Garantir o bom funcionamento de seus bancos de dados de produção não é uma tarefa trivial, e há várias ferramentas e utilitários para ajudar nesse trabalho. Existem ferramentas disponíveis para monitoramento de integridade, desempenho do servidor, análise de consultas, implantações, gerenciamento de failover, atualizações e a lista continua. O ClusterControl como plataforma de gerenciamento e monitoramento para sua infraestrutura de banco de dados se destaca por sua capacidade de gerenciar todo o ciclo de vida, desde a implantação até o monitoramento, gerenciamento contínuo e dimensionamento.
Embora o ClusterControl ofereça recursos importantes como failover automático de banco de dados, criptografia em trânsito/em repouso, gerenciamento de backup, recuperação pontual, integração Prometheus, dimensionamento de banco de dados, eles podem ser encontrados em outras ferramentas de gerenciamento/monitoramento empresarial no mercado. No entanto, existem alguns recursos que você não encontrará facilmente. Neste post do blog, apresentaremos 9 recursos que você não encontrará em nenhuma outra ferramenta de gerenciamento e monitoramento do mercado (como no momento da redação deste artigo).
Verificação de backup
Qualquer backup não é literalmente um backup até que você saiba que pode ser recuperado - verificando realmente se pode ser recuperado. O ClusterControl permite que um backup seja verificado após o backup ter sido feito, girando um novo servidor e testando a restauração. A verificação de um backup é um processo crítico para garantir que você cumpra sua política de Objetivo de Ponto de Recuperação (RPO) em caso de recuperação de desastres. O processo de verificação realizará a restauração em um novo host autônomo (onde o ClusterControl instalará os pacotes de banco de dados necessários antes da restauração) ou em um servidor dedicado para verificação de backup.
Para configurar a verificação de backup, basta selecionar um backup existente e clicar em Restaurar. Haverá uma opção para Restaurar e Verificar:
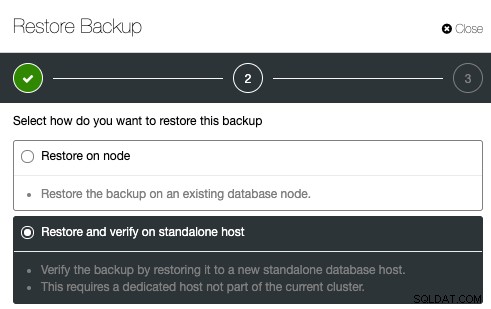
Em seguida, basta especificar o endereço IP do servidor que você deseja restaurar e verificar:
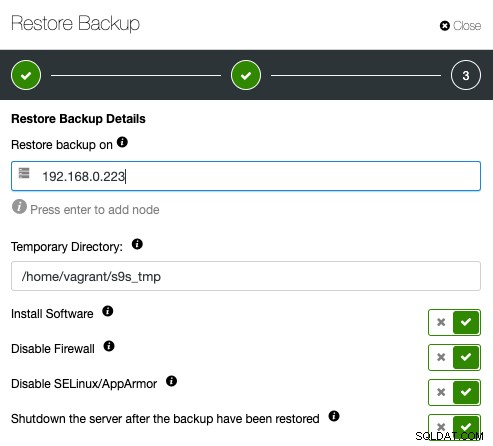
Certifique-se de que o host especificado esteja acessível via SSH sem senha com antecedência. Você também tem algumas opções abaixo para o processo de provisionamento. Você também pode desligar o servidor de verificação após a restauração para economizar custos e recursos após a verificação do backup. O ClusterControl procurará o código de saída do processo de restauração e observará o log de restauração para verificar se a verificação falha ou é bem-sucedida.
Simplificando o gerenciamento do ProxySQL por meio de uma GUI
Muitos concordam que ter uma interface gráfica de usuário é mais eficiente e menos propenso a erros humanos ao configurar um sistema. O ProxySQL faz parte da camada crítica do banco de dados (embora fique em cima dela) e deve ser visível o suficiente aos olhos do DBA para identificar problemas e questões comuns. O ClusterControl fornece uma interface gráfica de usuário abrangente para ProxySQL.
