PostgreSQL Streaming Replication é uma ótima maneira de dimensionar clusters PostgreSQL e, ao fazer isso, adiciona alta disponibilidade a eles. Como em toda replicação, a ideia é que o slave seja uma cópia do master e que o slave seja constantemente atualizado com as mudanças que aconteceram no master usando algum tipo de mecanismo de replicação.
Pode acontecer que o escravo, por algum motivo, fique fora de sincronia com o mestre. Como posso trazê-lo de volta para a cadeia de replicação? Como posso garantir que o escravo esteja novamente em sincronia com o mestre? Vamos dar uma olhada neste pequeno post do blog.
O que é muito útil, não há como escrever em um escravo se ele estiver no modo de recuperação. Você pode testar assim:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionAinda pode acontecer que o escravo fique fora de sincronia com o mestre. Corrupção de dados - nem hardware ou software está isento de bugs e problemas. Alguns problemas com a unidade de disco podem causar corrupção de dados no escravo. Alguns problemas com o processo de “vácuo” podem resultar na alteração dos dados. Como se recuperar desse estado?
Reconstruindo o escravo usando pg_basebackup
A etapa principal é provisionar o escravo usando os dados do mestre. Dado que usaremos a replicação de streaming, não podemos usar o backup lógico. Felizmente, existe uma ferramenta pronta que pode ser usada para configurar:pg_basebackup. Vamos ver quais seriam as etapas que precisamos seguir para provisionar um servidor escravo. Para deixar claro, estamos usando o PostgreSQL 12 para este post.
O estado inicial é simples. Nosso escravo não está replicando de seu mestre. Os dados que ele contém estão corrompidos e não podem ser usados nem confiáveis. Portanto, o primeiro passo que faremos será parar o PostgreSQL em nosso escravo e remover os dados que ele contém:
example@sqldat.com:~# systemctl stop postgresqlOu mesmo:
example@sqldat.com:~# killall -9 postgresAgora, vamos verificar o conteúdo do arquivo postgresql.auto.conf, podemos usar as credenciais de replicação armazenadas nesse arquivo posteriormente, para pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Estamos interessados no usuário e na senha usados para configurar a replicação.
Finalmente podemos remover os dados:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Uma vez que os dados são removidos, precisamos usar pg_basebackup para obter os dados do mestre:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointOs sinalizadores que usamos têm o seguinte significado:
- -Xs:gostaríamos de transmitir o WAL enquanto o backup é criado. Isso ajuda a evitar problemas com a remoção de arquivos WAL quando você tem um grande conjunto de dados.
- -P: gostaríamos de ver o progresso do backup.
- -R: queremos que o pg_basebackup crie o arquivo standby.signal e prepare o arquivo postgresql.auto.conf com as configurações de conexão.
pg_basebackup aguardará o checkpoint antes de iniciar o backup. Se demorar muito, você pode usar duas opções. Primeiro, é possível definir o modo de checkpoint para rápido em pg_basebackup usando a opção ‘-c fast’. Alternativamente, você pode forçar o checkpoint executando:
postgres=# CHECKPOINT;
CHECKPOINTDe uma forma ou de outra, o pg_basebackup será iniciado. Com o sinalizador -P podemos acompanhar o progresso:
416906/1588478 kB (26%), 0/1 tablespaceceaceQuando o backup estiver pronto, tudo o que precisamos fazer é garantir que o conteúdo do diretório de dados tenha o usuário e grupo corretos atribuídos - executamos pg_basebackup como 'root', portanto, queremos alterá-lo para 'postgres ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/Isso é tudo, podemos iniciar o escravo e ele deve começar a replicar a partir do mestre.
example@sqldat.com:~# systemctl start postgresqlVocê pode verificar novamente o progresso da replicação executando a seguinte consulta no mestre:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Como você pode ver, ambos os escravos estão replicando corretamente.
Reconstruindo o escravo usando o ClusterControl
Se você é um usuário do ClusterControl, pode facilmente conseguir exatamente o mesmo escolhendo uma opção na interface do usuário.
