Em nosso Hadoop anterior blogs, estudamos cada componente do Hadoop Processo MapReduce em detalhes. Neste, vamos discutir o tópico muito interessante, ou seja, o trabalho Map Only no Hadoop.
Primeiramente, faremos uma breve introdução ao Mapa e Reduzir fase no Hadoop Mapreduce, depois discutiremos o que é o trabalho Map only no Hadoop MapReduce.
Por fim, também discutiremos as vantagens e desvantagens do trabalho Hadoop Map Only neste tutorial.
O que é o trabalho apenas do mapa do Hadoop?
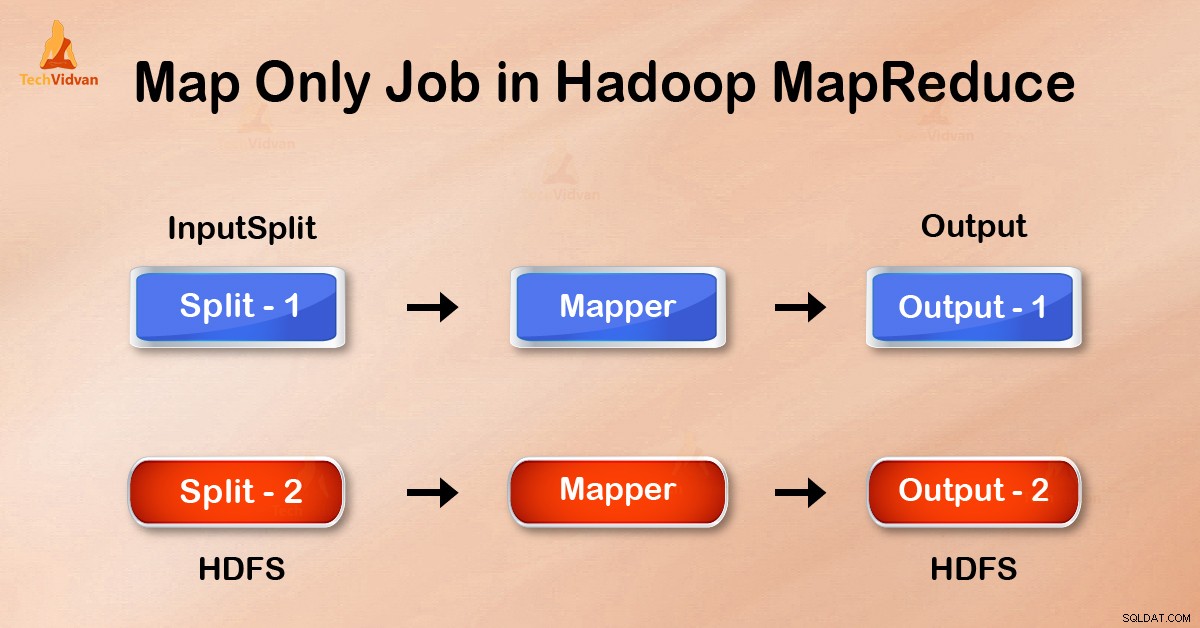
Trabalho somente de mapa no Hadoop é o processo no qual o mapeador faz todas as tarefas. Nenhuma tarefa é realizada pelo redutor . A saída do Mapper é a saída final.
MapReduce é a camada de processamento de dados do Hadoop. Ele processa grandes dados estruturados e não estruturados armazenados em HDFS . O MapReduce também processa uma enorme quantidade de dados em paralelo.
Ele faz isso dividindo o trabalho (trabalho enviado) em um conjunto de tarefas independentes (subtrabalho). No Hadoop, o MapReduce funciona dividindo o processamento em fases:Map e Reduzir .
- Mapa: É a primeira fase do processamento, onde especificamos todo o código lógico complexo. Ele pega um conjunto de dados e converte em outro conjunto de dados. Ele divide cada elemento individual em tuplas (pares de valor-chave ).
- Reduzir: É a segunda fase do processamento. Aqui especificamos o processamento leve como agregação/soma. Ele recebe a saída do mapa como entrada. Em seguida, combina essas tuplas com base na chave.
A partir deste exemplo de contagem de palavras, podemos dizer que existem dois conjuntos de processos paralelos, mapear e reduzir. No processo do mapa, a primeira entrada é dividida para distribuir o trabalho entre todos os nós do mapa, conforme mostrado acima.
Em seguida, o framework identifica cada palavra e mapeia para o número 1. Assim, ele cria pares chamados pares de tuplas (chave-valor).
No primeiro nó do mapeador, ele passa três palavras leão, tigre e rio. Assim, ele produz 3 pares chave-valor como saída do nó. Três chaves e valores diferentes definidos como 1 e o mesmo processo se repete para todos os nós.
Em seguida, ele passa essas tuplas para os nós redutores. O particionador realiza embaralhamento de modo que todas as tuplas com a mesma chave vão para o mesmo nó.
No processo de redução o que acontece basicamente é uma agregação de valores ou melhor, uma operação em valores que compartilham a mesma chave.
Agora, vamos considerar um cenário onde só precisamos realizar a operação. Não precisamos de agregação, nesse caso, preferimos 'trabalho somente mapa '.
No trabalho Map-Only, o mapa faz todas as tarefas com seu InputSplit . O redutor não funciona. A saída dos mapeadores é a saída final.
Como evitar a fase de redução no MapReduce?
Configurando job.setNumreduceTasks(0) na configuração em um driver podemos evitar reduzir a fase. Isso fará com que um número de redutores como 0 . Assim, o único mapeador fará a tarefa completa.
Vantagens do trabalho somente mapa no Hadoop
Na execução do trabalho MapReduce entre as fases de mapa e redução, há a fase de chave, classificação e embaralhar. Embaralhando – Classificando são responsáveis por classificar as chaves em ordem crescente. Em seguida, agrupe os valores com base nas mesmas chaves. Esta fase é muito cara.
Se a fase de redução não for necessária, devemos evitá-la. Como evitar a fase de redução, também eliminaria a fase de classificação e de embaralhamento. Portanto, isso também economizará o congestionamento da rede.
A razão é que, no embaralhamento, uma saída do mapeador viaja para reduzir. E quando o tamanho dos dados é grande, grandes dados precisam viajar para o redutor.
A saída do mapeador é gravada no disco local antes de enviar para reduzir. Mas no trabalho somente mapa, essa saída é gravada diretamente no HDFS. Isso economiza ainda mais tempo e reduz custos.
Conclusão
Assim, vimos que o trabalho Map-only reduz o congestionamento da rede evitando a fase de embaralhar, classificar e reduzir. Map sozinho cuida do processamento geral e produz a saída. AO usar job.setNumreduceTasks(0) isso é alcançado.
Espero que você tenha entendido o trabalho apenas mapa do Hadoop e é significativo porque abordamos tudo sobre o trabalho Somente mapa no Hadoop. Mas se você tiver alguma dúvida, pode compartilhar conosco na seção de comentários.