As instâncias do ProxySQL podem ser implantadas em novos hosts ou as existentes podem ser importadas para o ClusterControl. O ClusterControl pode configurar o ProxySQL para ser integrado a um endereço IP virtual (fornecido pelo Keepalived) para acesso de terminal único aos servidores de banco de dados. Ele também fornece informações de monitoramento para os principais componentes do ProxySQL, como o back-end de consultas, consultas lentas, consultas principais, ocorrências de consulta e várias outras estatísticas de monitoramento. Veja a seguir uma captura de tela mostrando como adicionar uma nova regra de consulta:
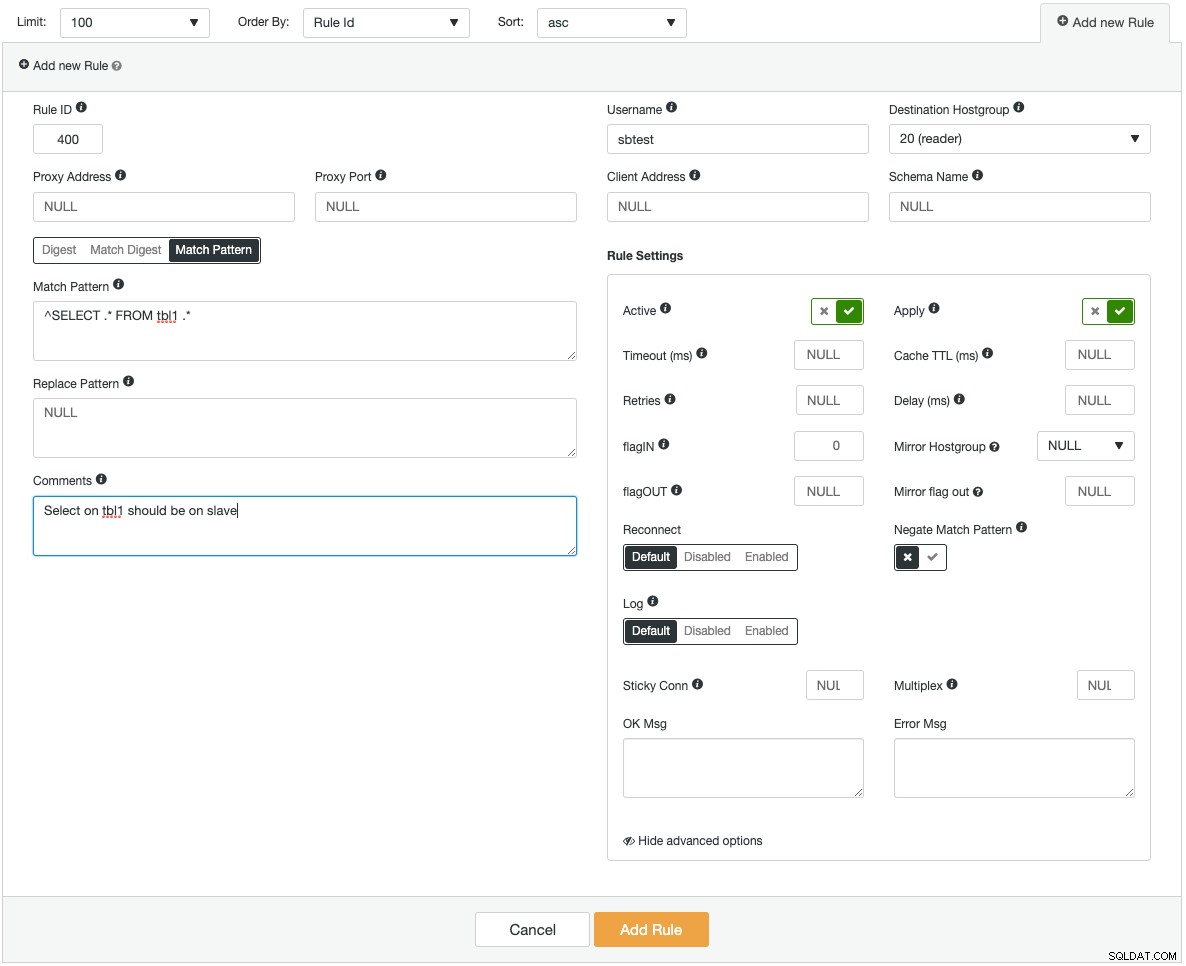
Se você estivesse adicionando uma regra de consulta muito complexa, ficaria mais confortável fazendo isso por meio da interface gráfica do usuário. Cada campo tem uma dica de ferramenta para auxiliá-lo no preenchimento do formulário Regra de consulta. Ao adicionar ou modificar qualquer configuração do ProxySQL, o ClusterControl garantirá que as alterações sejam feitas no tempo de execução e salvas no disco para persistência.