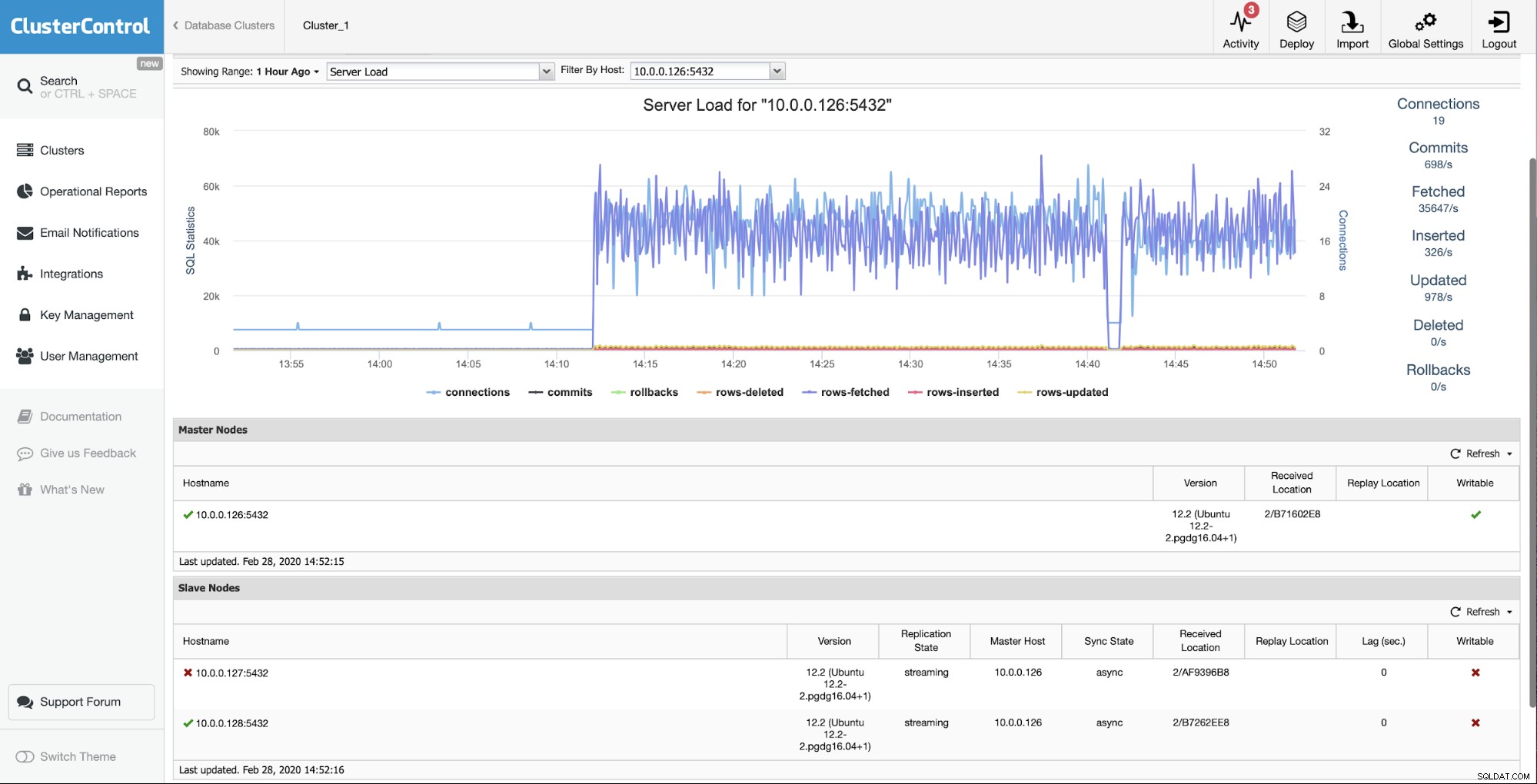
A situação inicial é que um dos escravos (10.0.0.127) é não está funcionando e não está replicando. Consideramos que a reconstrução é a melhor opção para nós.
