MongoDB é um banco de dados NoSQL que suporta uma ampla variedade de fontes de conjuntos de dados de entrada. Ele é capaz de armazenar dados em documentos flexíveis do tipo JSON, o que significa que campos ou metadados podem variar de documento para documento e a estrutura de dados pode ser alterada ao longo do tempo. O modelo de documento facilita o trabalho com os dados mapeando os objetos no código do aplicativo. O MongoDB também é conhecido como um banco de dados distribuído em seu núcleo, portanto, alta disponibilidade, dimensionamento horizontal e distribuição geográfica são integrados e fáceis de usar. Ele vem com a capacidade de modificar perfeitamente os parâmetros para o treinamento do modelo. Os Cientistas de Dados podem facilmente mesclar a estruturação de dados com essa geração de modelo.
O que é aprendizado de máquina?
Aprendizagem de máquina é a ciência de fazer os computadores aprenderem e agirem como os humanos e melhorar seu aprendizado ao longo do tempo de forma autônoma. O processo de aprendizado começa com observações ou dados, como exemplos, experiência direta ou instrução, para procurar padrões nos dados e tomar melhores decisões no futuro com base nos exemplos que fornecemos. O objetivo principal é permitir que os computadores aprendam automaticamente sem intervenção ou assistência humana e ajustem as ações de acordo.
Um modelo avançado de programação e consulta
O MongoDB oferece drivers nativos e conectores certificados para desenvolvedores e cientistas de dados que criam modelos de aprendizado de máquina com dados do MongoDB. PyMongo é uma ótima biblioteca para incorporar a sintaxe do MongoDB no código Python. Podemos importar todas as funções e métodos do MongoDB para usá-los em nosso código de aprendizado de máquina. É uma ótima técnica para obter funcionalidade em vários idiomas em um único código. A vantagem adicional é que você pode usar os recursos essenciais dessas linguagens de programação para criar um aplicativo eficiente.
A linguagem de consulta do MongoDB com índices secundários avançados permite que os desenvolvedores criem aplicativos que podem consultar e analisar os dados em várias dimensões. Os dados podem ser acessados por chaves únicas, intervalos, pesquisa de texto, gráficos e consultas geoespaciais por meio de agregações complexas e trabalhos MapReduce, retornando respostas em milissegundos.
Para paralelizar o processamento de dados em um cluster de banco de dados distribuído, o MongoDB fornece o pipeline de agregação e o MapReduce. O pipeline de agregação do MongoDB é modelado de acordo com o conceito de pipelines de processamento de dados. Os documentos entram em um pipeline de vários estágios que transforma os documentos em um resultado agregado usando operações nativas executadas no MongoDB. Os estágios de pipeline mais básicos fornecem filtros que funcionam como consultas e transformações de documentos que modificam a forma do documento de saída. Outras operações de pipeline fornecem ferramentas para agrupar e classificar documentos por campos específicos, bem como ferramentas para agregar o conteúdo de matrizes, incluindo matrizes de documentos. Além disso, os estágios do pipseline podem usar operadores para tarefas como calcular a média ou os desvios padrão em coleções de documentos e manipular strings. O MongoDB também fornece operações MapReduce nativas dentro do banco de dados, usando funções JavaScript personalizadas para executar o mapa e reduzir os estágios.
Além de sua estrutura de consulta nativa, o MongoDB também oferece um conector de alto desempenho para o Apache Spark. O conector expõe todas as bibliotecas do Spark, incluindo Python, R, Scala e Java. Os dados do MongoDB são materializados como DataFrames e Datasets para análise com aprendizado de máquina, gráfico, streaming e APIs SQL.
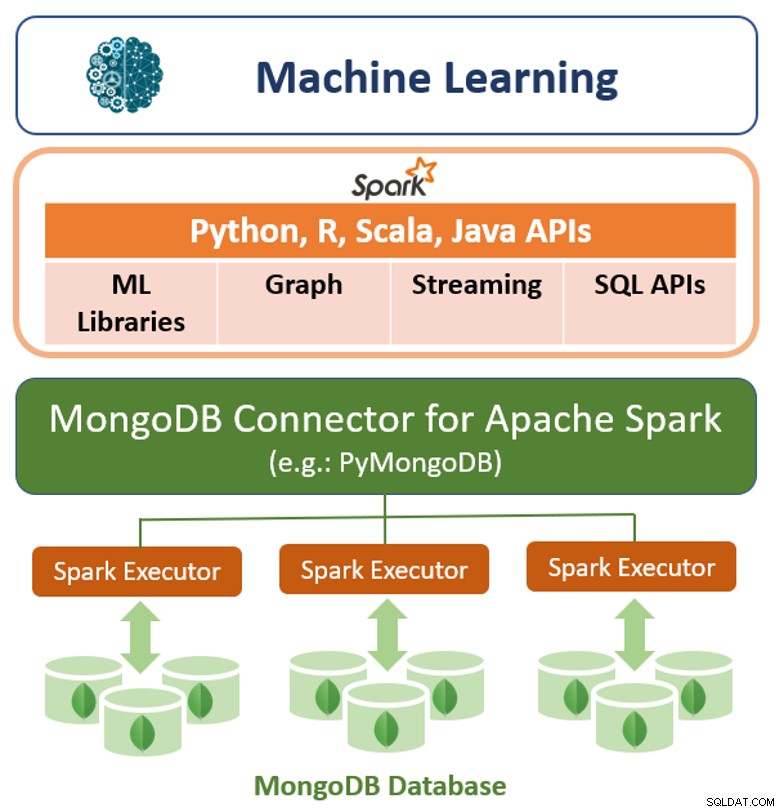
O MongoDB Connector para Apache Spark pode aproveitar o pipeline de agregação e secundário do MongoDB índices para extrair, filtrar e processar apenas o intervalo de dados de que precisa - por exemplo, analisando todos os clientes localizados em uma geografia específica. Isso é muito diferente dos armazenamentos de dados NoSQL simples que não suportam índices secundários ou agregações no banco de dados. Nesses casos, o Spark precisaria extrair todos os dados com base em uma chave primária simples, mesmo que apenas um subconjunto desses dados seja necessário para o processo do Spark. Isso significa mais sobrecarga de processamento, mais hardware e mais tempo para obter insights para cientistas e engenheiros de dados. Para maximizar o desempenho em grandes conjuntos de dados distribuídos, o MongoDB Connector para Apache Spark pode colocar conjuntos de dados distribuídos resilientes (RDDs) com o nó MongoDB de origem, minimizando assim a movimentação de dados no cluster e reduzindo a latência.
