O Apache Hadoop é uma estrutura de software que processa e armazena big data em todo o cluster de hardware comum. O Hadoop é baseado no modelo MapReduce para processar grandes quantidades de dados de maneira distribuída.
Este Tutorial do MapReduce listou vários recursos do MapReduce. Depois de ler isso, você entenderá claramente por que o MapReduce é o mais adequado para processar grandes quantidades de dados.
Primeiro, veremos uma pequena introdução ao framework MapReduce. Em seguida, exploraremos vários recursos do MapReduce.
Vamos começar com a introdução ao framework MapReduce.
Introdução ao MapReduce
MapReduce é uma estrutura de software para escrever aplicativos que podem processar grandes quantidades de dados em clusters de nós caros. Hadoop MapReduce é a parte de processamento do Apache Hadoop.
Também é conhecido como o coração do Hadoop. É o aplicativo de processamento de dados mais preferido. Vários players do setor de comércio eletrônico, como Amazon, Yahoo e Zuventus, etc., estão usando a estrutura MapReduce para processamento de dados de alto volume.
Vamos agora estudar os vários recursos do Hadoop MapReduce.
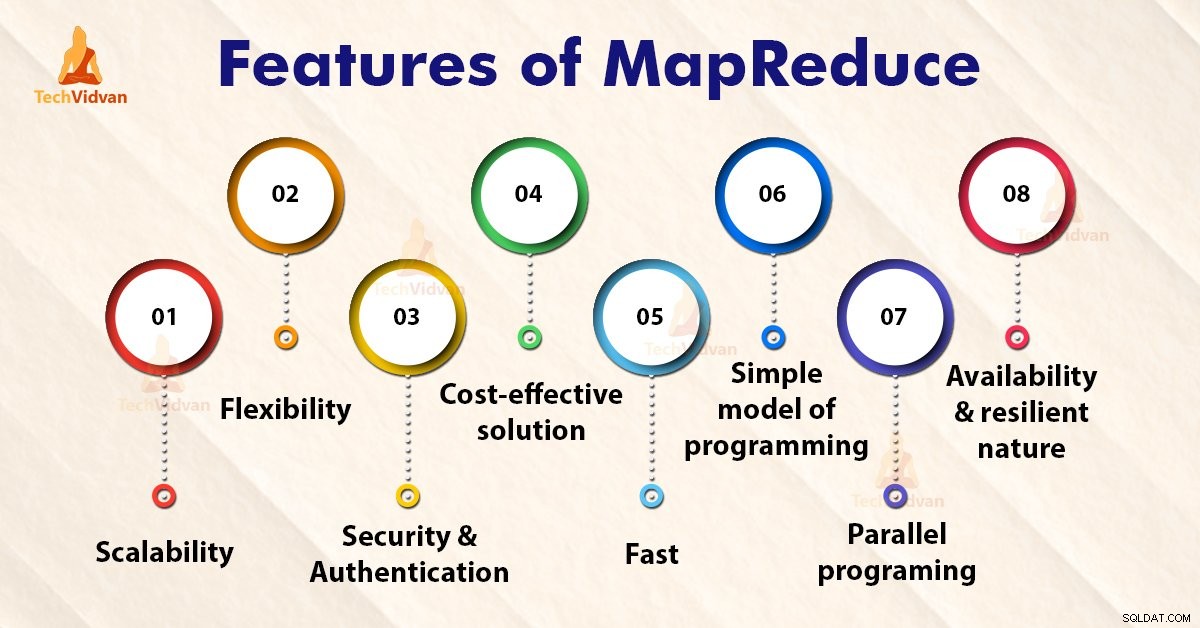
Recursos do MapReduce
1. Escalabilidade
O Apache Hadoop é uma estrutura altamente escalável. Isso se deve à sua capacidade de armazenar e distribuir grandes dados em vários servidores. Todos esses servidores eram baratos e podiam operar em paralelo. Podemos dimensionar facilmente o poder de armazenamento e computação adicionando servidores ao cluster.