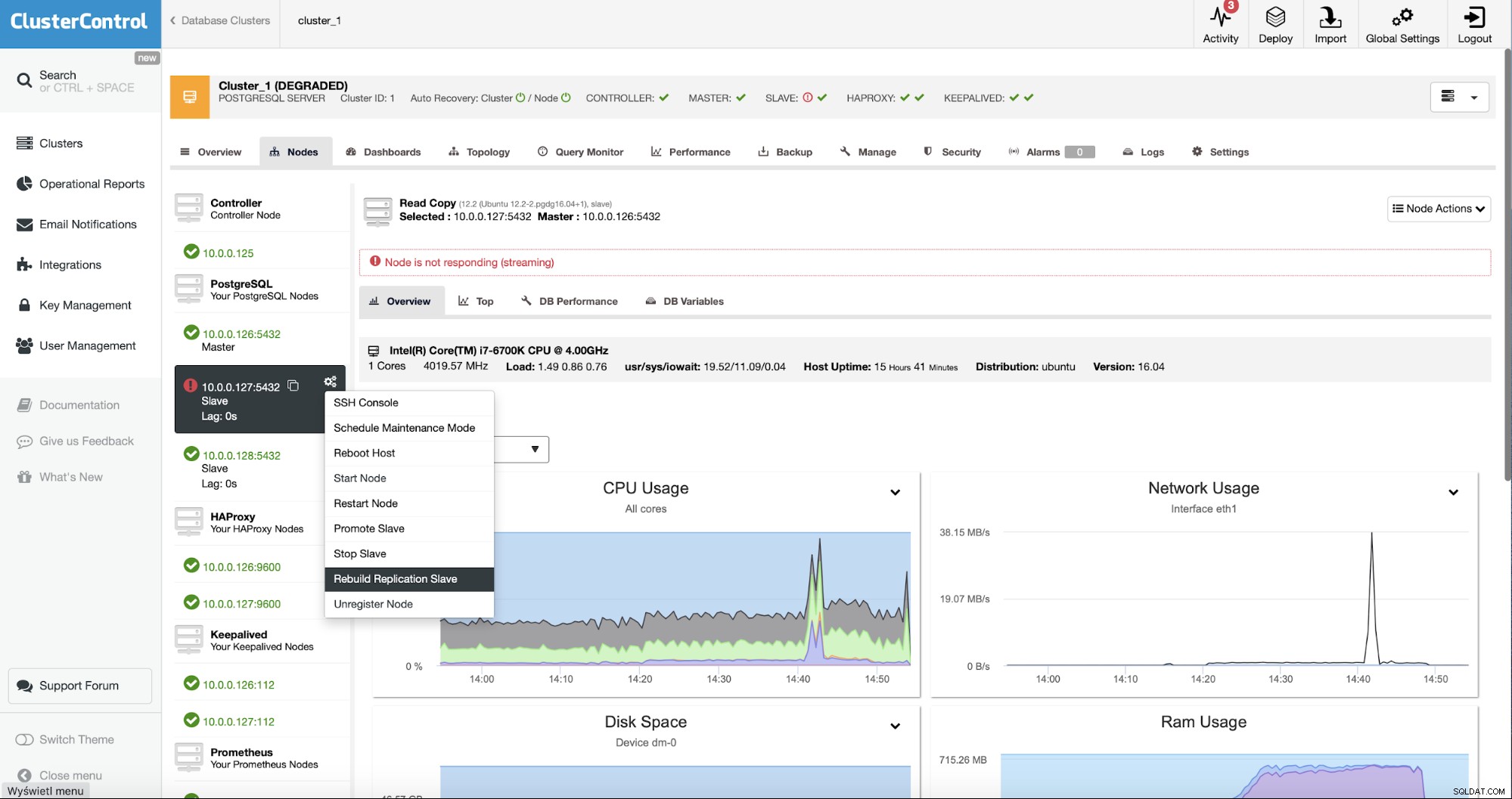
Como usuários do ClusterControl, tudo o que temos a fazer é ir para o "Nodes ” e execute o trabalho “Rebuild Replication Slave”.
