Esta postagem de blog apresentará um exemplo simples do tipo “hello world” sobre como obter dados armazenados no S3 indexados e servidos por um serviço Apache Solr hospedado em um cluster de descoberta e exploração de dados no CDP. Para os curiosos:DDE é uma opção de implantação de cluster otimizada para Solr pré-modelada no CDP e lançada recentemente em visualização técnica . Abordaremos apenas os ambientes AWS e S3 neste blog. As opções de implantação do Azure e ADLS também estão disponíveis na visualização técnica, mas serão abordadas em uma postagem de blog futura.
Vamos descrever o cenário mais simples para facilitar o início. É claro que existem configurações de pipeline de dados mais avançadas e esquemas mais ricos possíveis, mas esse é um bom ponto de partida para um iniciante.
Suposições:
- Você já tem uma conta CDP e tem direitos de usuário avançado ou administrador para o ambiente no qual planeja ativar este serviço.
Se você não tiver uma conta CDP AWS, entre em contato com seu representante Cloudera favorito ou inscreva-se para uma avaliação do CDP aqui. - Você tem ambientes e identidades mapeados e configurados. Mais explicitamente, tudo o que você precisa é ter o mapeamento do usuário do CDP para uma função da AWS que conceda acesso ao bucket s3 específico do qual você deseja ler (e gravar).
- Você tem uma senha de carga de trabalho (FreeIPA) já definida.
- Você tem um cluster DDE em execução. Você também pode encontrar mais informações sobre como usar modelos no CDP Data Hub aqui.
- Você tem acesso CLI a esse cluster.
- A porta SSH está aberta na AWS quanto ao seu endereço IP. Você pode obter o endereço IP público de um dos nós do Solr nos detalhes do cluster do Datahub. Aprenda aqui como fazer SSH para um cluster da AWS.
- Você tem um arquivo de log em um bucket do S3 que pode ser acessado pelo usuário (
/sample.log neste exemplo). Se você não tiver um, aqui está um link para o que usamos.
Fluxo de trabalho
As seções a seguir o guiarão pelas etapas para obter dados indexados usando a Crunch Indexer Tool que vem com o DDE.

Crie uma coleção para armazenar seu índice
No HUE existe um designer de índice; no entanto, enquanto o DDE estiver no Tech Preview, ele estará um pouco em reconstrução e não é recomendado neste momento. Mas, por favor, tente depois que o DDE for GA e deixe-nos saber o que você pensa.
Por enquanto, você pode criar seu esquema e configurações do Solr usando a ferramenta CLI ‘solrctl’. Crie uma configuração chamada 'my-own-logs-config' e uma coleção chamada 'my-own-logs'. Isso requer que você tenha acesso CLI.
1. SSH para qualquer um dos nós do trabalhador em seu cluster.
2. kinit como usuário com permissão para criar a configuração da coleção:
kinit
3. Certifique-se de que a variável de ambiente SOLR_ZK_ENSEMBLE esteja configurada em /etc/solr/conf/solr-env.sh. Salve seu valor, pois isso será necessário em etapas posteriores.
Pressione Enter e digite sua senha de carga de trabalho (FreeIPA).
Por exemplo:
cat /etc/solr/conf/solr-env.sh
Saída esperada:
export SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Isso é definido automaticamente em hosts com uma função Solr Server ou Gateway no Cloudera Manager.
4. Para gerar arquivos de configuração para a coleção, execute o seguinte comando:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate é um dos modelos padrão fornecidos com o Solr no CDP, mas, sendo um modelo, é imutável. Para os propósitos deste fluxo de trabalho, você precisa copiá-lo e, assim, criar um novo que seja mutável (é isso que a opção imutável=falso faz). Isso fornece uma configuração flexível e sem esquema. Criar um esquema bem projetado é algo em que vale a pena investir tempo de design, mas não é necessário para uso exploratório. Por esse motivo, está além do escopo desta postagem no blog. No entanto, em um ambiente de produção real, recomendamos fortemente o uso de esquemas bem projetados – e estamos felizes em fornecer ajuda especializada, se necessário!
5. Crie uma nova coleção usando o seguinte comando:
solrctl collection --create my-own-logs -s 1 -c my-own-logs-config
Isso cria a coleção "my-own-logs" com base na configuração da coleção "my-own-logs-config" em um estilhaço.
6. Para validar que a coleção foi criada, você pode navegar até a IU do Solr Admin. A coleção de “my-own-logs” estará disponível no menu suspenso na navegação à esquerda.

