Os índices do SQL Server são usados para ajudar a recuperar dados mais rapidamente e reduzir gargalos que afetam recursos críticos. Os índices em uma tabela de banco de dados servem como uma técnica de otimização de desempenho. Você pode se perguntar – como os índices aumentam o desempenho da consulta? Existem índices bons e ruins? Suponha que você tenha uma tabela com 50 colunas, é uma boa ideia criar índices em cada uma das colunas? Se criarmos vários índices, isso ajuda as consultas SQL a serem executadas mais rapidamente?
Todas ótimas perguntas, mas antes de nos aprofundarmos, é essencial saber por que os índices podem ser necessários em primeiro lugar.
Imagine que você visite uma biblioteca da cidade que possui uma coleção de milhares de livros. Você está procurando um livro específico, mas como vai encontrá-lo? Se você examinasse cada livro, em cada prateleira, poderia levar dias para encontrá-lo. O mesmo se aplica a um banco de dados quando você procura um registro de milhões de linhas armazenadas em uma tabela.
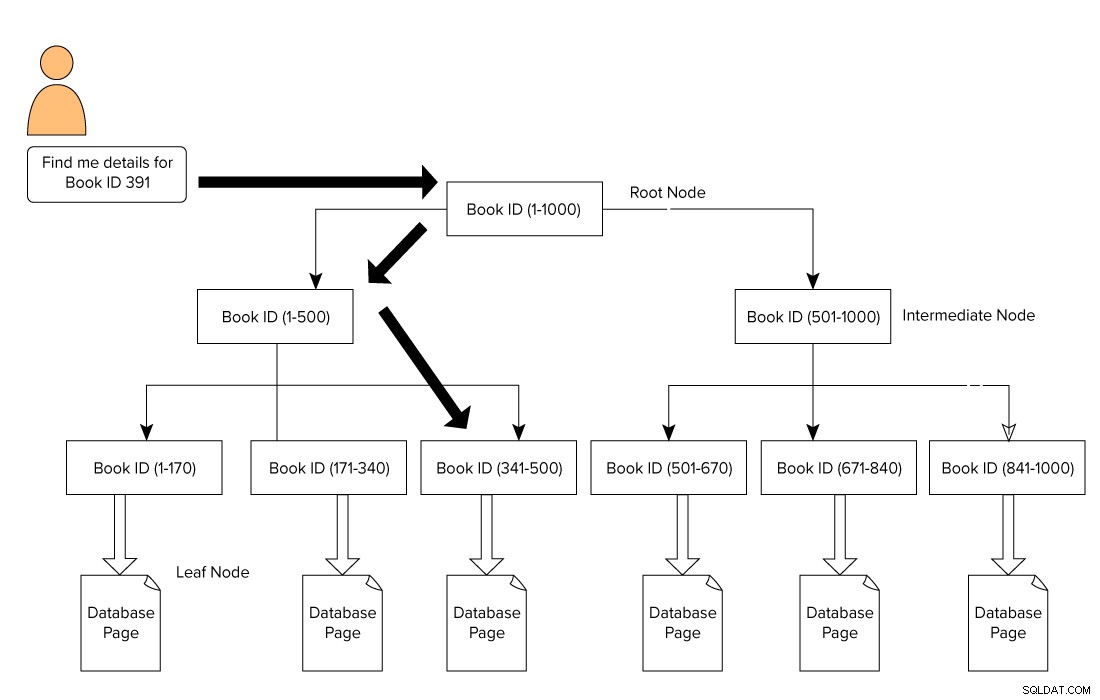
Um índice do SQL Server é moldado em um formato B-Tree que consiste em um nó raiz na parte superior e um nó folha na parte inferior. Para nosso exemplo de livros da biblioteca, um usuário emite uma consulta para procurar um livro com o ID 391. Nesse caso, o mecanismo de consulta começa a percorrer o nó raiz e se move para o nó folha.
Nó raiz –> Nó intermediário –> Nó folha.
O mecanismo de consulta procura a página de referência no nível intermediário. Neste exemplo, o primeiro nó intermediário consiste em IDs de livros de 1-500 e o segundo nó intermediário consiste em 501-1000.
