Introdução:este exemplo demonstra um método mais antigo de usar o IRI RowGen para gerar e preencher protótipos de coleção grandes ou complexos para teste ou capacidade do sistema usando arquivos simples. Como você lerá, RowGen criaria os dados de teste necessários e criaria um arquivo CSV que seria carregado no MongoDB usando o Mongo Import Utility.
Atualização de 2019:o IRI agora também oferece Suporte a JSON e driver direto para mover dados entre coleções MongoDB e produtos de software IRI compatíveis com SortCL, como RowGen ou FieldShield. Isso significa que você pode usar RowGen para gerar arquivos JSON de teste para importação no MongoDB (não muito diferente do método mostrado abaixo neste artigo) ou usar FieldShield para mascarar dados em tabelas Mongo em destinos de teste.
Observe que FieldShield e RowGen estão incluídos na plataforma de gerenciamento de dados IRI Voracity, que oferece quatro maneiras de criar dados de teste.
Embora o MongoDB seja um bom banco de dados NoSQL multiplataforma e orientado a documentos, ele não tem uma maneira conveniente de gerar e preencher protótipos de coleção grandes ou complexos que possam ser usados para testar consultas ou planejar a capacidade. Este artigo explica como criar dados de teste que o MongoDB pode usar via IRI RowGen, especificando os parâmetros para um arquivo CSV sintético, mas realista, que o MongoDB pode importar para testes funcionais e de desempenho.
Você deve primeiro considerar a estrutura e o conteúdo dos dados de teste para suas necessidades de coleção (tabela MongoDB). Consulte este artigo para considerações típicas de planejamento.
No exemplo, sabemos que nossa coleção será composta por clientes que têm Nomes de usuário , Nomes e sobrenomes , Endereços de e-mail e Números de cartão de crédito .
Para criar nossos dados de teste, primeiro devemos gerar alguns arquivos de conjunto. Um arquivo de conjunto é uma lista de um ou mais valores delimitados por tabulação que podem já existir ou precisam ser gerados manualmente ou automaticamente a partir de colunas do banco de dados por meio do assistente 'Gerar novo arquivo de conjunto' no IRI RowGen.
Gerando nomes
1) Crie um script de trabalho de valor de dados composto (nome e sobrenome combinados) chamado “CreateNamesSet.rcl” que RowGen pode executar para produzir um arquivo de conjunto; chame a saída "User.set" porque esses nomes também serão usados como base para nossos nomes de usuário.
2) Crie três campos a serem gerados em Names.set:sobrenome, separador de tabulação e nome. Nomeie o primeiro campo como "LastName" e escolha o método que selecionará valores de um arquivo de conjunto fornecido pelo IRI chamado "names_last.set". Adicione o valor literal "\t" para adicionar um separador de tabulação e repita o processo usado para os valores de sobrenome e nome usando names_first.set.
3) Execute CreateNamesSet.rcl com RowGen, na linha de comando ou na GUI do IRI Workbench, para produzir o arquivo User.set delimitado por tabulação de nome e sobrenome, que será usado em tanto na geração de nomes de usuário quanto na compilação final do arquivo de teste que preenche nossa coleção de protótipos.

