Neste tutorial do Hadoop , forneceremos uma introdução completa ao MapReduce Key Value Pair.
Em primeiro lugar, discutiremos o que é um par de valores-chave no Hadoop, como o par de valores-chave é gerado no MapReduce. Por fim, explicaremos a geração de pares de valores de chave MapReduce com exemplos.
O que é o par de valores-chave no Hadoop?
O par chave-valor no MapReduce é a entidade de registro que o Hadoop MapReduce aceita para execução.
Usamos o Hadoop principalmente para análise de dados. Ele lida com dados estruturados, não estruturados e semiestruturados. Com o Hadoop, se o esquema for estático, podemos trabalhar diretamente na coluna em vez do valor da chave. Mas, se o esquema não for estático, trabalharemos em um valor de chave.
O valor das chaves não são as propriedades intrínsecas dos dados. Mas eles são escolhidos pelo usuário que analisa os dados.
MapReduce é o componente central do Hadoop, que fornece processamento de dados. Ele executa o processamento dividindo o trabalho em duas fases:Fase de mapa e Reduzir fase . Cada fase tem valor-chave como entrada e saída.
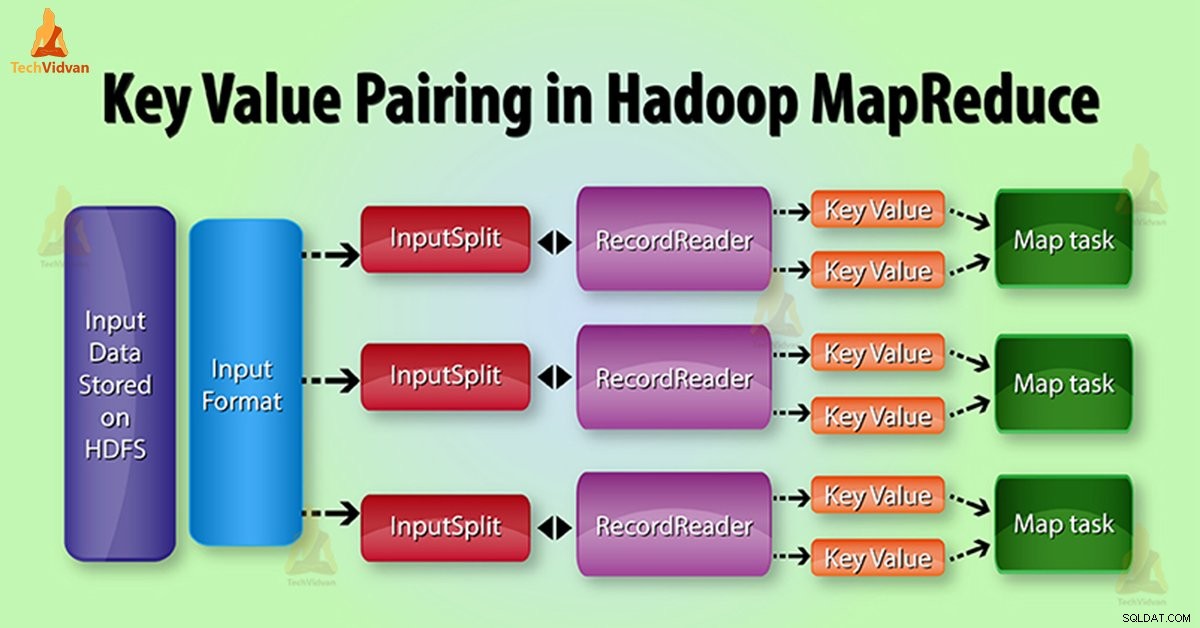
Geração de par de valores de chave MapReduce no Hadoop
Na execução do trabalho MapReduce, antes de enviar dados para o mapeador , primeiro converta-o em pares de valores-chave. Porque mapeador apenas pares de dados de valor-chave.
O par chave-valor no MapReduce é gerado da seguinte forma:
Divisão de entrada – É a representação lógica dos dados que InputFormat gera. No programa MapReduce descreve uma unidade de trabalho que contém uma única tarefa de mapa.
Leitor de registros – Ele se comunica com o InputSplit. Depois disso, ele converte os dados em pares de valores-chave adequados para leitura pelo Mapeador. RecordReader por padrão usa TextInputFormat para converter dados em pares de chave-valor.
Na execução do trabalho MapReduce, a função map processa um determinado par chave-valor. Em seguida, emite um certo número de pares de valores-chave. A função Reduzir processa os valores agrupados pela mesma chave.
Em seguida, emite outro conjunto de pares chave-valor como saída. Os tipos de saída do Mapa devem corresponder aos tipos de entrada do Reduzir, conforme mostrado abaixo:
- Mapa: (K1, V1) -> lista (K2, V2)
- Reduzir: {(K2, lista (V2}) -> lista (K3, V3)
Com base em que um par de valores-chave é gerado no Hadoop?
MapReduce A geração do par chave-valor depende totalmente do conjunto de dados. Também depende da saída necessária. O framework especifica o par chave-valor em 4 lugares:Mapear entrada/saída, Reduzir entrada/saída.
1. Entrada do mapa
Map Input por padrão usa o deslocamento de linha como chave. O conteúdo da linha é valor como Texto. Podemos modificá-los; usando o formato de entrada personalizado.
2. Saída do mapa
O Mapa é responsável por filtrar os dados. Ele também fornece o ambiente para agrupar os dados com base na chave.
- Chave– É o campo/texto/objeto no qual os dados são agrupados e agregados no redutor .
- Valor– É o campo/texto/objeto que cada indivíduo reduz os handles do método.
3. Reduza a entrada
A saída do mapa é entrada para reduzir. Portanto, é o mesmo que Map-Output.
4. Reduza a saída
Depende totalmente da saída necessária.
Exemplo de par de valores-chave MapReduce
Por exemplo, o conteúdo do arquivo que HDFS lojas são Chandler é Joey Mark é John . Então, agora usando InputFormat, vamos definir como esse arquivo será dividido e lido. Por padrão, RecordReader usa TextInputFormat para converter esse arquivo em um par chave-valor.
- Chave – É o deslocamento do início da linha dentro do arquivo.
- Valor – É o conteúdo da linha, excluindo os terminadores de linha.
Aqui,Chave é 0 e Valor é Chandler é Joey Mark é John.
Conclusão
Em conclusão, podemos dizer que, valor-chave é apenas uma entidade de registro que MapReduce aceita para execução. InputSplit e RecordReader geram o par chave-valor. Portanto, a chave é o deslocamento de byte e o valor é o conteúdo da linha.
Espero que tenha gostado deste blog. Se você tiver alguma sugestão ou consulta relacionada ao par de valores-chave MapReduce, deixe um comentário em uma seção abaixo.



