Em nosso tutorial Hadoop anterior , estudamos o Hadoop Partitioner em detalhe. Agora vamos discutir o InputSplit no Hadoop MapReduce.
Aqui, abordaremos o que é o Hadoop InputSplit, a necessidade do InputSplit no MapReduce. Também discutiremos detalhadamente como esses InputSplits são criados no Hadoop MapReduce.
Introdução ao InputSplit no Hadoop
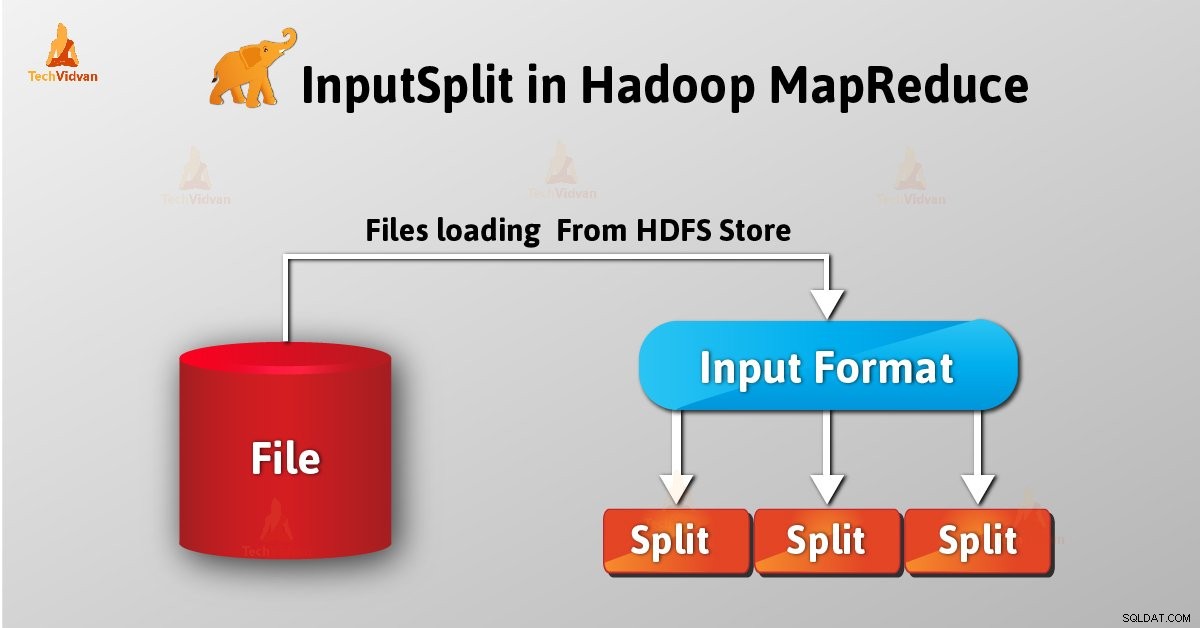
InputSplit é a representação lógica de dados no Hadoop MapReduce. Ele representa os dados que o mapeador individual processos. Assim, o número de tarefas de mapa é igual ao número de InputSplits. O framework divide a divisão em registros, que o mapeador processa.
O comprimento do MapReduce InputSplit foi medido em bytes. Cada InputSplit possui locais de armazenamento (sequências de nomes de host). O sistema MapReduce coloca as tarefas de mapa o mais próximo possível dos dados da divisão usando locais de armazenamento.
Processos do framework Mapeie as tarefas na ordem do tamanho das divisões para que a maior seja processada primeiro (algoritmo de aproximação guloso). Isso minimiza o tempo de execução do trabalho.
A principal coisa a focar é que o Inputsplit não contém os dados de entrada; é apenas uma referência aos dados.
Como os InputSplits são criados no Hadoop MapReduce?
Como usuário, não lidamos diretamente com o InputSplit no Hadoop, pois InputFormat (como InputFormat é responsável por criar o Inputsplit e dividir nos registros) o cria. FileInputFormat divide um arquivo em pedaços de 128 MB.
Além disso, definindo mapred .min .dividir .tamanho parâmetro em site mapred .xml o usuário pode alterar o valor conforme a necessidade. Além disso, podemos substituir o parâmetro no objeto Job usado para enviar um determinado trabalho MapReduce.
Ao escrever um InputFormat personalizado, também podemos controlar como o arquivo é dividido em divisões.
InputSplit é definido pelo usuário. O usuário também pode controlar o tamanho da divisão com base no tamanho dos dados no programa MapReduce. Portanto, em uma execução de trabalho MapReduce, o número de tarefas de mapa é igual ao número de InputSplits.
Chamando 'getSplit()' , o cliente calcula as divisões para o trabalho. Em seguida, ele é enviado ao mestre de aplicativos, que usa seus locais de armazenamento para agendar tarefas de mapa que as processarão no cluster.
Depois que a tarefa de mapa passa a divisão para o createRecordReader() método. A partir disso, obtém o RecordReader para a divisão. Em seguida, o RecordReader gera o registro (par chave-valor) , que passa para a função map.
Conclusão
Em conclusão, podemos dizer que, InputSplit representa os dados que o mapeador individual processa. Para cada divisão é criada uma tarefa de mapa. Portanto, InputFormat cria o InputSplit.
Se você tiver alguma dúvida sobre o InputSplit no MapReduce, por favor, deixe um comentário em uma seção abaixo.