Com base no nó intermediário, o mecanismo de consulta percorre a B-Tree para procurar o nó intermediário correspondente e o nó folha. Esse nó folha pode consistir em dados reais ou apontar para a página de dados real com base no tipo de índice. Na imagem abaixo, vemos como percorrer o índice para procurar dados usando índices do SQL Server. Nesse caso, o SQL Server não precisa percorrer cada página, lê-la e procurar um conteúdo específico de ID de livro.
Impactos dos índices no desempenho do SQL Server
No exemplo de biblioteca anterior, examinamos os possíveis impactos no desempenho do índice. Vejamos o desempenho da consulta com e sem um índice.
Suponha que exigimos dados para o [SalesOrderID] 56958 da tabela [SalesOrderDetail_Demo].
SELECT *
FROM [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
onde SalesOrderID=56958
Esta tabela não tem nenhum índice nela. Uma tabela sem nenhum índice é chamada de tabela de heap no SQL Server.
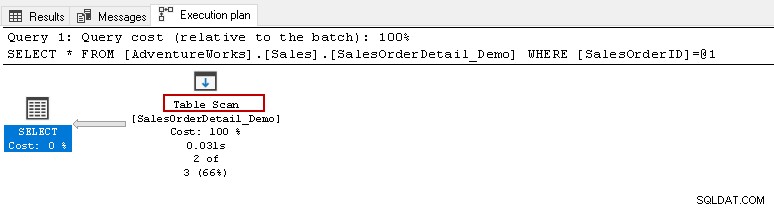
A partir daqui, você deseja executar a instrução select acima e visualizar o plano de execução real. Esta tabela contém 121317 registros. Ele executa uma varredura de tabela, o que significa que lê todas as linhas em uma tabela para encontrar o [SalesOrderID] específico.
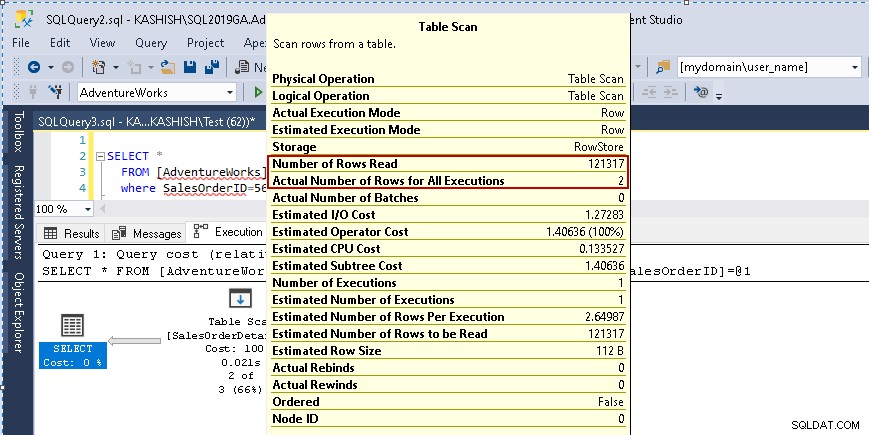
Quando você passa o cursor sobre o ícone Table Scan, ele mostra que o conjunto de resultados real contém 2 linhas, mas para esse propósito, ele lê todas as linhas dessa tabela.
- Número de linhas lidas:121317
- O número real de linhas para a execução:2
Agora, pense em uma tabela com milhões ou bilhões de linhas. Não é uma boa prática percorrer todos os registros da tabela para filtrar algumas linhas. Em um sistema de banco de dados extensivo de processamento de transações online (OLTP), ele não usa os recursos do servidor (CPU, IO, memória) de forma eficaz, portanto, o usuário pode enfrentar problemas de desempenho.
Agora, vamos executar a instrução select acima com a tabela com índices. Esta tabela tem um índice clusterizado de chave primária e dois índices não clusterizados nas colunas [ProductID] e [rowguid]. Falaremos mais adiante sobre os diferentes tipos de índices no SQL Server.