Indexar seus dados
Aqui descrevemos usando um exemplo simples como configurar e executar a ferramenta Crunch Indexer incorporada para indexar dados rapidamente no S3 e servir por meio do Solr no DDE. Como a proteção do cluster pode utilizar CM Auto TLS, Knox, Kerberos e Ranger, o "Spark submit" pode depender de aspectos não abordados nesta postagem.
A indexação de dados do S3 é igual à indexação do HDFS.
Execute essas etapas no nó do trabalhador do Yarn (chamado de "Yarnworker" na interface da web do Management Console).
1. SSH para o nó do trabalhador Yarn dedicado do cluster DDE como um usuário administrador do Solr.
Para descobrir o endereço IP do nó do trabalhador Yarn, clique em Hardware guia na página de detalhes do cluster e, em seguida, role até o nó "Yarnworker".

2. Vá para o seu diretório de recursos (ou crie um se ainda não o tiver:
cd
Use a pasta inicial do usuário administrador como o diretório de recursos (
3. Faça o Kinit do seu usuário:
kinit
Pressione Enter e digite sua senha de carga de trabalho (FreeIPA).
4. Execute o seguinte comando curl, substituindo
curl --negotiate -u: "https://<SOLR_HOST>:<SOLR_PORT>/solr/admin?op=GETDELEGATIONTOKEN" --insecure > tokenFile.txt
5. Crie um arquivo de configuração Morphline para a Crunch Indexer Tool, read-log-morphline.conf neste exemplo. Substitua
SOLR_LOCATOR : {
# Name of solr collection
collection : my-own-logs
#zk ensemble
zkHost : <SOLR_ZK_ENSEMBLE>
}
morphlines : [
{
id : loadLogs
importCommands : ["org.kitesdk.**", "org.apache.solr.**"]
commands : [
{
readMultiLine {
regex : "(^.+Exception: .+)|(^\\s+at .+)|(^\\s+\\.\\.\\. \\d+ more)|(^\\s*Caused by:.+)"
what : previous
charset : UTF-8
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
{
loadSolr {
solrLocator : ${SOLR_LOCATOR}
}
}
]
}
] Este Morphline lê os rastreamentos de pilha do arquivo de log fornecido, grava um log de entrada de depuração e o carrega no Solr especificado.
6. Crie um arquivo log4j.properties para configuração de log:
log4j.rootLogger=INFO, A1 # A1 is set to be a ConsoleAppender. log4j.appender.A1=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Verifique se o arquivo que você deseja ler existe no S3 (se você não tiver um, aqui está um link para o que usamos para este exemplo simples:
aws s3 ls s3://<S3_BUCKET>/sample.log
8. Execute o comando spark-submit:
Substitua os espaços reservados em
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunch export myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunch export myDriverJar=$(find $myDriverJarDir -maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar') export myDependencyJarFiles=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1) export myDependencyJarPaths=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ " export myResourcesDir="<RESOURCE_DIR>" export HADOOP_CONF_DIR="/etc/hadoop/conf" spark-submit \ --master yarn \ --deploy-mode cluster \ --jars $myDependencyJarFiles \ --executor-memory 1024M \ --conf "spark.executor.extraJavaOptions=$myJVMOptions" \ --driver-java-options "$myJVMOptions" \ --class org.apache.solr.crunch.CrunchIndexerTool \ --files $(ls $myResourcesDir/log4j.properties),$(ls $myResourcesDir/read-log-morphline.conf),tokenFile.txt \ $myDriverJar \ -Dhadoop.tmp.dir=/tmp \ -DtokenFile=tokenFile.txt \ --morphline-file read-log-morphline.conf \ --morphline-id loadLogs \ --pipeline-type spark \ --chatty \ --log4j log4j.properties \ s3a://<S3_BUCKET>/sample.log
Se você encontrar uma mensagem semelhante, poderá desconsiderá-la:
WARN metadata.Hive: Failed to register all functions. org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException
9. Para monitorar a execução do comando, vá para o Resource Manager.

