Uma das maiores preocupações ao lidar e gerenciar bancos de dados é sua complexidade de dados e tamanho. Muitas vezes, as organizações se preocupam em como lidar com o crescimento e gerenciar o impacto do crescimento porque o gerenciamento do banco de dados falha. A complexidade vem com preocupações que não foram abordadas inicialmente e não foram vistas, ou podem ser negligenciadas porque a tecnologia que está sendo usada atualmente será capaz de lidar sozinha. O gerenciamento de um banco de dados complexo e grande deve ser planejado de acordo, especialmente quando se espera que o tipo de dados que você está gerenciando ou manipulando cresça massivamente de maneira antecipada ou imprevisível. O principal objetivo do planejamento é evitar desastres indesejados, ou, digamos, evitar a fumaça! Neste blog, abordaremos como gerenciar bancos de dados grandes com eficiência.
Tamanho dos dados importa
O tamanho do banco de dados é importante, pois afeta o desempenho e sua metodologia de gerenciamento. A forma como os dados são processados e armazenados contribuirá para como o banco de dados será gerenciado, o que se aplica tanto a dados em trânsito quanto em repouso. Para muitas grandes organizações, os dados são ouro, e o crescimento dos dados pode ter uma mudança drástica no processo. Portanto, é vital ter planos prévios para lidar com dados crescentes em um banco de dados.
Na minha experiência trabalhando com bancos de dados, testemunhei clientes tendo problemas ao lidar com penalidades de desempenho e gerenciar o crescimento extremo de dados. Surgem dúvidas sobre a normalização das tabelas versus a desnormalização das tabelas.
Normalização de tabelas
A normalização de tabelas mantém a integridade dos dados, reduz a redundância e facilita a organização dos dados de forma mais eficiente para gerenciar, analisar e extrair. Trabalhar com tabelas normalizadas gera eficiência, especialmente ao analisar o fluxo de dados e recuperar dados por meio de instruções SQL ou ao trabalhar com linguagens de programação como C/C++, Java, Go, Ruby, PHP ou interfaces Python com os conectores MySQL.
Embora as preocupações com tabelas normalizadas possuam penalidade de desempenho e possam retardar as consultas devido a séries de junções ao recuperar os dados. Enquanto as tabelas desnormalizadas, tudo o que você precisa considerar para otimização depende do índice ou da chave primária para armazenar dados no buffer para uma recuperação mais rápida do que realizar buscas em vários discos. As tabelas desnormalizadas não requerem junções, mas sacrificam a integridade dos dados e o tamanho do banco de dados tende a ficar cada vez maior.
Quando seu banco de dados for grande, considere ter um DDL (Data Definition Language) para sua tabela de banco de dados no MySQL/MariaDB. Adicionar uma chave primária ou exclusiva à sua tabela requer uma reconstrução da tabela. A alteração de um tipo de dados de coluna também requer uma reconstrução de tabela, pois o algoritmo aplicável a ser aplicado é apenas ALGORITHM=COPY.
Se você estiver fazendo isso em seu ambiente de produção, pode ser um desafio. Duplique o desafio se sua mesa for enorme. Imagine um milhão ou um bilhão de números de linhas. Você não pode aplicar uma instrução ALTER TABLE diretamente à sua tabela. Isso pode bloquear todo o tráfego de entrada que precisa acessar a tabela atualmente em que você está aplicando o DDL. No entanto, isso pode ser mitigado usando pt-online-schema-change ou o great gh-ost. No entanto, requer monitoramento e manutenção durante o processo de DDL.
Fragmentação e particionamento
Com sharding e particionamento, ajuda a segregar ou segmentar os dados de acordo com sua identidade lógica. Por exemplo, segregando com base na data, ordem alfabética, país, estado ou chave primária com base no intervalo fornecido. Isso ajuda o tamanho do banco de dados a ser gerenciável. Mantenha o tamanho do seu banco de dados até o limite que seja gerenciável para sua organização e sua equipe. Fácil de dimensionar, se necessário, ou fácil de gerenciar, especialmente quando ocorre um desastre.
Quando dizemos gerenciável, considere também os recursos de capacidade de seu servidor e também de sua equipe de engenharia. Você não pode trabalhar com grandes e grandes dados com poucos engenheiros. Trabalhar com big data, como 1.000 bancos de dados com um grande número de conjuntos de dados, requer uma grande demanda de tempo. Habilidade sábia e experiência é uma obrigação. Se o custo for um problema, esse é o momento em que você pode aproveitar os serviços de terceiros que oferecem serviços gerenciados ou consultoria paga ou suporte para que qualquer trabalho de engenharia seja atendido.