Gerando nomes de usuário
Para nomes de usuário, criaremos um arquivo de conjunto que utiliza o arquivo Users.set gerado acima. Os nomes de usuário para este exemplo combinarão sobrenome, primeira inicial e um número gerado aleatoriamente entre 100 e 999.
1) Crie um novo script de trabalho RowGen com o Compound Data Wizard, chame-o de “CreateUsernamesSet.rcl” e nomeie o arquivo do conjunto de saída como “Usernames.set”.
2) Crie valores de nome de usuário compostos com três componentes chamados Part1, Part2 e Part3.
3) Para a Parte 1, escolha o método que selecionará valores (navegar até) o arquivo User.set gerado anteriormente e especifique 'ALL' para o tipo de seleção para manter a associação entre os usuários, nomes de usuário e endereços de e-mail. Defina o tamanho para 5.
4) Para Part2, repita o processo usado para Part1, exceto para Tipo de seleção, selecione 'Row' e defina Column Index como 2. Defina o tamanho como 1. Isso garante que todos os sobrenomes serão usados na geração e que a primeira letra do primeiro nome na mesma linha seja anexada ao nome do usuário.
5) Para a Parte 3, especifique a geração de um valor numérico entre 100 e 999 para sufixar um número inteiro aleatório com cada nome de usuário.
Na execução de CreateUsernamesSet.rcl, vemos que cada nome de usuário contém as cinco primeiras letras do sobrenome, depois a inicial e um número aleatório de três dígitos:
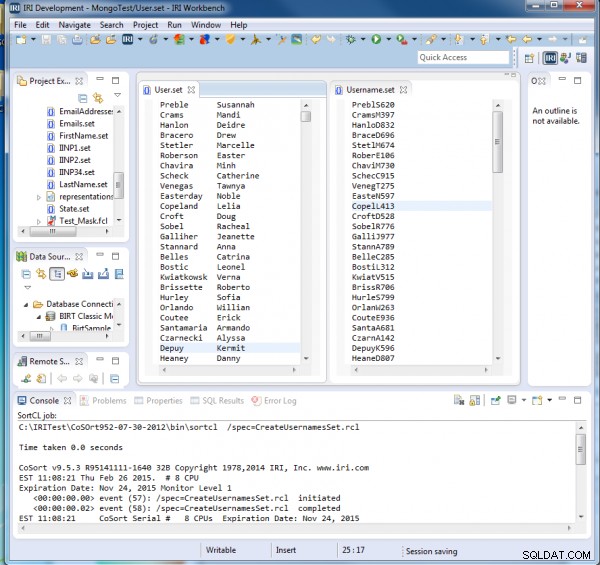
Gerando e-mails
A seguir, criaremos um arquivo de conjunto de e-mail que anexa os valores de nome de usuário a nomes de domínio selecionados aleatoriamente. Como alguns serviços de e-mail são mais populares do que outros, também criaremos um sistema de ponderação para refletir uma frequência maior de domínios do Yahoo e do Gmail.
1) Execute o assistente de trabalho 'Novos dados de teste personalizados' do RowGen para criar um trabalho chamado “CreateEmailsSet” que produz um arquivo de conjunto chamado “Emails.set”.
2) Produza a parte do nome de usuário do e-mail. Na caixa de diálogo Definição de dados de teste, clique em Novo campo e renomeie o primeiro campo Nomes de usuário. Clique duas vezes nele para iniciar a caixa de diálogo Campo de geração e “Define …” seu arquivo Set como Usernames.set. Defina o tamanho para 9 e clique em OK.
3) Produza a parte do domínio do e-mail (que inclui o símbolo @). Na caixa de diálogo Campos de layout, clique em Novo campo e renomeie-o para “endereço” e clique duas vezes nele. Na caixa de diálogo Campo de Geração, especifique um ” ,” com uma posição de 10 e um tamanho de 20. Na seção Geração de Dados / Distribuição de Dados abaixo, clique em “Definir …” para nomear uma nova distribuição de dados de itens “E-mails ponderados”.
4) No Assistente de nova distribuição, escolha "Distribuição ponderada de itens" e insira esses itens nas caixas de texto de proporção e literal, respectivamente. Em seguida, adicione cada um à lista.
(32 | @gmail.com), (32 | @yahoo.com), (2 | @ibm.com), (4 | @msn.com), (2 | @ymail.com), (2 | @inmail.com), (2 | @cnet.net), (2 | @chase.org), (1 | @iri.com), (1 | @gdic.com), (1 | @aci.com), (2 | @oracle.net), (1 | @gmx.org), (4 | @aol.com), (2 | @inbox.com), (2 | @hushmail.com), (2 | @outlook.com), (2 | @zoho.com), (2 | @yandex.net), (2 | @mail.com)
Depois de inserir esses valores, clique em Avançar no assistente original para ir para a caixa de diálogo Destinos de dados. Use “Add Data Target …” para especificar o arquivo de saída “Email.set”. Isso também será usado no momento da compilação da coleção.

Os e-mails para os quais definimos os pesos mais altos (gmail e yahoo) aparecem com mais frequência, enquanto outros aparecem periodicamente.
Geração de números de cartão de crédito
Por fim, criaremos números de cartão computacionalmente válidos no formato XXXX-XXXX-XXXX-XXXX. Os primeiros quatro dígitos refletem os números de identificação de emissão (IIN) reais de várias empresas de cartão de crédito, e o último dígito verifica a autenticidade dos cartões.
Para fazer isso, crie e execute um novo trabalho (vazio). Chame-o de “CreateCCNSet.rcl” (ou .scl) e preencha-o com o script abaixo para criar “CCN.set”. O valor /INCOLLECT em scripts RowGen determina o número de linhas geradas.

