Este tutorial do Hadoop é tudo sobre MapReduce Shuffling and Sorting. Aqui, forneceremos uma descrição detalhada da fase de embaralhamento e classificação do Hadoop.
Em primeiro lugar, discutiremos o que é MapReduce Shuffling, em seguida, MapReduce Sorting e, em seguida, abordaremos a fase de classificação secundária do MapReduce em detalhes.
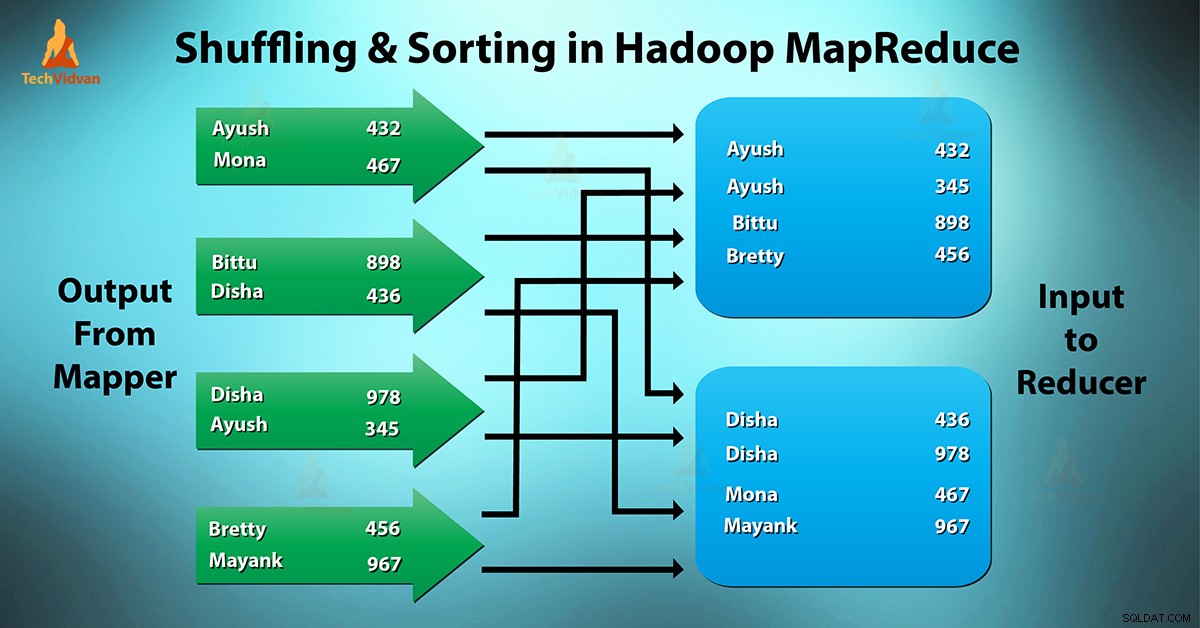
O que é o embaralhamento e classificação do MapReduce?
Embaralhando é o processo pelo qual ele transfere mapeadores saída intermediária para o redutor. O redutor obtém 1 ou mais chaves e valores associados com base nos redutores.
A chave intermediária – valor gerado pelo mapeador é classificado automaticamente por chave. Na fase de classificação, ocorre a mesclagem e a classificação da saída do mapa.
O embaralhamento e a classificação no Hadoop ocorrem simultaneamente.
Embaralhando no MapReduce
O processo de transferência de dados dos mapeadores para os redutores está embaralhado. É também o processo pelo qual o sistema executa a classificação. Em seguida, ele transfere a saída do mapa para o redutor como entrada. Esta é a razão pela qual a fase de embaralhamento é necessária para os redutores.
Caso contrário, eles não teriam nenhuma entrada (ou entrada de cada mapeador). Já que o embaralhamento pode começar antes mesmo que a fase do mapa termine. Portanto, isso economiza algum tempo e conclui as tarefas em menos tempo.
Classificando no MapReduce
O MapReduce Framework classifica automaticamente as chaves geradas pelo mapeador. Assim, antes de iniciar o redutor, todos os pares de chave-valor intermediários são classificados por chave e não por valor. Ele não classifica os valores passados para cada redutor. Eles podem estar em qualquer ordem.
A classificação em um trabalho MapReduce ajuda o redutor a distinguir facilmente quando uma nova tarefa de redução deve ser iniciada.
Isso economiza tempo para o redutor. O Reducer no MapReduce inicia uma nova tarefa de redução quando a próxima chave nos dados de entrada classificados é diferente da anterior. Cada tarefa de redução recebe pares de valores-chave como entrada e gera pares de valores-chave como saída.
O importante a observar é que o embaralhamento e a classificação no Hadoop MapReduce não ocorrerão se você especificar zero redutores (setNumReduceTasks(0)).
Se o redutor for zero, o trabalho MapReduce parará na fase de mapa. E a fase do mapa não inclui nenhum tipo de ordenação (mesmo a fase do mapa é mais rápida).
Classificação secundária no MapReduce
Se quisermos classificar os valores do redutor, usamos uma técnica de classificação secundária. Essa técnica nos permite ordenar os valores (em ordem crescente ou decrescente) passados para cada redutor.
Conclusão
Em conclusão, MapReduce Shuffling e Sorting ocorrem simultaneamente para resumir a saída intermediária do Mapper. Hadoop Shuffling-Sorting não ocorrerá se você especificar zero redutores (setNumReduceTasks (0)).
O framework classifica todos os pares de valores-chave intermediários por chave, não por valor. Ele usa classificação secundária para classificação por valor. Se você tiver alguma sugestão ou consulta relacionada à fase de embaralhamento e classificação do MapReduce, deixe um comentário em uma caixa de comentários.
Ficaremos felizes em resolvê-los.