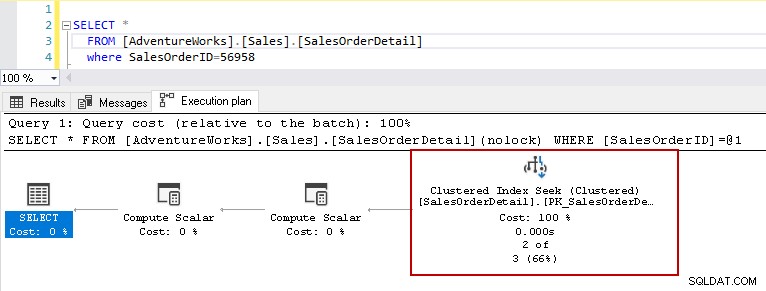
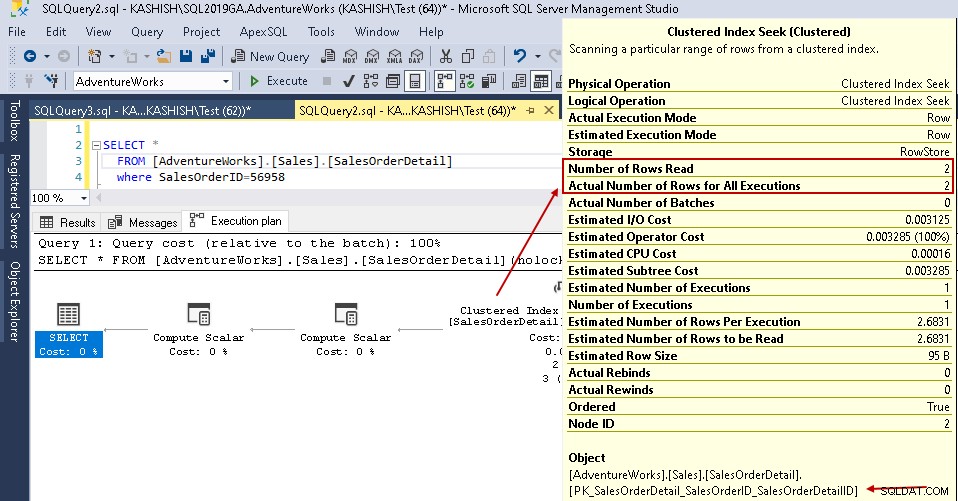
Agora, se você executar novamente a instrução select com o mesmo predicado, o plano de execução mostrará o problema de desempenho. O otimizador de consulta decide usar a busca de índice clusterizado no lugar de uma varredura de índice clusterizado.
Nos detalhes de busca do índice clusterizado, ele mostra que o otimizador de consulta leu com precisão as linhas fornecidas na saída.
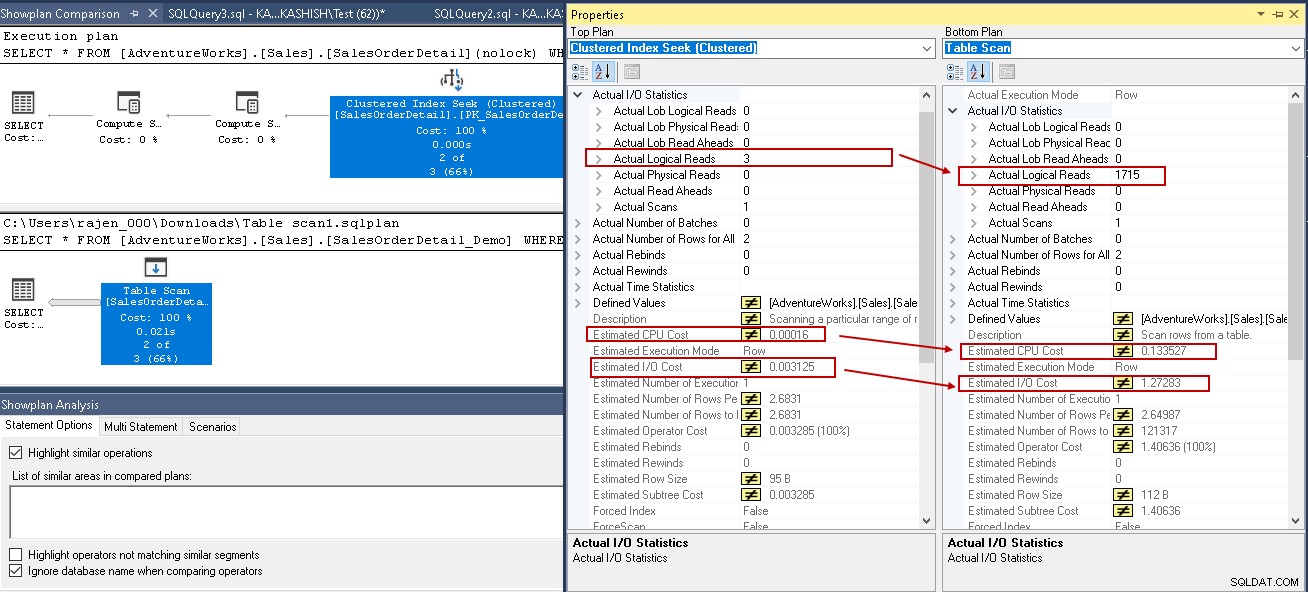
Para fornecer uma análise comparativa, vamos comparar o plano de execução com e sem um índice do SQL Server. Você pode consultar o artigo do SQL Shack como comparar planos de execução de consulta no SQL Server 2016 para obter mais informações.
