Até agora, abordamos a introdução do Hadoop e Hadoop HDFS em detalhe. Neste tutorial, forneceremos uma descrição detalhada do Hadoop Reducer.
Aqui discutiremos o que é Reducer no MapReduce, como o Reducer funciona no Hadoop MapReduce, diferentes fases do Hadoop Reducer, como podemos alterar o número de Reducer no Hadoop MapReduce.
O que é o Hadoop Reducer?
Redutor no Hadoop MapReduce reduz um conjunto de valores intermediários que compartilham uma chave para um conjunto menor de valores.
No fluxo de execução do trabalho MapReduce, o Reducer pega um conjunto de um par de chave-valor intermediário produzido pelo mapeador como a entrada. Em seguida, o Reducer agrega, filtra e combina pares de valores-chave e isso requer uma ampla gama de processamento.
O mapeamento um-um ocorre entre chaves e redutores na execução do trabalho MapReduce. Eles correm em paralelo, pois são independentes um do outro. O usuário decide o número de redutores no MapReduce.
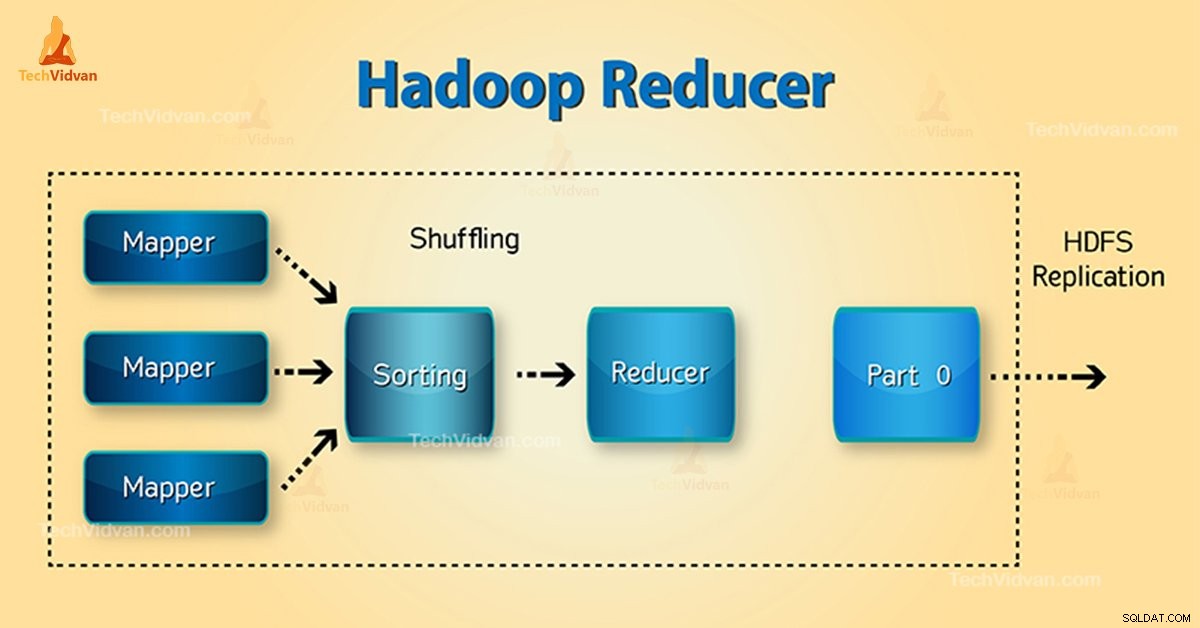
Fases do Redutor Hadoop
Três fases do Redutor são as seguintes:
1. Fase de embaralhamento
Esta é a fase em que a saída classificada do mapeador é a entrada para o redutor. A estrutura com a ajuda de HTTP busca a partição relevante da saída de todos os mapeadores nesta fase. Fase de classificação
2. Fase de classificação
Esta é a fase na qual a entrada de diferentes mapeadores é novamente classificada com base nas chaves semelhantes em diferentes mapeadores.
Ambos Shuffle e Sort ocorrem simultaneamente.
3. Reduzir Fase
Esta fase ocorre após embaralhar e classificar. A tarefa de redução agrega os pares de chave-valor. Com o OutputCollector.collect() propriedade, a saída da tarefa de redução é gravada no FileSystem. A saída do redutor não é classificada.
Número de redutores no Hadoop MapReduce
O usuário define o número de redutores com a ajuda de Job.setNumreduceTasks(int) propriedade. Assim, o número certo de redutores pela fórmula:
0,95 ou 1,75 multiplicado por (
Assim, com 0,95, todos os redutores são lançados imediatamente. Em seguida, comece a transferir as saídas do mapa assim que os mapas terminarem.
O nó mais rápido termina a primeira rodada de redutores com 1,75. Em seguida, ele lança a segunda onda de redutor que faz um trabalho muito melhor de balanceamento de carga.
Com o aumento do número de redutores:
- A sobrecarga da estrutura aumenta.
- O balanceamento de carga aumenta.
- O custo das falhas diminui.
Conclusão
Portanto, o Reducer recebe a saída dos mapeadores como entrada. Em seguida, processe os pares chave-valor e produza a saída. A saída do redutor é a saída final. Se você gosta deste blog ou tem alguma dúvida relacionada ao Hadoop Reducer, compartilhe conosco deixando um comentário.
Espero que possamos ajudá-lo.



