Se você quer saber tudo sobre o Hadoop MapReduce, está no lugar certo. Este tutorial do MapReduce fornece um guia completo sobre tudo e todos no Hadoop MapReduce.
Nesta introdução ao MapReduce, você explorará o que é o Hadoop MapReduce, como funciona a estrutura do MapReduce. O artigo também abrange MapReduce DataFlow, diferentes fases no MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sorting, Data Locality e muito mais.
Também listamos as vantagens do framework MapReduce.
Vamos primeiro explorar por que precisamos do Hadoop MapReduce.
Por que MapReduce?
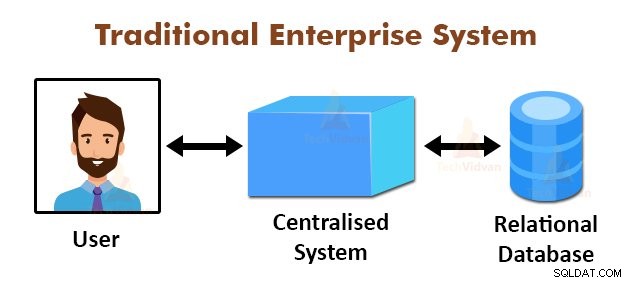
A figura acima mostra a visão esquemática dos sistemas corporativos tradicionais. Os sistemas tradicionais normalmente possuem um servidor centralizado para armazenamento e processamento de dados. Este modelo não é adequado para processar grandes quantidades de dados escaláveis.
Além disso, esse modelo não pôde ser acomodado pelos servidores de banco de dados padrão. Além disso, o sistema centralizado cria muitos gargalos ao processar vários arquivos simultaneamente.
Usando o algoritmo MapReduce, o Google resolveu esse problema de gargalo. A estrutura MapReduce divide a tarefa em pequenas partes e atribui tarefas a vários computadores.
Posteriormente, os resultados são coletados em um lugar comum e integrados para formar o conjunto de dados de resultados.
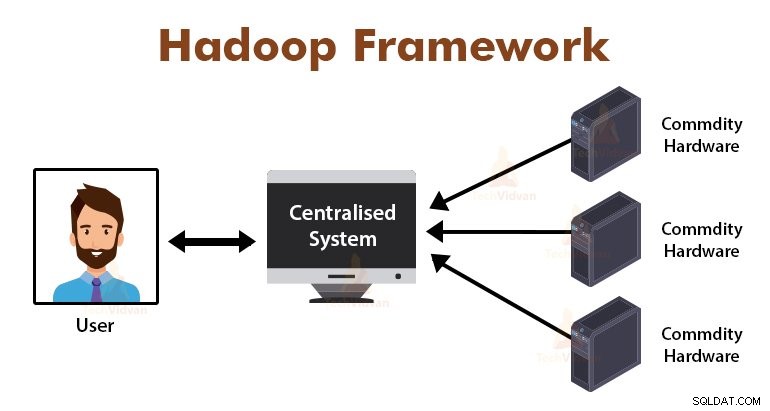
Introdução ao MapReduce Framework
MapReduce é a camada de processamento no Hadoop. É uma estrutura de software projetada para processar grandes volumes de dados em paralelo, dividindo a tarefa no conjunto de tarefas independentes.
Só precisamos colocar a lógica de negócios na forma como o MapReduce funciona, e o framework cuidará do resto. A estrutura MapReduce funciona dividindo o trabalho em pequenas tarefas e atribui essas tarefas aos escravos.
Os programas MapReduce são escritos em um estilo particular influenciado pelas construções de programação funcional, idiomas específicos para processar as listas de dados.
No MapReduce, as entradas estão na forma de uma lista e a saída do framework também está na forma de uma lista. MapReduce é o coração do Hadoop. A eficiência e o poder do Hadoop se devem ao processamento paralelo da estrutura MapReduce.
Vamos agora explorar como o Hadoop MapReduce funciona.
Como o Hadoop MapReduce funciona?
A estrutura Hadoop MapReduce funciona dividindo um trabalho em tarefas independentes e executando essas tarefas em máquinas escravas. O trabalho MapReduce é executado em dois estágios que são a fase de mapeamento e a fase de redução.
A entrada e saída de ambas as fases são pares chave e valor. A estrutura MapReduce é baseada no princípio de localidade de dados (discutido posteriormente), o que significa que ele envia a computação para os nós onde os dados residem.