ClusterControl 1.7.4 agora suporta ProxySQL 1.xe ProxySQL 2.x.
Relatórios operacionais
Relatórios Operacionais são um conjunto de relatórios resumidos de sua infraestrutura de banco de dados que podem ser gerados dinamicamente ou podem ser programados para serem enviados a diferentes destinatários. Esses relatórios consistem em diferentes verificações e abordam várias tarefas diárias do DBA. A ideia por trás do relatório operacional do ClusterControl é colocar todos os dados mais relevantes em um único documento que pode ser analisado rapidamente para obter uma compreensão clara do status dos bancos de dados e seus processos.
Com o ClusterControl, você pode agendar relatórios de ambiente entre clusters, como Relatório Diário do Sistema, Relatório de Atualização de Pacote, Relatório de Alteração de Esquema, bem como Backups e Disponibilidade. Esses relatórios ajudarão você a manter seu ambiente seguro e operacional. Você também verá recomendações sobre como corrigir lacunas. Os relatórios podem ser endereçados a SysOps, DevOps ou mesmo a gerentes que gostariam de receber atualizações regulares de status sobre a integridade de um determinado sistema.
Veja a seguir um exemplo de relatório operacional diário enviado para sua caixa de correio em relação à disponibilidade:
Cobrimos isso em detalhes nesta postagem de blog, Uma visão geral do relatório operacional de banco de dados no ClusterControl.
Ressincronize um escravo via backup
ClusterControl permite preparar um escravo (seja um novo escravo ou um escravo quebrado) por meio do último backup completo ou incremental. Não parece muito empolgante, mas esse recurso é enorme se você tiver grandes conjuntos de dados de 100 GB ou mais. A prática comum ao ressincronizar um escravo é transmitir um backup do mestre atual, o que levará algum tempo dependendo do tamanho do banco de dados. Isso adicionará um ônus adicional ao mestre, o que pode comprometer o desempenho do mestre.
Para ressincronizar um escravo via backup, escolha o nó escravo na página Nós e vá para Ações do nó -> Reconstruir escravo de replicação -> Reconstruir de um backup. Apenas o backup compatível com PITR será listado na lista suspensa:
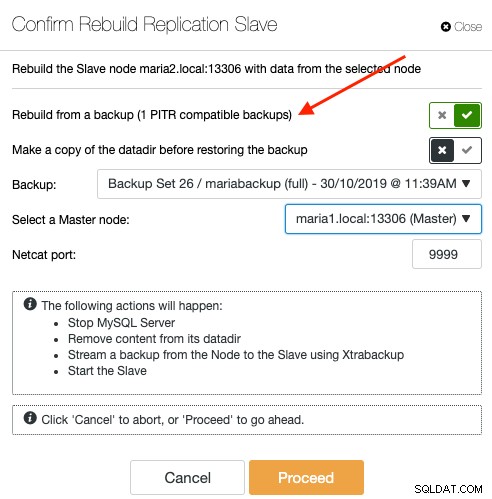
A ressincronização de um escravo de um backup não trará nenhuma sobrecarga adicional ao mestre, onde o ClusterControl extrai e transmite o backup do local de armazenamento de backup para o escravo e, eventualmente, configura o link de replicação entre o escravo e o mestre. O escravo mais tarde alcançará o mestre assim que o link de replicação for estabelecido. O mestre permanece intocado durante todo o processo e você pode monitorar todo o progresso em Atividade -> Trabalhos.