A programação Hadoop MapReduce permite que as organizações executem aplicativos a partir de grandes conjuntos de nós que podem envolver o uso de milhares de terabytes de dados.
A programação Hadoop MapReduce permite que as organizações de negócios executem aplicativos a partir de grandes conjuntos de nós. Isso pode usar milhares de terabytes de dados.
2. Flexibilidade
A programação MapReduce permite que as empresas acessem novas fontes de dados. Ele permite que as empresas operem em diferentes tipos de dados. Ele permite que as empresas acessem dados estruturados e não estruturados e obtenham valor significativo ao obter insights de várias fontes de dados.
Além disso, a estrutura MapReduce também oferece suporte para vários idiomas e dados de fontes que variam de e-mail, mídia social a fluxo de cliques.
O MapReduce processa dados em pares de valores-chave simples, portanto, suporta tipos de dados, incluindo metadados, imagens e arquivos grandes. Portanto, o MapReduce é flexível para lidar com dados em vez do DBMS tradicional.
3. Segurança e autenticação
O modelo de programação MapReduce utiliza a plataforma de segurança HBase e HDFS que permite o acesso apenas aos usuários autenticados para operar nos dados. Assim, protege o acesso não autorizado aos dados do sistema e aumenta a segurança do sistema.
4. Solução econômica
A arquitetura escalável do Hadoop com a estrutura de programação MapReduce permite o armazenamento e processamento de grandes conjuntos de dados de maneira muito acessível.
5. Rápido
O Hadoop usa um método de armazenamento distribuído chamado Hadoop Distributed File System que basicamente implementa um sistema de mapeamento para localizar dados em um cluster.
As ferramentas usadas para processamento de dados, como a programação MapReduce, geralmente estão localizadas nos mesmos servidores que permitem o processamento mais rápido dos dados.
Portanto, mesmo que estejamos lidando com grandes volumes de dados não estruturados, o Hadoop MapReduce leva apenas alguns minutos para processar terabytes de dados. Ele pode processar petabytes de dados em apenas uma hora.
6. Modelo simples de programação
Entre os vários recursos do Hadoop MapReduce, um dos recursos mais importantes é que ele é baseado em um modelo de programação simples. Basicamente, isso permite que os programadores desenvolvam os programas MapReduce que podem lidar com tarefas de maneira fácil e eficiente.
Os programas MapReduce podem ser escritos em Java, que não é muito difícil de entender e também é amplamente utilizado. Assim, qualquer pessoa pode aprender e escrever facilmente programas MapReduce e atender às suas necessidades de processamento de dados.
7. Programação paralela
Um dos principais aspectos do funcionamento da programação MapReduce é seu processamento paralelo. Ele divide as tarefas de forma a permitir sua execução em paralelo.
O processamento paralelo permite que vários processadores executem essas tarefas divididas. Assim, todo o programa é executado em menos tempo.
8. Disponibilidade e natureza resiliente
Sempre que os dados são enviados para um nó individual, o mesmo conjunto de dados é encaminhado para alguns outros nós em um cluster. Portanto, se algum nó específico sofrer uma falha, sempre haverá outras cópias presentes em outros nós que ainda poderão ser acessadas sempre que necessário. Isso garante alta disponibilidade de dados.
Um dos principais recursos oferecidos pelo Apache Hadoop é sua tolerância a falhas. A estrutura Hadoop MapReduce tem a capacidade de reconhecer rapidamente as falhas que ocorrem.
Em seguida, aplica uma solução de recuperação rápida e automática. Esse recurso o torna um divisor de águas no mundo do processamento de big data.
Resumo
Espero que depois de ler este artigo você tenha entendido claramente os vários recursos do Hadoop MapReduce. O artigo listou vários recursos do MapReduce. A estrutura MapReduce é um sistema de processamento escalável, flexível, econômico e rápido.
Oferece segurança, tolerância a falhas e autenticação. MapReduce é um modelo simples de programação e oferece programação paralela.