Conjuntos de caracteres e agrupamento
Conjuntos de caracteres e agrupamentos afetam o armazenamento de dados e o desempenho, especialmente no conjunto de caracteres e agrupamentos selecionados. Cada conjunto de caracteres e agrupamentos tem sua finalidade e geralmente requer comprimentos diferentes. Se você tiver tabelas que exigem outros conjuntos de caracteres e agrupamentos devido à codificação de caracteres, os dados serão armazenados e processados para seu banco de dados e tabelas ou até mesmo com colunas.
Isso afeta como gerenciar seu banco de dados de forma eficaz. Isso afeta seu armazenamento de dados e também o desempenho, conforme declarado anteriormente. Se você entendeu os tipos de caracteres a serem processados pelo seu aplicativo, anote o conjunto de caracteres e os agrupamentos a serem usados. Os conjuntos de caracteres do tipo LATIN devem ser suficientes principalmente para o tipo de caracteres alfanuméricos a serem armazenados e processados.
Se for inevitável, a fragmentação e o particionamento ajudam a pelo menos mitigar e limitar os dados para evitar o excesso de dados no servidor de banco de dados. Gerenciar dados muito grandes em um único servidor de banco de dados pode afetar a eficiência, especialmente para fins de backup, desastres e recuperação ou recuperação de dados, bem como em caso de corrupção ou perda de dados.
A complexidade do banco de dados afeta o desempenho
Um banco de dados grande e complexo tende a ter um fator quando se trata de penalidade de desempenho. Complexo, neste caso, significa que o conteúdo do seu banco de dados consiste em equações matemáticas, coordenadas ou registros numéricos e financeiros. Agora misture esses registros com consultas que estão usando agressivamente as funções matemáticas nativas de seu banco de dados. Dê uma olhada no exemplo de consulta SQL (compatível com MySQL/MariaDB) abaixo,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Considere que esta consulta é aplicada em uma tabela que varia de um milhão de linhas. Há uma grande possibilidade de que isso possa travar o servidor e pode consumir muitos recursos, causando perigo à estabilidade do cluster de banco de dados de produção. As colunas envolvidas tendem a ser indexadas para otimizar e tornar essa consulta eficiente. No entanto, adicionar índices às colunas referenciadas para obter um desempenho ideal não garante a eficiência do gerenciamento de bancos de dados grandes.
Ao lidar com a complexidade, a maneira mais eficiente é evitar o uso rigoroso de equações matemáticas complexas e o uso agressivo dessa capacidade computacional complexa integrada. Isso pode ser operado e transportado por meio de cálculos complexos usando linguagens de programação de back-end em vez de usar o banco de dados. Se você tem cálculos complexos, então por que não armazenar essas equações no banco de dados, recuperar as consultas, organizá-las de forma mais fácil de analisar ou depurar quando necessário.
Você está usando o mecanismo de banco de dados correto?
Uma estrutura de dados afeta o desempenho do servidor de banco de dados com base na combinação da consulta fornecida e os registros que são lidos ou recuperados da tabela. Os mecanismos de banco de dados dentro do MySQL/MariaDB suportam InnoDB e MyISAM que usam B-Trees, enquanto os mecanismos de banco de dados NDB ou Memory usam Hash Mapping. Essas estruturas de dados têm sua notação assintótica que expressa o desempenho dos algoritmos utilizados por essas estruturas de dados. Chamamos isso em Ciência da Computação como notação Big O que descreve o desempenho ou complexidade de um algoritmo. Dado que o InnoDB e o MyISAM usam B-Trees, ele usa O(log n) para pesquisa. Considerando que, Hash Tables ou Hash Maps usa O(n). Ambos compartilham a média e o pior caso para seu desempenho com sua notação.
Agora de volta ao mecanismo específico, dada a estrutura de dados do mecanismo, a consulta a ser aplicada com base nos dados de destino a serem recuperados afeta o desempenho do seu servidor de banco de dados. As tabelas de hash não podem fazer recuperação de intervalo, enquanto o B-Trees é muito eficiente para fazer esses tipos de pesquisas e também pode lidar com grandes quantidades de dados.
Usando o mecanismo certo para os dados que você armazena, você precisa identificar que tipo de consulta você aplica para esses dados específicos armazenados. Que tipo de lógica esses dados devem formular quando se transformam em uma lógica de negócios.
Lidar com milhares ou milhares de bancos de dados, usando o mecanismo certo em combinação de suas consultas e dados que você deseja recuperar e armazenar, proporcionará um bom desempenho. Dado que você predeterminou e analisou seus requisitos para sua finalidade para o ambiente de banco de dados correto.
Ferramentas certas para gerenciar grandes bancos de dados
É muito difícil gerenciar um banco de dados muito grande sem uma plataforma sólida na qual você possa confiar. Mesmo com engenheiros de banco de dados bons e qualificados, tecnicamente o servidor de banco de dados que você está usando é propenso a erros humanos. Um erro de qualquer alteração nos parâmetros e variáveis de configuração pode resultar em uma mudança drástica, causando a degradação do desempenho do servidor.