- Fase do mapa − Na fase Mapa, a função de mapa definida pelo usuário processa os dados de entrada. Na função map, o usuário coloca a lógica de negócio. A saída da fase Map são as saídas intermediárias e são armazenadas no disco local.
- Fase de redução – Esta fase é a combinação da fase de embaralhamento e da fase de redução. Na fase Reduzir, a saída do estágio de mapa é passada para o Redutor onde são agregadas. A saída da fase Reduzir é a saída final. Na fase Reduzir, a função de redução definida pelo usuário processa a saída dos mapeadores e gera os resultados finais.
Durante o trabalho MapReduce, a estrutura do Hadoop envia as tarefas Map e as tarefas Reduce para as máquinas apropriadas no cluster.
A própria estrutura gerencia todos os detalhes da passagem de dados, como emitir tarefas, verificar a conclusão da tarefa e copiar dados entre os nós ao redor do cluster. As tarefas ocorrem nos nós onde os dados residem para reduzir o tráfego da rede.
Mapear o fluxo de dados
Todos vocês podem querer saber como esses pares de valores-chave são gerados e como o MapReduce processa os dados de entrada. Esta seção responde a todas essas perguntas.
Vamos ver como os dados devem fluir de várias fases no Hadoop MapReduce para lidar com dados futuros de maneira paralela e distribuída.
1. Arquivos de entrada
O conjunto de dados de entrada, que deve ser processado pelo programa MapReduce, é armazenado no InputFile. O InputFile é armazenado no Hadoop Distributed File System.
2. Divisão de entrada
O registro nos InputFiles é dividido no modelo lógico. O tamanho da divisão é geralmente igual ao tamanho do bloco HDFS. Cada divisão é processada pelo Mapeador individual.
3. Formato de entrada
InputFormat especifica a especificação de entrada do arquivo. Ele define o caminho para o RecordReader no qual o registro do InputFile é convertido nos pares de chave e valor.
4. Leitor de registros
RecordReader lê os dados do InputSplit e converte os registros na chave, pares de valor e os apresenta aos Mapeadores.
5. Mapeadores
Os mapeadores recebem pares de chave e valor como entrada do RecordReader e os processam implementando a função de mapa definida pelo usuário. Em cada Mapeador, por vez, uma única divisão é processada.
O desenvolvedor colocou a lógica de negócios na função map. A saída de todos os mapeadores é a saída intermediária, que também está na forma de pares de chave e valor.
6. Embaralhar e classificar
A saída intermediária gerada pelos mapeadores é classificada antes de passar para o redutor para reduzir o congestionamento da rede. As saídas intermediárias classificadas são então embaralhadas para o Redutor pela rede.
7. Redutor
O Redutor processa e agrega as saídas do Mapeador implementando a função de redução definida pelo usuário. A saída dos Redutores é a saída final e é armazenada no Hadoop Distributed File System (HDFS).
Vamos agora estudar algumas terminologias e conceitos avançados do framework Hadoop MapReduce.
Pares de valores-chave no MapReduce
A estrutura MapReduce funciona nos pares de chave e valor porque lida com o esquema não estático. Ele recebe dados na forma de chave, par de valores e a saída gerada também está na forma de chave, pares de valores.
O par de valores de chave MapReduce é uma entidade de registro que é recebida pelo trabalho MapReduce para a execução. Em um par chave-valor:
- Chave é o deslocamento da linha desde o início da linha dentro do arquivo.
- Valor é o conteúdo da linha, excluindo os terminadores de linha.
Particionador MapReduce
O Particionador Hadoop MapReduce particiona o keyspace. Particionar o espaço de chave no MapReduce especifica que todos os valores de cada chave foram agrupados e garante que todos os valores da chave única devem ir para o mesmo Redutor.
Esse particionamento permite a distribuição uniforme da saída do mapeador sobre o Redutor, garantindo que a chave certa vá para o Redutor certo.
O particionador padrão do MapReducer é o Particionador de Hash, que particiona os espaços de chave com base no valor de hash.
Combinador MapReduce
O MapReduce Combiner também é conhecido como “Semi-Reducer”. Desempenha um papel importante na redução do congestionamento da rede. A estrutura MapReduce fornece a funcionalidade para definir o Combiner, que combina a saída intermediária dos Mappers antes de passá-los para o Reducer.
