A TI moderna precisa ter um esquema não relacional e dinâmico (o que significa que não há requisitos para consultas de declarações de junção) para fornecer suporte a aplicativos de Big Data/em tempo real. Os bancos de dados NoSQL foram criados com a noção de melhorar o desempenho do processamento de dados e lidar com a capacidade de dimensionar para superar a carga de banco de dados distribuída usando o conceito de vários hosts, conquistando a demanda da nova geração de processamento de dados.
Além de fornecer o suporte essencial para vários modelos de dados e linguagens de script, o MongoDB também permite fácil início do processo para os desenvolvedores.
Banco de dados NoSQL abre as portas para...
- Protocolos baseados em texto usando uma linguagem de script (REST e JSON, BSON)
- Custo mínimo para gerar, armazenar e transportar dados
- Suporte a grandes quantidades de processamento de dados.
- Aumento do desempenho de gravação
- Não é necessário realizar mapeamento relacional de objeto e processo de normalização
- Sem controles rígidos com regras de integridade referencial
- Reduzindo o custo de manutenção com administradores de banco de dados
- Reduzindo o custo de expansão
- Acesso rápido ao valor-chave
- Avançando o suporte para aprendizado de máquina e inteligência
Aceitação de mercado do MongoDB
As necessidades modernas de Big Data Analytics e aplicativos modernos desempenham um papel crucial na necessidade de melhorar o ciclo de vida do processamento de dados, sem expectativas de expansão de hardware e aumento de custos.
Se você está planejando um novo aplicativo e deseja escolher um banco de dados, chegar à decisão certa com muitas opções de banco de dados no mercado pode ser um processo complicado.
A classificação de popularidade do mecanismo de banco de dados mostra que o MongoDB está em 1º lugar em comparação com o Oracle NoSQL (que ficou em 74º). A tendência, no entanto, é indicar que algo está mudando. A necessidade de muitas expansões econômicas anda de mãos dadas com uma modelagem de dados muito mais simples, e a administração está transformando a forma como os desenvolvedores gostariam de considerar o melhor para seus sistemas.
De acordo com as informações de participação de mercado da Datanyze até o momento, existem cerca de 289 sites que estão rodando no Oracle Nosql com uma participação de mercado de 11%, enquanto o MongoDB tem um site completo de 12.185 sites com uma participação de mercado de 4,66 %. Esses números impressionantes indicam que há um futuro brilhante para o MongoDB.
Modelagem de dados NoSQL
A modelagem de dados requer compreensão de...
- Os tipos de seus dados atuais.
- Quais são os tipos de dados que você espera no futuro?
- Como seu aplicativo está obtendo acesso aos dados necessários do sistema?
- Como seu aplicativo buscará os dados necessários para processamento?
O interessante para quem sempre seguiu o jeito Oracle de criar esquemas, depois armazenar os dados, o MongoDB permite criar a coleção junto com o documento. Isso significa que a criação de coleções não é obrigatória antes da criação do documento, tornando o MongoDB muito apreciado por sua flexibilidade.
No Oracle NoSQL, no entanto, a definição da tabela precisa ser criada primeiro, após o que você pode continuar criando as linhas.
A próxima coisa legal é que o MongoDB não implica regras estritas na implementação de esquemas e relações, o que lhe dá liberdade para melhoria contínua do sistema sem temer muito a necessidade de garantir um design esquemático rígido.
Vejamos algumas das comparações entre MongoDB e Oracle NoSQL.
Comparando conceitos NoSQL no MongoDB e Oracle
Terminologias NoSQL
| MongoDB | Oracle NoSQL | Fatos |
| Coleção | Tabela/Visualização | Coleção/tabela atuam como contêiner de armazenamento; são semelhantes, mas não idênticos. |
| Documento | Linha | Para MongoDB, dados armazenados em uma coleção, na forma de documentos e campos. Para Oracle NoSQL, uma tabela é uma coleção de linhas, onde cada linha contém um registro de dados. Cada linha da tabela consiste em campos de chave e de dados, que são definidos quando uma tabela é criada. |
| Campo | Coluna | |
| Índice | Índice | Ambas as bases de dados utilizam um índice para melhorar a velocidade de busca realizada na base de dados. |
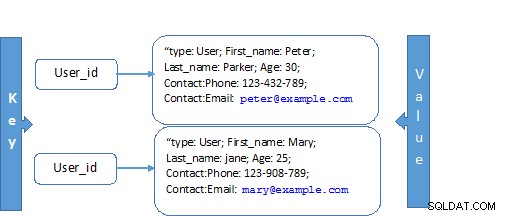
Armazenamento de documentos e armazenamento de valores-chave
O Oracle NoSQL fornece um sistema de armazenamento que armazena valores indexados por uma chave; esse conceito é visto como o modelo menos complexo, pois os conjuntos de dados consistem em um valor-chave indexado. Os registros organizados usando chaves maiores e chaves menores.