A execução de backup em seu banco de dados em um banco de dados muito grande pode ser um desafio às vezes. Há ocorrências em que o backup pode falhar por alguns motivos estranhos. Geralmente, as consultas que podem travar o servidor em que o backup está sendo executado causam falha. Caso contrário, você deve investigar a causa disso.
O uso de automação como Chef, Puppet, Ansible, Terraform ou SaltStack pode ser usado como seu IaC para fornecer tarefas mais rápidas. Ao usar outras ferramentas de terceiros também para ajudá-lo a monitorar e fornecer imagens gráficas de alta qualidade. Os sistemas de notificação de alertas e alarmes também são muito importantes para notificá-lo sobre problemas que podem ocorrer desde o nível de alerta até o estado crítico. É aqui que o ClusterControl é muito útil nesse tipo de situação.
ClusterControl oferece facilidade para gerenciar um grande número de bancos de dados ou mesmo com tipos de ambientes fragmentados. Ele foi testado e instalado milhares de vezes e está em produção fornecendo alarmes e notificações para DBAs, engenheiros ou DevOps que operam o ambiente de banco de dados. Variando de preparação ou desenvolvimento, QAs, para ambiente de produção.
O ClusterControl também pode realizar um backup e uma restauração. Mesmo com grandes bancos de dados, pode ser eficiente e fácil de gerenciar, pois a interface do usuário fornece agendamento e também possui opções para carregá-lo na nuvem (AWS, Google Cloud e Azure).
Há também uma verificação de backup e muitas opções, como criptografia e compactação. Veja a captura de tela abaixo por exemplo (criando um Backup para MySQL usando o Xtrabackup):
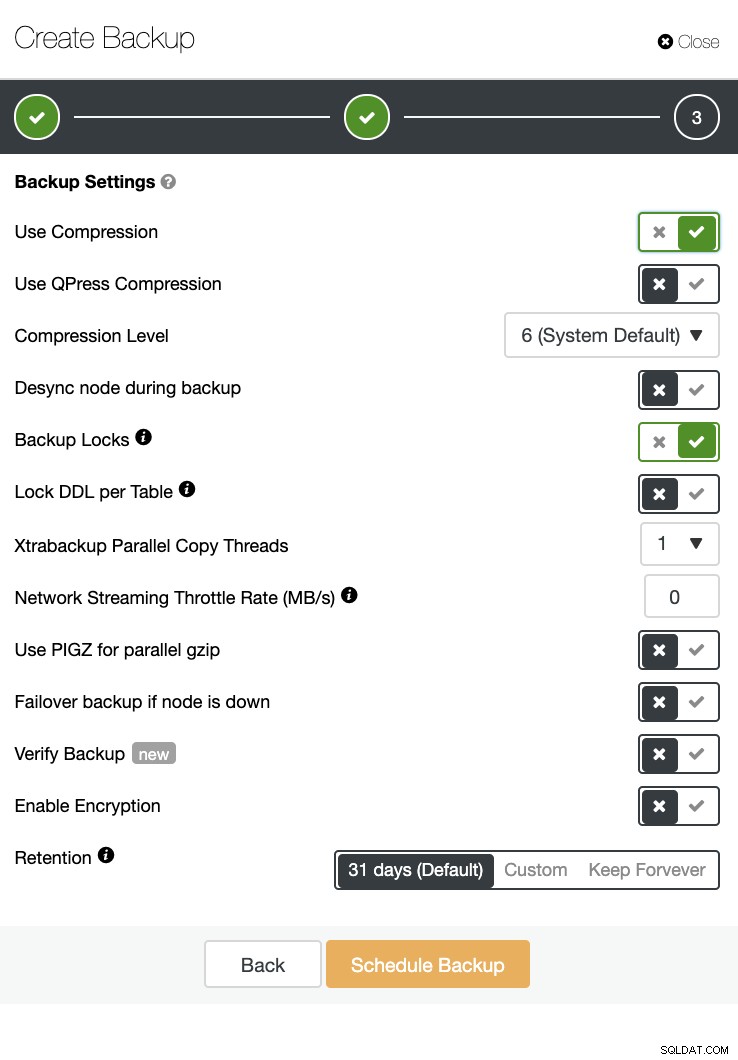
Conclusão
Gerenciar bancos de dados grandes, como mil ou mais, pode ser feito com eficiência, mas deve ser determinado e preparado com antecedência. Usar as ferramentas certas, como automação ou até mesmo assinar serviços gerenciados, ajuda drasticamente. Embora incorra em custos, o retorno do serviço e o orçamento a ser investido para adquirir engenheiros qualificados podem ser reduzidos desde que as ferramentas certas estejam disponíveis.