Desempenho, escalabilidade e redundância
O tempo de treinamento do modelo pode ser reduzido construindo a plataforma de aprendizado de máquina em cima de uma camada de banco de dados escalável e de alto desempenho. O MongoDB oferece uma série de inovações para maximizar a taxa de transferência e minimizar a latência das cargas de trabalho de aprendizado de máquina:
- O WiredTiger é conhecido como o mecanismo de armazenamento padrão do MongoDB, desenvolvido pelos arquitetos do Berkeley DB, o software de gerenciamento de dados incorporado mais implantado no mundo. O WiredTiger é dimensionado em arquiteturas modernas de vários núcleos. Usando uma variedade de técnicas de programação, como ponteiros de risco, algoritmos sem bloqueio, travamento rápido e passagem de mensagens, o WiredTiger maximiza o trabalho computacional por núcleo de CPU e ciclo de clock. Para minimizar a sobrecarga no disco e E/S, o WiredTiger usa formatos de arquivo compactos e compactação de armazenamento.
- Para os aplicativos de aprendizado de máquina mais sensíveis à latência, o MongoDB pode ser configurado com o mecanismo de armazenamento In-Memory. Com base no WiredTiger, esse mecanismo de armazenamento oferece aos usuários os benefícios da computação na memória, sem abrir mão da rica flexibilidade de consulta, análise em tempo real e capacidade escalável oferecida pelos bancos de dados convencionais baseados em disco.
- Para paralelizar o treinamento do modelo e dimensionar conjuntos de dados de entrada além de um único nó, o MongoDB usa uma técnica chamada sharding, que distribui processamento e dados entre clusters de hardware comum. A fragmentação do MongoDB é totalmente elástica, reequilibrando automaticamente os dados no cluster à medida que o conjunto de dados de entrada cresce ou à medida que os nós são adicionados e removidos.
- Em um cluster MongoDB, os dados de cada shard são distribuídos automaticamente para várias réplicas hospedadas em nós separados. Os conjuntos de réplicas do MongoDB fornecem redundância para recuperar dados de treinamento em caso de falha, reduzindo a sobrecarga de pontos de verificação.
Consistência ajustável do MongoDB
O MongoDB é fortemente consistente por padrão, permitindo que aplicativos de aprendizado de máquina leiam imediatamente o que foi gravado no banco de dados, evitando assim a complexidade do desenvolvedor imposta por sistemas eventualmente consistentes. A consistência forte fornecerá os resultados mais precisos para algoritmos de aprendizado de máquina; no entanto, em alguns cenários, é aceitável negociar a consistência em relação a metas de desempenho específicas, distribuindo consultas em um cluster de membros do conjunto de réplicas secundárias do MongoDB.
Modelo de dados flexível no MongoDB
O modelo de dados de documentos do MongoDB facilita para desenvolvedores e cientistas de dados armazenar e agregar dados de qualquer forma de estrutura dentro do banco de dados, sem abrir mão de regras de validação sofisticadas para controlar a qualidade dos dados. O esquema pode ser modificado dinamicamente sem um tempo de inatividade do aplicativo ou do banco de dados que resulta de dispendiosas modificações de esquema ou redesenho incorridos por sistemas de banco de dados relacionais.
Salvar modelos em um banco de dados e carregá-los, usando python, também é um método fácil e muito necessário. Escolher o MongoDB também é uma vantagem, pois é um banco de dados de documentos de código aberto e também um banco de dados NoSQL líder. O MongoDB também serve como um conector para a estrutura distribuída do Apache Spark.
Natureza Dinâmica do MongoDB
A natureza dinâmica do MongoDB permite seu uso em tarefas de manipulação de banco de dados no desenvolvimento de aplicativos de Machine Learning. É uma maneira muito eficiente e fácil de realizar uma análise de conjuntos de dados e bancos de dados. A saída da análise pode ser usada no treinamento de modelos de aprendizado de máquina. Foi recomendado que analistas de dados e programadores de Machine Learning ganhem domínio no MongoDB e o apliquem em muitos aplicativos diferentes. A estrutura de agregação do MongoDB é usada para fluxo de trabalho de ciência de dados para realizar análise de dados para vários aplicativos.
Conclusão
O MongoDB oferece vários recursos diferentes, como:modelo de dados flexível, programação rica, modelo de dados, modelo de consulta e sua consistência ajustável que tornam o treinamento e o uso de algoritmos de aprendizado de máquina muito mais fáceis do que com bancos de dados relacionais tradicionais. A execução do MongoDB como banco de dados de back-end permitirá o armazenamento e o enriquecimento de dados de aprendizado de máquina, permitindo persistência e maior eficiência.