A chave principal pode ser vista como o ponteiro do objeto e a chave secundária como os campos no registro. A busca eficiente dos dados é possível com o uso da chave como mecanismo para acessar os dados como uma chave primária.
MongoDB estende pares chave-valor. Cada documento tem uma chave única, que serve ao propósito de recuperar o documento. Os documentos são conhecidos como esquema dinâmico, pois as coleções em um documento não precisam ter o mesmo conjunto de campos. Uma coleção pode ter um campo comum com diferentes tipos de dados. Esses atributos levam o modelo de dados do documento a mapear diretamente para dar suporte às modernas linguagens orientadas a objetos.
| MongoDB | Oracle NoSQL |
| Armazenamento de documentos Exemplo: | Armazenamento de valores-chave Exemplo: |

BSON e JSON
Oracle NoSQL usa JSON como formato de dados padrão para transmissão (dados + pares atributo-valor). Por outro lado, o MongoDB usa BSON.
| MongoDB | Oracle NoSQL |
| BSON | JSON |
| JSON binário - formato de dados binários - induz processamento mais rápido | Notação de Objeto Javascript - formato padrão. Processamento muito mais lento comparado ao BSON. |
| Características :
| Características:
|
BSON não está em um texto legível por humanos, ao contrário do JSON. BSON significa serialização codificada em binário de dados semelhantes a JSON, usado principalmente para armazenamento de dados e um formato de transferência com o MongoDB. O formato de dados BSON consiste em uma lista de elementos ordenados contendo um nome de campo (string), tipo e valor. Quanto aos tipos de dados suportados pelo BSON, todos os tipos de dados comumente encontrados em JSON e incluem dois tipos de dados adicionais (dados binários e data). Dados binários ou conhecidos como BinData com menos de 16 MB podem ser armazenados diretamente em documentos do MongoDB. Diz-se que o BSON está consumindo mais espaço do que os documentos de dados JSON.
Há duas razões pelas quais o MongoDB consome mais espaço em comparação com o Oracle NoSQL:
- O MongoDB atingiu o objetivo de poder percorrer rapidamente, permitindo que a opção de atravessar rápido requer que o documento BSON carregue metadados adicionais (comprimento de string e subobjetos).
- O design BSON pode codificar e decodificar rapidamente. Por exemplo, os inteiros são armazenados como inteiros de 32 (ou 64) bits, para eliminar a análise de e para o texto. Esse processo usa mais espaço que o JSON para números inteiros pequenos, mas é muito mais rápido de analisar.
Definição do modelo de dados
Declaração de coleção do MongoDB
Criar uma coleção
db.createCollection("users")Criando uma coleção com um _id automático
db.users.insert
( {
User_id: "U1",
First_name: "Mary"
Last_name : "Winslet",
Age : 15
Contact : {
Phone: "123-456-789"
Email: "example@sqldat.com"
}
access : {
Level:5,
Group:"dev"
}
})MongoDB permite que as informações relacionadas no mesmo registro de banco de dados sejam incorporadas. Projeto de modelo de dados
Instrução de tabela Oracle NoSQL
Usando SQL CLI para configurar o namespace:
Create namespace newns1; Usando namespace para associar tabelas e tabela filha
news1:users
News1:users.accessCrie uma tabela com uma IDENTIDADE usando:
Create table newns1.user (
idValue INTEGER GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 MAXVALUE 10000),
User_id String,
First_name String,
Last_name String,
Contact Record (Phone string,
Email string),
Primary key (idValue));Criar tabela usando SQL JSON:
Create table newns1.user (
idValue INTEGER GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 MAXVALUE 10000),
User_profile JSON,
Primary Key (shard(idValue),User_id));
Linhas para tabela de usuários:digite JSON
{
"id":U1,
"User_profile" : {
"First_name":"Mary",
"Lastname":"Winslet",
"Age":15,
"Contact":{"Phone":"123-456-789",
"Email":"example@sqldat.com"
}
}Com base nas definições de dados acima, o MongoDB permite diferentes métodos para criação de esquema. A coleta pode ser definida explicitamente ou durante a primeira inserção dos dados no documento. Ao criar uma coleção, você pode definir um objectid. Objectid é a chave primária para documentos do MongoDB. Objectid é um tipo BSON binário de 12 bytes que contém 12 bytes gerados por drivers MongoDB e pelo servidor usando um algoritmo padrão. O objectid do MongoDB é útil e serve para classificar o documento criado em uma coleção específica.
