Esta receita usará a classe MongoOutputFormat para carregar dados de uma instância HDFS em uma coleção do MongoDB.
Getting ready
A maneira mais fácil de começar com o Mongo Hadoop Adapter é clonar o Mongo-Hadoopproject do GitHub e construir o projeto configurado para uma versão específica do Hadoop. Um Gitclient deve ser instalado para clonar este projeto. Esta receita pressupõe que você esteja usando a distribuição CDH3 do Hadoop. O Git Client oficial pode ser encontrado em https://git-scm.com/downloads .
O Adaptador Mongo Hadoop pode ser encontrado no GitHub em https://github.com/mongodb/ mongo-hadoop. Este projeto precisa ser construído para uma versão específica do Hadoop. O arquivo JAR resultante deve ser instalado em cada nó na pasta $HADOOP_HOME/lib. O Mongo Java Driver deve ser instalado em cada nó na pasta $HADOOP_HOME/lib. Ele pode ser encontrado em https://github.com/mongodb/mongo-java-driver / Transferências .
Como fazer isso...
Complete the following steps to copy data form HDFS into MongoDB:
1. Clone the mongo-hadoop repository with the following command line:
git clone https://github.com/mongodb/mongo-hadoop.git
2. Switch to the stable release 1.0 branch:
git checkout release-1.0
3. Set the Hadoop version which mongo-hadoop should target. In the folder
that mongo-hadoop was cloned to, open the build.sbt file with a text editor.
Change the following line:
hadoopRelease in ThisBuild := "default"
to
hadoopRelease in ThisBuild := "cdh3"
4. Build mongo-hadoop :
./sbt package
This will create a file named mongo-hadoop-core_cdh3u3-1.0.0.jar in the
core/target folder.
5. Download the MongoDB Java Driver Version 2.8.0 from https://github.com/
mongodb/mongo-java-driver/downloads .
6. Copy mongo-hadoop and the MongoDB Java Driver to $HADOOP_HOME/lib on
each node:
cp mongo-hadoop-core_cdh3u3-1.0.0.jar mongo-2.8.0.jar $HADOOP_
HOME/lib
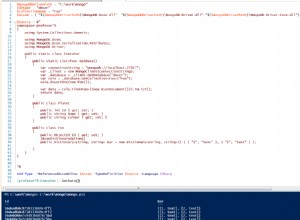
7. Create a Java MapReduce program that will read the weblog_entries.txt file
from HDFS and write them to MongoDB using the MongoOutputFormat class:
import java.io.*;
import org.apache.commons.logging.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.*;
import org.bson.*;
import org.bson.types.ObjectId;
import com.mongodb.hadoop.*;
import com.mongodb.hadoop.util.*;
public class ExportToMongoDBFromHDFS {
private static final Log log = LogFactory.getLog(ExportToMongoDBFromHDFS.class);
public static class ReadWeblogs extends Mapper<LongWritable, Text, ObjectId, BSONObject>{
public void map(Text key, Text value, Context context)
throws IOException, InterruptedException{
System.out.println("Key: " + key);
System.out.println("Value: " + value);
String[] fields = value.toString().split("\t");
String md5 = fields[0];
String url = fields[1];
String date = fields[2];
String time = fields[3];
String ip = fields[4];
BSONObject b = new BasicBSONObject();
b.put("md5", md5);
b.put("url", url);
b.put("date", date);
b.put("time", time);
b.put("ip", ip);
context.write( new ObjectId(), b);
}
}
public static void main(String[] args) throws Exception{
final Configuration conf = new Configuration();
MongoConfigUtil.setOutputURI(conf,"mongodb://<HOST>:<PORT>/test. weblogs");
System.out.println("Configuration: " + conf);
final Job job = new Job(conf, "Export to Mongo");
Path in = new Path("/data/weblogs/weblog_entries.txt");
FileInputFormat.setInputPaths(job, in);
job.setJarByClass(ExportToMongoDBFromHDFS.class);
job.setMapperClass(ReadWeblogs.class);
job.setOutputKeyClass(ObjectId.class);
job.setOutputValueClass(BSONObject.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(MongoOutputFormat.class);
job.setNumReduceTasks(0);
System.exit(job.waitForCompletion(true) ? 0 : 1 );
}
}
8. Export as a runnable JAR file and run the job:
hadoop jar ExportToMongoDBFromHDFS.jar
9. Verify that the weblogs MongoDB collection was populated from the Mongo shell:
db.weblogs.find();