Inicializar um cluster Galera
O Galera Cluster é muito popular na implementação de alta disponibilidade para MySQL ou MariaDB, mas os comandos de gerenciamento errados podem levar a consequências desastrosas. Dê uma olhada neste post do blog sobre como inicializar um Galera Cluster sob diferentes condições. Isso ilustra que o bootstrap de um Galera Cluster tem muitas variáveis e deve ser realizado com extremo cuidado. Caso contrário, você pode perder dados ou causar um cérebro dividido. O ClusterControl entende a topologia do banco de dados e sabe exatamente o que fazer para inicializar um cluster de banco de dados corretamente. Para inicializar um cluster via ClusterControl, clique em Cluster Actions -> Bootstrap Cluster:
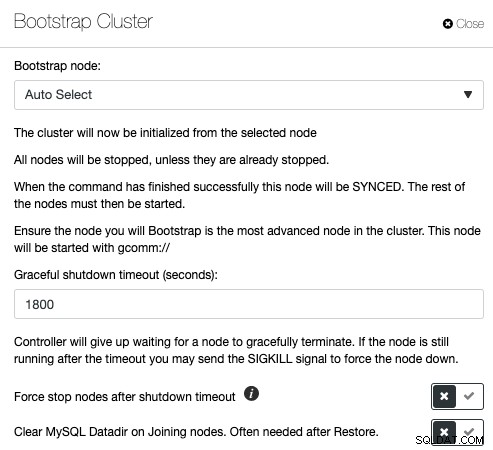
Você terá a opção de permitir que o ClusterControl escolha o nó de bootstrap correto automaticamente, ou execute um bootstrap inicial onde você escolhe um dos nós de banco de dados da lista para se tornar o nó de referência e apague o diretório de dados MySQL nos nós de junção para forçar o SST de o nó inicializado. Se o processo de bootstrap falhar, o ClusterControl puxará o log de erros do MySQL.
Se desejar executar uma inicialização manual, você também pode usar o recurso "Localizar o nó mais avançado" e executar a operação de inicialização do cluster no nó mais avançado relatado pelo ClusterControl.
Configuração e registro centralizados
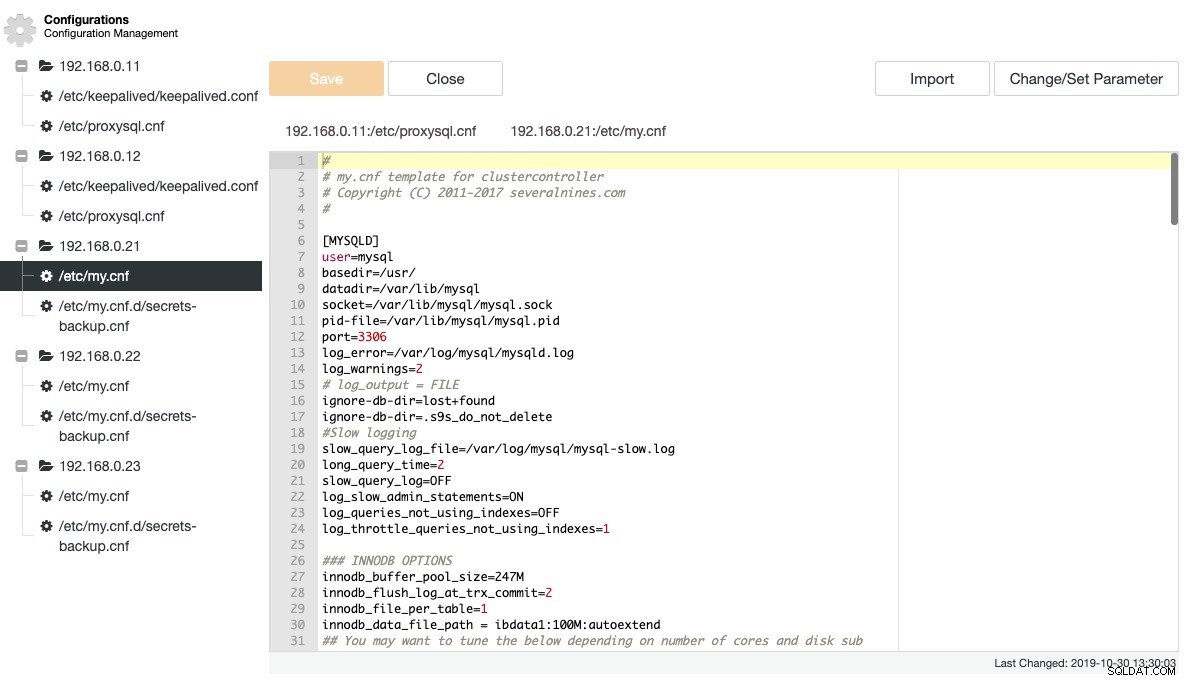
O ClusterControl extrai vários arquivos importantes de configuração e log e os exibe em uma estrutura de árvore dentro do ClusterControl. Uma visão centralizada desses arquivos é a chave para entender e solucionar problemas de configurações de banco de dados distribuído com eficiência. A maneira tradicional de seguir/grepar esses arquivos desapareceu há muito tempo com o ClusterControl. A captura de tela a seguir mostra o gerenciador de arquivos de configuração do ClusterControl que listou todos os arquivos de configuração relacionados para este cluster em uma única visualização (com destaque de sintaxe, é claro):