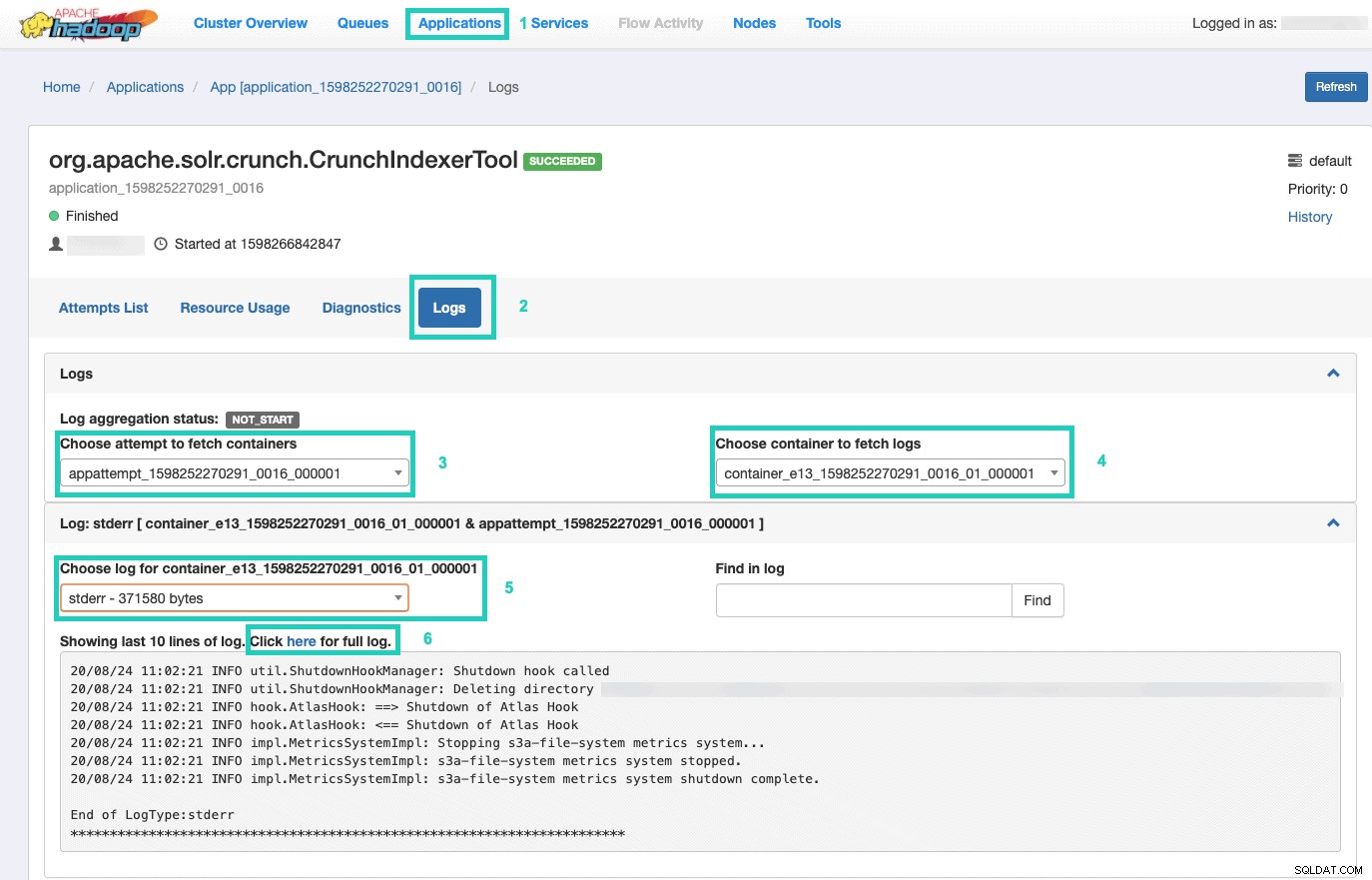
Uma vez lá, selecione os Aplicativos guia > Clique no ID do aplicativo da tentativa de aplicativo que você deseja monitorar > Selecione Registros> Escolher tentativa de buscar contêineres> Escolher contêiner para buscar registros> Escolher registro para contêiner> Selecione o stderr log> Clique em Clique aqui para log completo .
Exiba seu índice
Você tem muitas opções de como servir os dados indexados pesquisáveis aos usuários finais. Você pode criar seu próprio aplicativo rico com base nas APIs ricas do Solr (muito comuns). Você pode conectar sua ferramenta de terceiros favorita, como Qlik, Tableau, etc., por meio de suas conexões Solr certificadas. Você pode usar o painel solr simples do Hue para criar aplicativos de protótipo.
Para fazer o último:
1. Vá para Matiz.

2. Na visualização do painel, navegue até o arquivo de índice de sua escolha (por exemplo, aquele que você acabou de criar).
3. Comece a arrastar e soltar vários elementos do painel e selecione os campos do índice para preencher os dados do visual em questão.
Um vídeo tutorial rápido do painel do passado pode ser encontrado aqui, para inspiração.
Deixaremos um mergulho mais profundo para uma futura postagem no blog.
Resumo
Esperamos que você tenha aprendido muito com esta postagem do blog sobre como obter dados no S3 indexados pelo Solr em um DDE usando a ferramenta Crunch Indexer. É claro que existem muitas outras maneiras (Spark na experiência de Engenharia de Dados, Nifi na experiência de Fluxo de Dados, Kafka na experiência de Gerenciamento de Fluxo e assim por diante), mas essas serão abordadas em futuras postagens do blog. Esperamos que você tenha muito sucesso em sua jornada contínua na criação de aplicativos de insights poderosos envolvendo texto e outros dados não estruturados. Se você decidir experimentar o DDE no CDP, por favor, deixe-nos saber como tudo correu!