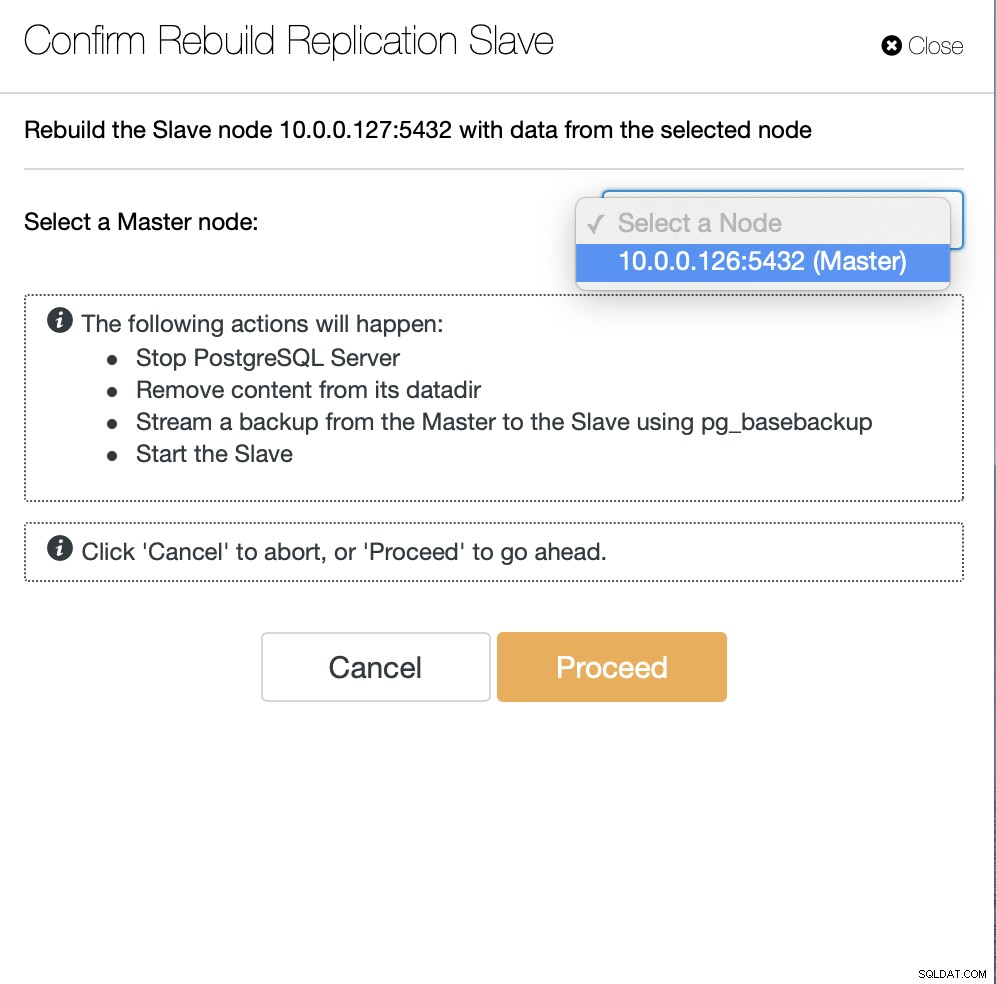
Em seguida, temos que escolher o nó para reconstruir o escravo e isso é tudo. O ClusterControl usará o pg_basebackup para configurar o slave de replicação e configurar a replicação assim que os dados forem transferidos.
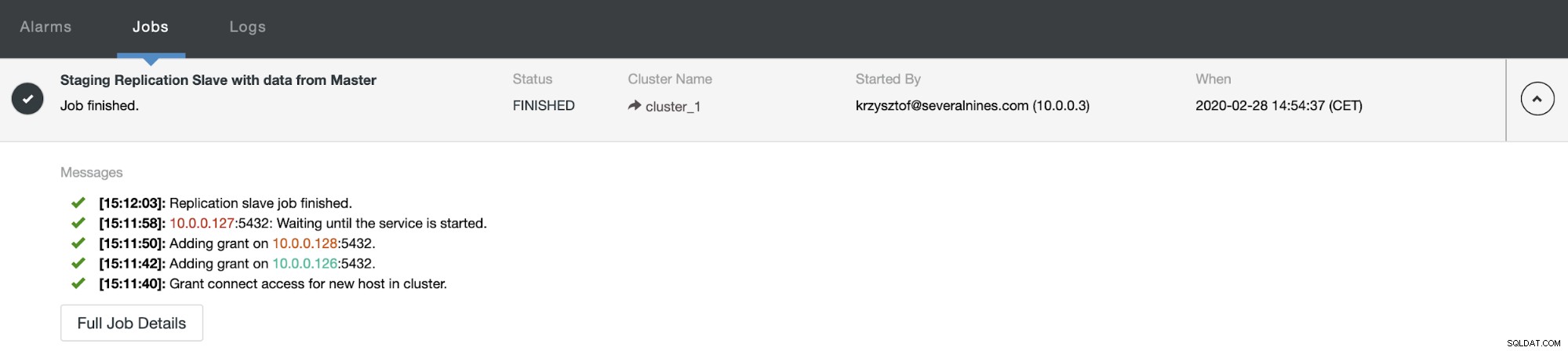