O ClusterControl elimina a repetitividade ao alterar uma opção de configuração de um cluster de banco de dados. A alteração de uma opção de configuração em vários nós pode ser realizada por meio de uma única interface e será aplicada ao nó do banco de dados de acordo. Ao clicar em "Alterar/Definir Parâmetro", você pode selecionar as instâncias do banco de dados que deseja alterar e especificar o grupo de configuração, parâmetro e valor:
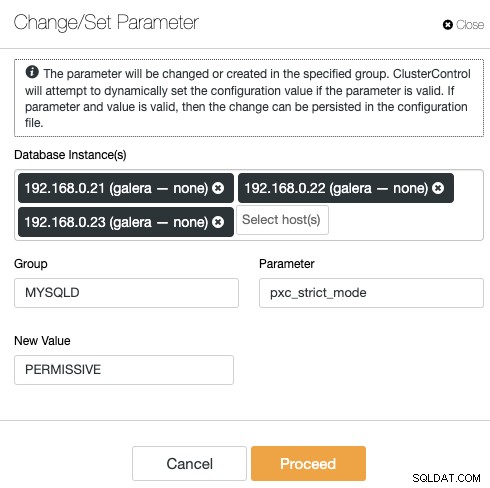
Você pode adicionar um novo parâmetro ao arquivo de configuração ou modificar um parâmetro existente . O parâmetro será aplicado ao tempo de execução dos nós de banco de dados escolhidos e no arquivo de configuração se a opção passar no processo de validação da variável. Alguma variável pode exigir uma reinicialização do servidor, que será avisada pelo ClusterControl.
Clonagem de cluster de banco de dados
Com o ClusterControl, você pode clonar rapidamente um cluster MySQL Galera existente para ter uma cópia exata do conjunto de dados no outro cluster. O ClusterControl executa a operação de clonagem online, sem nenhum bloqueio ou inatividade do cluster existente. É como uma operação de expansão de cluster, exceto que ambos os clusters são independentes um do outro após a conclusão da sincronização. O cluster clonado não precisa necessariamente ter o mesmo tamanho de cluster que o existente. Poderíamos começar com um “cluster de um nó” e escalá-lo com mais nós de banco de dados em um estágio posterior.
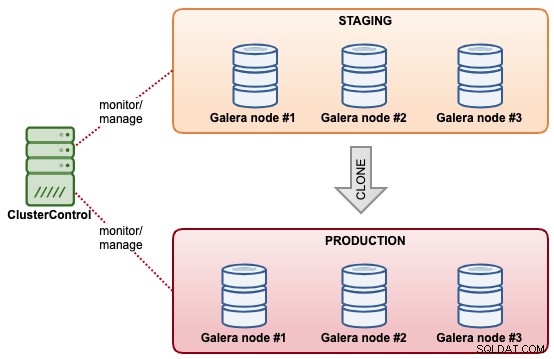
Outro recurso semelhante oferecido pelo ClusterControl é "Criar cluster a partir do backup". Este recurso foi introduzido no ClusterControl 1.7.1, especificamente para clusters Galera Cluster e PostgreSQL onde se pode criar um novo cluster a partir do backup existente. Ao contrário da clonagem de cluster, essa operação não traz carga adicional para o cluster de origem com a compensação de que o cluster clonado não estará no mesmo estado que o cluster de origem.
Cobrimos esse tópico em detalhes nesta postagem de blog, Como criar um clone do seu cluster de banco de dados MySQL ou PostgreSQL.