A função de geração de CCN criada especificamente para RowGen, ccn_gen(“ANY, “-“) é chamada para preencher este campo. Observe que existem funções semelhantes para os números de previdência social dos EUA e da Coreia e os IDs nacionais da Itália e da Holanda.
Criação do arquivo de teste final
Com todos os arquivos criados, é hora de usá-los no arquivo CSV de teste que criaremos e exportaremos para uma coleção do MongoDB.
1) Execute o assistente de trabalho 'Novos dados de teste personalizados' do RowGen para criar um trabalho chamado "CreateMongoUserData.rcl" que gerará o arquivo Customers.csv, o arquivo que será exportado para o MongoDB.
2) Clique em "Campos de layout ..." para entrar na caixa de diálogo Campos de layout. Clique em Novo campo e renomeie o primeiro campo para Nomes de usuário. Clique duas vezes nele para iniciar a caixa de diálogo Campo de geração e “Define …” seu arquivo Set como Usernames.set; em seguida, selecione ALL para seu tipo de seleção.
3) Clique em Novo campo e renomeie o segundo campo para Sobrenomes. Clique duas vezes nele para iniciar a caixa de diálogo Campo de geração e “Define …” seu arquivo Set como Users.set; em seguida, selecione ALL para seu tipo de seleção.
4) Clique em Novo campo e renomeie o terceiro campo para Nomes. Clique duas vezes nele para iniciar a caixa de diálogo Campo de geração e “Define …” seu arquivo Set como Users.set; em seguida, selecione ROWS para o tipo de seleção e defina o índice da coluna como 2.
5) Clique em Novo campo e renomeie o quarto campo para E-mail. Clique duas vezes nele para iniciar a caixa de diálogo Campo de geração e “Define …” seu arquivo Set como Emails.set; em seguida, selecione ALL para seu tipo de seleção.
6) Clique em Novo campo e renomeie o quinto campo para CreditCardNumbers. Clique duas vezes nele para iniciar a caixa de diálogo Campo de geração e “Define …” seu arquivo Set como CCN.set; em seguida, selecione ALL para seu tipo de seleção.
7) Depois de inserir esses valores, clique em Avançar no assistente original para acessar a caixa de diálogo Destinos de dados. Use “Add Data Target …” para especificar o arquivo de saída Customers.csv; em seguida, execute o script no Workbench ou na linha de comando para gerar esse arquivo:
rowgen /spec=CreateMongoUserData.rcl

Observe que o RowGen, além de produzir esse arquivo CSV em tempo de execução, também pode ter produzido vários outros arquivos, bancos de dados, relatórios formatados, pipes nomeados, procedimentos e até exibição BIRT em tempo real , com campos dos dados de teste gerados, tudo ao mesmo tempo.
Importando para o MongoDB
Para importar o arquivo CSV para seu banco de dados Mongo, chame o 'utilitário mongoimport' e execute o seguinte comando:
--db <Database Name> --collection <Collection Name> --type csv --fields <fieldname1,fieldname2,...> --file <File path to the CSV file to import>

Aqui estão os registros na coleção de teste (mostrado com MongoVUE), que o MongoDB indexará automaticamente com valores de ID gerados para cada entrada:
O MongoDB atribui um valor de ID exclusivo a cada entrada de coleção.
Você também pode carregar dados de teste diretamente no banco de dados Mongo usando o driver ODBC DataDirect da Progress Software para MongoDB. Antes de executar o trabalho RowGen no Workbench, eu tinha uma coleção vazia chamada CUSTOMERS_CNN no MYDB para receber os dados.
Executei o trabalho primeiro usando stdout, para visualizar meus dados de teste na janela do console:

Depois de executar o script no Workbench, agora posso ver meus dados usando o Data Source Explorer e o driver DataDirect JDBC.

Para obter mais informações sobre as opções de geração disponíveis, consulte os Destinos do arquivo de teste seção em: https://www.iri.com/products/rowgen/technical-details.