O Oracle NoSQL tem várias maneiras de começar a definir tabelas. Se você estiver usando o Oracle SQL CLI por padrão, a criação de novas tabelas será colocada em sysdefault até que você decida criar um novo namespace para associar a ele um conjunto de novas tabelas. O exemplo acima demonstra o novo namespace “ns1” criado e a tabela de usuário está associada ao novo namespace.
Além de identificar a chave primária, o Oracle NoSQL também usa a coluna IDENTITY para incrementar automaticamente um valor cada vez que você adiciona uma linha. O valor IDENTITY é gerado automaticamente e deve ser um tipo de dados Integer, long ou number. No Oracle NoSQL, IDENTITY associa-se ao Sequence Generator semelhante ao conceito de objectid com MongoDB. Como o Oracle NoSQL permite que a chave IDENTITY seja usada como chave primária. Se você está considerando a chave de IDENTIDADE como a chave primária, é aqui que é necessária uma consideração cuidadosa, pois pode ter um impacto sobre a inserção de dados e o processo de atualização.
A definição de nível de coleção/tabela do MongoDB e Oracle NoSQL mostra como as informações de 'contato' são incorporadas na mesma estrutura única sem exigir definição de esquema adicional. A vantagem de incorporar um conjunto de dados é que nenhuma consulta adicional seria necessária para recuperar o conjunto de dados incorporado.
Se você deseja manter seu sistema de forma simples, o MongoDB oferece a melhor opção para reter os documentos de dados com menos complicações. Ao mesmo tempo, o MongoDB fornece os recursos para entregar o modelo de dados complexo existente do esquema relacional usando a ferramenta de validação de esquema.
Oracle NoSQL fornece recursos para usar SQL, como linguagem de consulta com DDL e DML, o que exige muito menos esforço para usuários que têm alguma experiência com o uso de sistemas de Banco de Dados Relacionados.
MongoDB shell usa Javascript, e se você não se sente confortável com a linguagem ou com o uso do mongo shell, então o melhor ajuste para o processo é optar por usar uma ferramenta IDE. As 5 principais ferramentas de IDE do MongoDB em 2020, como studio 3T, Robo 3T, NoSQLBooster, MongoDB Compass e Nucleon Database Master serão úteis para ajudá-lo a criar e gerenciar consultas complexas com o uso de recursos de agregação.
Desempenho e Disponibilidade
Como o modelo de estrutura de dados do MongoDB usa documentos e coleções, usar o formato de dados BSON para processar uma grande quantidade de dados se torna muito mais rápido em comparação com o Oracle NoSQL. Embora alguns considerem que consultar dados com SQL é um caminho mais confortável para muitos usuários, a capacidade se torna um problema. Quando temos uma grande quantidade de dados para suportar, a necessidade de aumento de throughput e seguido pelo uso de SQL para projetar consultas complexas, esses processos nos pedem para rever a capacidade do servidor e o aumento de custos ao longo do tempo.
Tanto o MongoDB quanto o Oracle NoSQL fornecem recursos de fragmentação e replicação. A fragmentação é um processo que permite que o conjunto de dados e a carga geral de processamento sejam distribuídos em várias partições físicas para aumentar a velocidade de processamento (leitura/gravação). A implementação do shard com oracle exige que você tenha informações prévias sobre como funcionam as chaves de sharding. A razão por trás do processo de pré-planejamento é devido à necessidade de implementar a chave de fragmentação no nível de iniciação do esquema.
A implementação de shard com o MongoDB oferece espaço para você trabalhar primeiro em seu conjunto de dados para identificar a chave de fragmentação correta com base nos padrões de consulta antes da implementação. Como o processo de fragmentação inclui replicação de dados, o MongoDB também tem reputação de replicação rápida de dados. A replicação cuida da tolerância a falhas de ter todos os dados em um único servidor.
Conclusão
O que torna o MongoDB preferido em relação ao Oracle NoSQL é que ele está em formato binário e suas características inatas de leveza, travessia e eficiência. Isso permite que você dê suporte ao aplicativo moderno avançado na área de aprendizado de máquina e inteligência artificial.
As características do MongoDB permitem que os desenvolvedores trabalhem com muito mais confiança para construir aplicativos modernos mais rapidamente. O modelo de dados do MongoDB permite o processamento de grandes quantidades de dados não estruturados com uma velocidade aprimorada que é bem pensada em comparação com o Oracle NoSQL. O Oracle NoSQL ganha quando se trata de ferramentas que oferece e possíveis opções para criar modelos de dados. No entanto, é essencial garantir que desenvolvedores e designers possam aprender e se adaptar rapidamente à tecnologia, o que não é o caso do Oracle NoSQL.