Restaurar backup físico
A maioria das ferramentas de gerenciamento de banco de dados permite fazer backup de um banco de dados, e apenas algumas delas suportam a restauração de banco de dados apenas de backup lógico. O ClusterControl suporta a restauração completa não apenas para backups lógicos, mas também para backups físicos, seja um backup completo ou incremental. A restauração de um backup físico requer uma série de etapas críticas (especialmente backups incrementais) que basicamente envolvem a preparação de um backup, a cópia dos dados preparados no diretório de dados, a atribuição de permissão/propriedade correta e a inicialização do nó na ordem correta para manter a consistência dos dados entre todos os membros do cluster. O ClusterControl executa todas essas operações automaticamente.
Você também pode restaurar um backup físico em outro nó que não faça parte de um cluster. No ClusterControl, a opção para isso é chamada de "Criar cluster do backup". Você pode começar com um “cluster de um nó” para testar o processo de restauração em outro servidor ou copiar seu cluster de banco de dados para outro local.
O ClusterControl também suporta a restauração de um backup externo, um backup que não foi feito através do ClusterControl. Você só precisa carregar o backup para o servidor ClusterControl e especificar o caminho físico para o arquivo de backup ao restaurar. O ClusterControl cuidará do resto.
Replicação de cluster para cluster
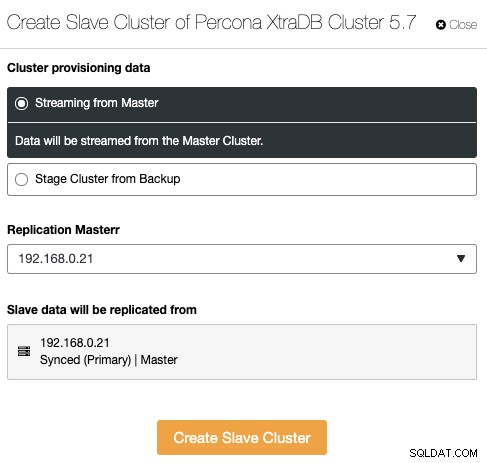
Este é um novo recurso introduzido no ClusterControl 1.7.4. O ClusterControl agora pode manipular e monitorar a replicação de cluster-cluster, que basicamente estende a replicação de banco de dados assíncrona entre vários conjuntos de cluster em vários locais geográficos. Um cluster pode ser definido como um cluster mestre (cluster ativo que processa leituras/gravações) e o cluster escravo pode ser definido como um cluster somente leitura (cluster de espera que também processa leituras). O ClusterControl suporta replicação cluster-cluster assíncrona para Galera Cluster (o log binário deve estar habilitado) e também replicação master-slave para PostgreSQL Streaming Replication.
Para criar um novo cluster as replicas de outro cluster, vá para Cluster Actions -> Create Slave Cluster:
O resultado da implantação acima é apresentado claramente no painel Database Cluster List :
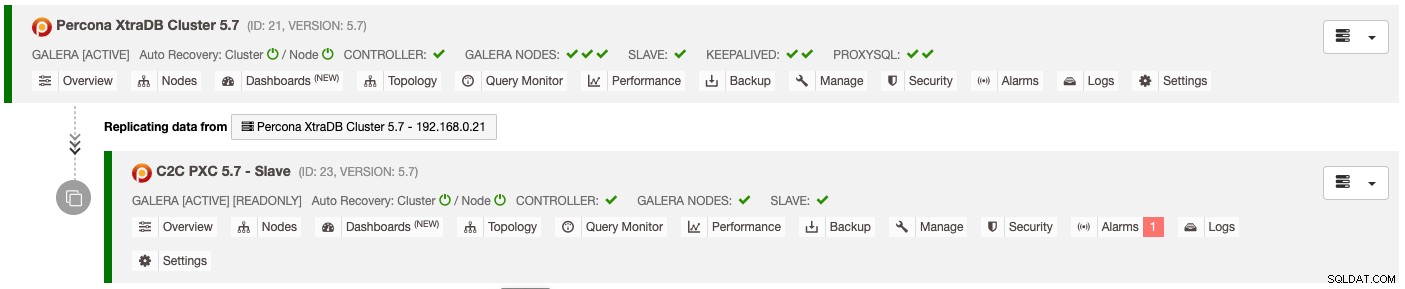
O cluster escravo é configurado automaticamente como somente leitura, replicando do cluster primário e atuando como um cluster em espera. Se ocorrer um desastre no cluster primário e você quiser ativar o site secundário, basta escolher o menu "Desativar somente leitura" disponível na lista suspensa Nós -> Ações do nó para promovê-lo como um cluster ativo.



