Em nosso tuto Hadoop anterior o rial , fornecemos uma descrição detalhada de InputFormat. Agora, neste blog, vamos cobrir o Hadoop OutputFormat.
Discutiremos o que é OutputFormat no Hadoop, o que é RecordWritter no MapReduce OutputFormat. Também abordaremos os tipos de OutputFormat no MapReduce.
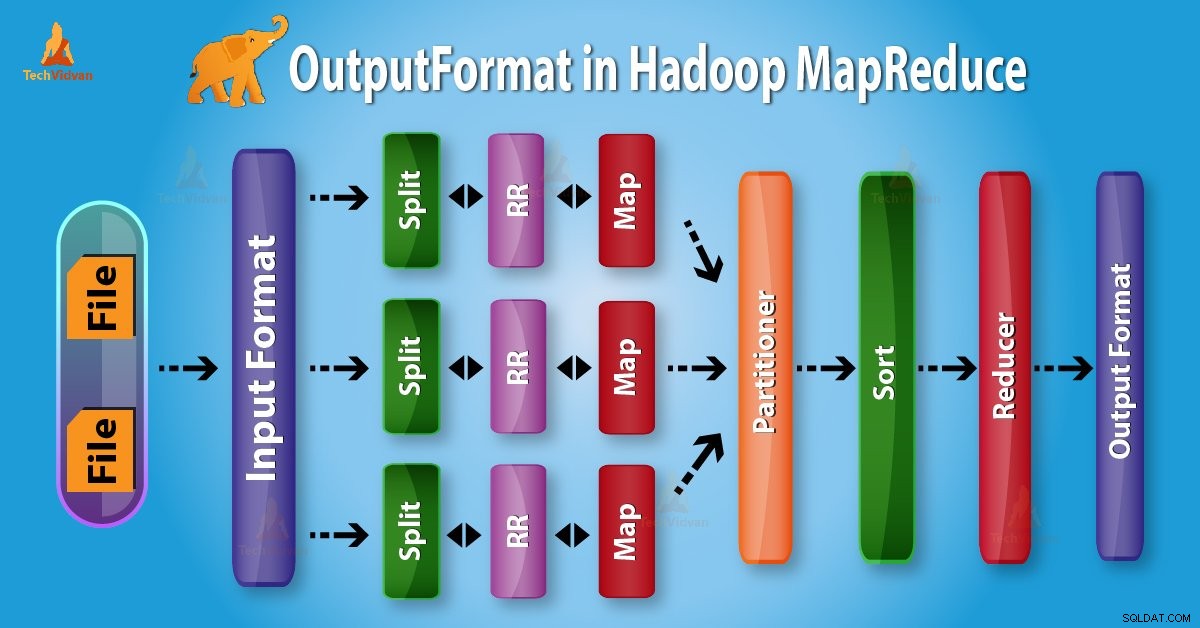
Introdução ao Hadoop OutputFormat
Formato de saída verifique a especificação de saída para execução do trabalho Map-Reduce. Ele descreve como a implementação do RecordWriter é usada para gravar a saída nos arquivos de saída.
Antes de começarmos com OutputFormat, vamos primeiro aprender o que é RecordWriter e qual é o trabalho de RecordWriter no MapReduce?
1. RecordWriter no Hadoop MapReduce
Como sabemos, Redutor leva Mapeadores saída intermediária como entrada. Em seguida, ele executa uma função redutora neles para gerar uma saída que é novamente zero ou mais pares de valores-chave.
Portanto, RecordWriter na execução do trabalho MapReduce grava esses pares chave-valor de saída da fase Redutor para arquivos de saída.
2. Formato de saída do Hadoop
De cima, fica claro que RecordWriter recebe dados de saída do Reducer. Em seguida, ele grava esses dados em arquivos de saída. OutputFormat determina a maneira como esses pares de chave-valor de saída são gravados em arquivos de saída pelo RecordWriter.
As funções OutputFormat e InputFormat são semelhantes. As instâncias OutputFormat são usadas para gravar em arquivos no disco local ou em HDFS. No MapReduce execução do trabalho com base na especificação de saída;
- O trabalho Hadoop MapReduce verifica se o diretório de saída ainda não está presente.
- OutputFormat no trabalho MapReduce fornece a implementação RecordWriter a ser usada para gravar os arquivos de saída do trabalho. Em seguida, os arquivos de saída são armazenados em um FileSystem.
A estrutura usa FileOutputFormat.setOutputPath() método para definir o diretório de saída.
Tipos de formato de saída no MapReduce
Existem vários tipos de OutputFormat que são os seguintes:
1. TextOutputFormat
O OutputFormat padrão é TextOutputFormat. Ele grava pares (chave, valor) em linhas individuais de arquivos de texto. Suas chaves e valores podem ser de qualquer tipo. A razão por trás disso é que TextOutputFormat os transforma em string chamando toString() neles.
Ele separa o par chave-valor por um caractere de tabulação. Usando MapReduce.output.textoutputformat.separator propriedade, também podemos alterá-la.
KeyValueTextOutputFormat também é usado para ler esses arquivos de texto de saída.
2. SequenceFileOutputFormat
Este OutputFormat grava arquivos de sequências para sua saída. SequenceFileInputFormat também é o uso de formato intermediário entre os trabalhos do MapReduce. Ele serializa tipos de dados arbitrários para o arquivo.
E o SequenceFileInputFormat correspondente desserializará o arquivo nos mesmos tipos. Ele apresenta os dados para o próximo mapeador da mesma forma que foi emitida pelo redutor anterior. Métodos estáticos também controlam a compressão.
3. SequenceFileAsBinaryOutputFormat
É outra variante de SequenceFileInputFormat. Ele também grava chaves e valores no arquivo de sequência em formato binário.
4. MapFileOutputFormat
É outra forma de FileOutputFormat. Ele também grava a saída como arquivos de mapa. A estrutura adiciona uma chave em um MapFile em ordem. Portanto, precisamos garantir que o redutor emita as chaves na ordem classificada.
5. Múltiplas saídas
Este formato permite gravar dados em arquivos cujos nomes são derivados das chaves e valores de saída.
6. LazyOutputFormat
Na execução do trabalho MapReduce, FileOutputFormat às vezes cria arquivos de saída, mesmo que estejam vazios. LazyOutputFormat também é um OutputFormat wrapper.
7. DBOutputFormat
É o OutputFormat para gravar em bancos de dados relacionais e HBase. Esse formato também envia a saída de redução para uma tabela SQL. Ele também aceita pares de valores-chave. Neste, a chave tem um tipo que estende DBwritable.
Conclusão
Assim, diferentes OutputFormats são usados de acordo com a necessidade. Espero que você ache este blog útil. Se você tiver alguma dúvida sobre o Hadoop OutputFormat, deixe um comentário em uma caixa de comentários. Teremos o maior prazer em resolvê-los.