A agregação das saídas do Mapper antes de passar para o Reducer ajuda a estrutura a embaralhar pequenas quantidades de dados, levando a um baixo congestionamento de rede.
A principal função do Combiner é resumir a saída dos Mappers com a mesma chave e passá-la para o Reducer. A classe Combiner é usada entre a classe Mapper e a classe Redutor.
Localidade de dados no MapReduce
A localidade dos dados refere-se a "Movendo a computação para mais perto dos dados em vez de mover os dados para a computação." É muito mais eficiente se a computação solicitada pela aplicação for executada na máquina onde residem os dados solicitados.
Isso é muito verdadeiro no caso em que o tamanho dos dados é enorme. É porque minimiza o congestionamento da rede e aumenta a taxa de transferência geral do sistema.
A única suposição por trás disso é que é melhor mover a computação para mais perto da máquina onde os dados estão presentes em vez de mover os dados para a máquina onde o aplicativo está sendo executado.
O Apache Hadoop funciona em um grande volume de dados, portanto, não é eficiente mover dados tão grandes pela rede. Por isso, a estrutura surgiu com o princípio mais inovador que é a localidade de dados, que move a lógica de computação para os dados em vez de mover os dados para os algoritmos de computação. Isso é chamado de localidade de dados.
Vantagens do MapReduce
1. Escalabilidade: A estrutura MapReduce é altamente escalável. Ele permite que as organizações executem aplicativos a partir de grandes conjuntos de máquinas, que podem envolver o uso de milhares de terabytes de dados.
2. Flexibilidade: A estrutura MapReduce oferece flexibilidade para a organização processar dados de qualquer tamanho e formato, estruturados, semiestruturados ou não estruturados.
3. Segurança e autenticação: O modelo de programação MapReduce oferece alta segurança. Ele protege qualquer acesso não autorizado aos dados e aumenta a segurança do cluster.
4. Custo-benefício: A estrutura processa dados em todo o cluster de hardware comum, que são máquinas baratas. Assim, é muito rentável.
5. Rápido: O MapReduce processa os dados em paralelo, pelo que é muito rápido. Leva apenas alguns minutos para processar terabytes de dados.
6. Um modelo simples para programação: Os programas MapReduce podem ser escritos em qualquer linguagem como Java, Python, Perl, R, etc. Assim, qualquer pessoa pode facilmente aprender e escrever programas MapReduce e atender às suas necessidades de processamento de dados.
Uso do MapReduce
1. Análise de registro: MapReduce é usado basicamente para analisar arquivos de log. A estrutura divide os grandes arquivos de log na divisão e um mapeador pesquisa as diferentes páginas da Web que foram acessadas.
Toda vez que uma página da Web é encontrada no log, um par de chave e valor é passado para o redutor, onde a chave é a página da Web e o valor é “1”. Depois de emitir uma chave, um par de valores para o Redutor, os Redutores agregam o número de para determinadas páginas da web.
O resultado final será o número total de acessos para cada página da web.
2. Indexação de texto completo: MapReduce também é usado para realizar a indexação de texto completo. O mapeador no MapReduce mapeará cada frase ou palavra em um documento para o documento. O Redutor gravará esses mapeamentos em um índice.
3. O Google usa MapReduce para calcular seu Pagerank.
4. Gráfico de link da Web reverso: MapReduce também é usado no Reverse Web-Link GRaph. A função Map gera o destino e a origem da URL, obtendo a entrada da página da Web (origem).
A função reduce então concatena a lista de todos os URLs de origem que estão associados ao URL de destino fornecido e retorna o destino e a lista de origens.
5. Contagem de palavras em um documento: A estrutura MapReduce pode ser usada para contar o número de vezes que a palavra aparece em um documento.
Resumo
Isso é tudo sobre o Hadoop MapReduce Tutorial. A estrutura processa grandes volumes de dados em paralelo em todo o cluster de hardware comum. Ele divide o trabalho em tarefas independentes e as executa em paralelo em diferentes nós do cluster.
O MapReduce supera o gargalo do sistema empresarial tradicional. A estrutura funciona nos pares de chave e valor. O usuário define as duas funções que são a função map e a função reduce.
A lógica de negócios é colocada na função map. O artigo explicou vários conceitos avançados da estrutura MapReduce.