Depois de algum tempo, o trabalho é concluído e o escravo está de volta na cadeia de replicação:
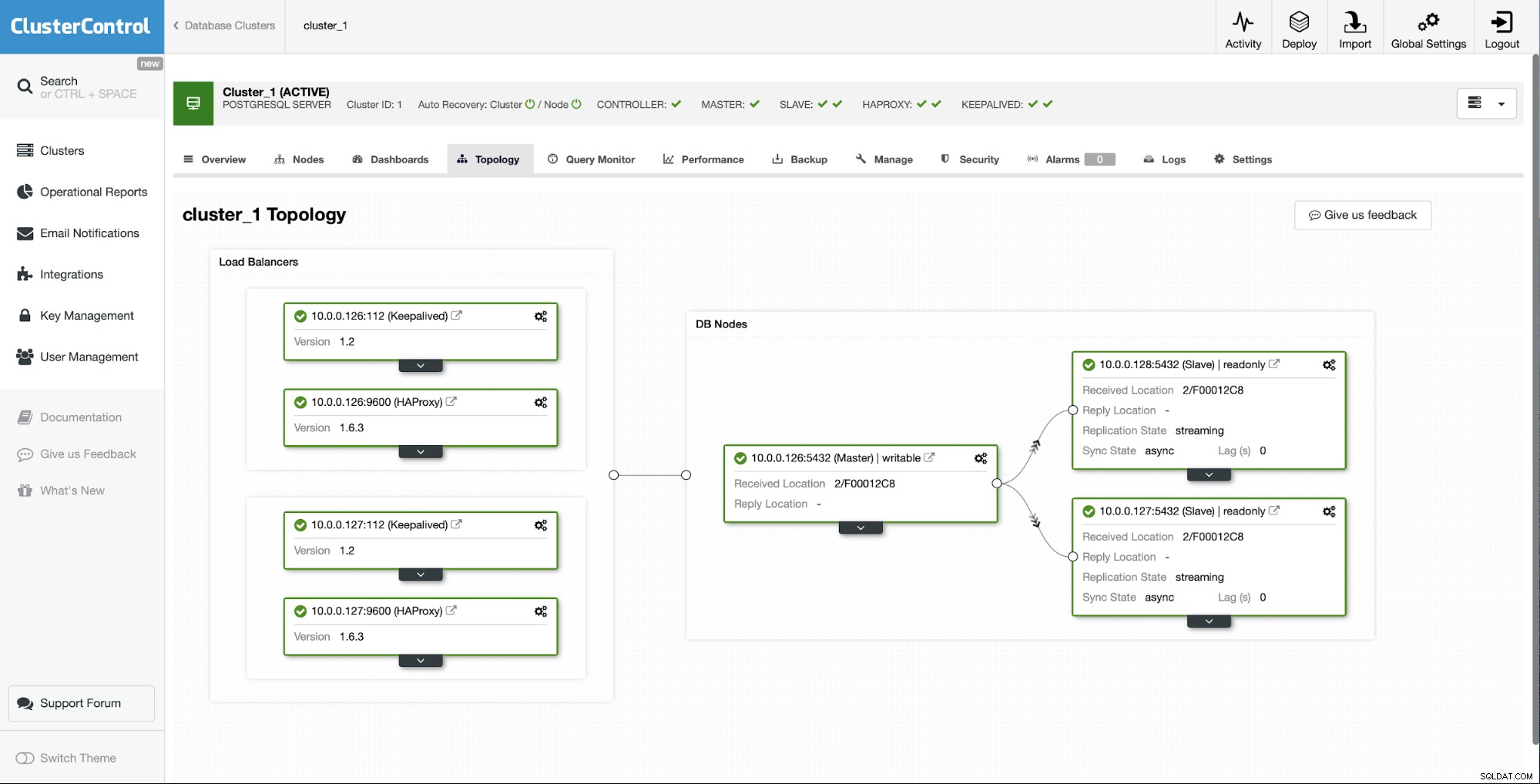
Como você pode ver, com apenas alguns cliques, graças ao ClusterControl, conseguimos reconstruir nosso escravo com falha e trazê-lo de volta ao cluster.



