Às vezes acontece que você tem um arquivo de texto ou CSV muito grande para processar, mas primeiro você quer fazer arquivos menores desse arquivo grande. Porque esse arquivo grande pode levar muito tempo para ser processado ou aberto. Então, estou dando um exemplo abaixo para dividir um arquivo grande de texto/CSV em vários arquivos no PL SQL usando o procedimento armazenado.
Você só precisa passar dois parâmetros para este procedimento PL SQL, o primeiro é o nome do objeto do diretório do banco de dados, onde os arquivos de texto estão residindo e o segundo é o nome do arquivo de origem (o arquivo que você deseja dividir).
Se o objeto de diretório Oracle não existir para o local dos arquivos de texto, você poderá criá-lo conforme mostrado abaixo:
For windows: CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS 'D:\plsql\text_files';
For Linux/Unix (due to difference in path): CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS '/plsql/text_files';
Altere o caminho acima de acordo com a localização dos seus arquivos. Em seguida, crie o procedimento abaixo executando seu script:
CREATE OR REPLACE PROCEDURE split_file (p_db_dir IN VARCHAR2, p_file_name IN VARCHAR2) IS read_file UTL_FILE.file_type; write_file UTL_FILE.file_type; v_string VARCHAR2 (32767); j NUMBER := 1; BEGIN read_file := UTL_FILE.fopen (p_db_dir, p_file_name, 'r'); WHILE j > 0 LOOP write_file := UTL_FILE.fopen (p_db_dir, j || '_' || p_file_name, 'w'); FOR i IN 1 .. 100 LOOP -- example to dividing into 100 rows for each file.. you can increase the number as per your requirement UTL_FILE.get_line (read_file, v_string); UTL_FILE.put_line (write_file, v_string); END LOOP; UTL_FILE.fclose (write_file); j := J + 1; END LOOP; EXCEPTION WHEN OTHERS THEN -- this will handle if reading source file contents finish UTL_FILE.fclose (read_file); UTL_FILE.fclose (write_file); END;
Este procedimento divide 100 linhas para cada arquivo, que você pode modificar conforme sua necessidade. Agora execute este procedimento conforme mostrado abaixo passando o nome do objeto do diretório do banco de dados e o nome do arquivo:
BEGIN
split_file ('CSV_FILE_DIR', 'text_file.csv');
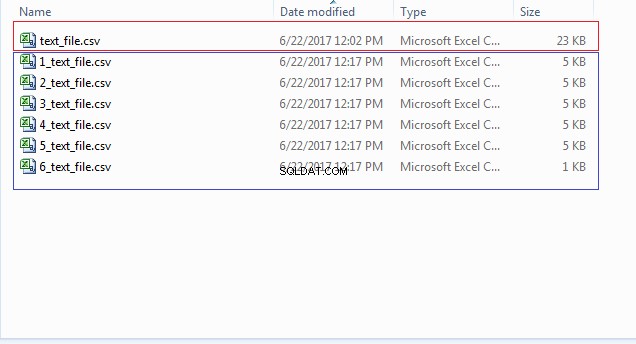
END; Você pode verificar o local do arquivo (CSV_FILE_DIR) para os vários arquivos começando com números como 1_text_file.csv, 2_text_file.csv e assim por diante, conforme mostrado na imagem abaixo: