza com o NameNode ativo para alta disponibilidade. Isso acontecerá por um grupo de daemons chamado “Journal nodes”. Os Nós de Diário de Quorum são executados como um grupo de nós de diário. Pelo menos três nós de diário devem estar lá.
Para N nós de diário, o sistema pode tolerar no máximo (N-1)/2 falhas. Assim, o sistema continua a funcionar. Assim, para três nós de diário, o sistema pode tolerar a falha de um {(3-1)/2} deles.
Sempre que um nó ativo executa qualquer modificação, ele registra a modificação em todos os nós do diário.
O nó em espera lê as edições dos nós de diário e se aplica ao seu próprio Namespace de maneira constante. No caso de failover, a espera garantirá que leu todas as edições dos nós do diário antes de se promover ao estado Ativo. Isso garante que o estado do namespace seja completamente sincronizado antes que ocorra uma falha.
Para fornecer um failover rápido, o nó em espera precisa ter informações atualizadas sobre a localização dos blocos de dados no cluster. Para que isso aconteça, o endereço IP de ambos os NameNode está disponível para todos os datanodes e eles enviam informações de localização do bloco e pulsações para ambos os NameNode.
Esgrima de NameNode
Para a operação correta de um cluster de alta disponibilidade, apenas um dos NameNodes deve estar ativo por vez. Caso contrário, o estado do namespace se desviaria entre os dois NameNodes. Assim, o fence é um processo para garantir essa propriedade em um cluster.
- Os nós de diário executam essa delimitação permitindo que apenas um NameNode seja o escritor por vez.
- O NameNode em espera assume a responsabilidade de gravar nos nós do diário e proíbe que qualquer outro NameNode permaneça ativo.
- Finalmente, o novo NameNode ativo pode realizar suas atividades.
2. Usando o armazenamento compartilhado
O NameNode em espera e o ativo sincronizam entre si usando “dispositivo de armazenamento compartilhado”. Para esta implementação, tanto o NameNode ativo quanto o Namenode em espera devem ter acesso ao diretório específico no dispositivo de armazenamento compartilhado (ou seja, sistema de arquivos de rede).
Quando o NameNode ativo executa qualquer modificação de namespace, ele registra um registro da modificação em um arquivo de log de edição armazenado no diretório compartilhado. O NameNode em espera observa as edições neste diretório e, quando ocorrem edições, o NameNode em espera as aplica ao seu próprio namespace. Em caso de falha, o NameNode em espera garantirá que leu todas as edições do armazenamento compartilhado antes de se promover ao estado Ativo. Isso garante que o estado do namespace seja completamente sincronizado antes que ocorra o failover.
Para evitar o “cenário de cérebro dividido” no qual o estado do namespace se desvia entre os dois NameNode, um administrador deve configurar pelo menos um método de fencing para o armazenamento compartilhado.
Conclusão
Portanto, o Hadoop 2.0 HDFS HA fornece um único NameNode ativo e um único NameNode de espera. Mas algumas implantações precisam de um alto grau de tolerância a falhas . Hadoop nova versão 3.0, permite ao usuário executar vários NameNodes em espera.
Por exemplo, configurar cinco journalnodes e três NameNode. Como resultado, o cluster hadoop é capaz de tolerar a falha de dois nós em vez de um.
Compartilhe sua experiência e sugestões relacionadas ao HDFS NameNode High Availability na seção de comentários abaixo.