Para este exemplo, observe os valores destacados na busca de índice clusterizado e na varredura de tabela:
- Leituras lógicas:o mecanismo de banco de dados do SQL Server lê uma página do cache de buffer e causa uma leitura lógica. Abaixo, vemos que as leituras lógicas são reduzidas de 1715 para 3 assim que você cria o índice.
- O custo estimado da CPU também cai de 0,133527 para 0,00016
- O custo estimado de IO cai de 1,27283 para 0,003125
A imagem abaixo mostra uma diferença entre uma varredura de tabela e uma busca de índice.
Índices bons (úteis) e índices ruins no SQL Server
Como o nome sugere, um bom índice melhora o desempenho da consulta e minimiza a utilização de recursos. Um índice pode reduzir o desempenho de consultas no SQL Server? Às vezes criamos o índice em uma coluna específica, mas ele nunca está sendo usado. Suponha que você tenha um índice em uma coluna e execute muitas inserções e atualizações para essa coluna. Para cada atualização, a atualização de índice correspondente também é necessária. Se sua carga de trabalho tiver mais atividade de gravação e você tiver muitos índices em uma coluna, isso diminuirá o desempenho geral de suas consultas. Um índice não utilizado também pode causar desempenho lento para instruções select. O otimizador de consultas usa estatísticas para criar um plano de execução. Ele lê todos os índices e sua amostragem de dados e, com base nisso, constrói um plano otimizado de execução de consultas. Você pode acompanhar o uso do índice usando a exibição de gerenciamento dinâmico sys.dm_db_index_usage_stats e monitorar os recursos, como verificação de usuários, buscas de usuários e pesquisas de usuários.
Tipos e considerações de índice do SQL Server
O SQL Server tem dois índices principais – índices clusterizados e não clusterizados. Um índice clusterizado armazena os dados reais no nó folha do índice. Ele classifica fisicamente os dados nas páginas de dados com base na chave de índice clusterizado. O SQL Server permite um índice clusterizado por tabela. Você pode unir várias colunas para criar uma chave de índice clusterizado. Um índice não clusterizado é um índice lógico e tem a coluna de chave de índice que aponta para a chave de índice clusterizado.
Também podemos ter outros índices no SQL Server, como índice XML, índice de armazenamento de colunas, índice espacial, índice de texto completo, índice de hash, etc.
Você deve considerar os seguintes pontos antes de criar um índice no SQL Server:
- Carga de trabalho
- A coluna na qual o índice é obrigatório
- Tamanho da tabela
- Ordem crescente ou decrescente dos dados da coluna
- Ordem das colunas
- Tipo de índice
- Fator de preenchimento, índice de preenchimento e ordem de classificação TempDB
Benefícios, implicações e recomendações do índice do SQL Server
Índices em um banco de dados podem ser uma faca de dois gumes. Um índice útil do SQL Server aprimora a consulta e o desempenho do sistema sem afetar as outras consultas. Por outro lado, se você criar um índice sem qualquer preparação ou consideração, isso poderá causar degradações de desempenho, recuperação lenta de dados e consumir recursos mais críticos, como CPU, E/S e memória. Os índices também aumentam suas tarefas de manutenção do banco de dados. Tendo esses fatores em mente, é sempre melhor testar um índice apropriado em um ambiente de pré-produção com a carga de trabalho equivalente de produção, analisar o desempenho e decidir se é melhor implementá-lo em um banco de dados de produção. Há muitas outras recomendações a serem consideradas. Confira minhas 11 principais práticas recomendadas de índice para obter mais informações.