Poucas suposições:-
1. Suponha que haja 300 registros que correspondem com base no local.
2. Suponha que o primeiro conjunto de 100 resultados não tenha pizza de tag. Os restantes 200 documentos (101 a 300) têm etiqueta pizza
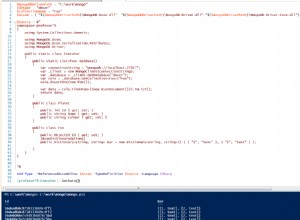
Consulta 1:-
- Existem duas operações de pipeline $geoNear e $match
- A saída da operação de pipeline $geoNear é a entrada da operação $matchpipeline
- $geoNear encontra um máximo de 100 resultados (limite que especificamos) com base na localização classificada da distância mais próxima para a distância. (Observe aqui que os 100 resultados retornados são puramente baseados no local. Portanto, esses 100 resultados não contêm nenhum documento com a tag "pizza")
- Esses 100 resultados são enviados para a próxima operação de pipeline $match de onde a filtragem acontece. Mas como o primeiro conjunto de 100 resultados não tinha a tag pizza, a saída está vazia
Consulta 2:-
- Há apenas 1 operação de pipeline $geoNear
- Há um campo de consulta incluído na operação de pipeline $geoNear$geoNear encontra no máximo 100 resultados (limite que especificamos) com base no local classificado por distância mais próxima e distante e na querytag=pizza
- Agora, os resultados de 101 a 200 são retornados como saída, pois a consulta é incluída na operação de pipeline $geoNear. Então, em uma frase simples, dizemos, encontre todos os documentos com localização [x,y] withtag=pizza.
P.S :- O estágio de pipeline $ group é adicionado apenas para obter a contagem e, portanto, não foi escrito sobre isso na explicação