Na minha última postagem, comecei uma série para cobrir verificações de integridade proativas que são vitais para o seu SQL Server. Começamos com o espaço em disco e, neste post, discutiremos as tarefas de manutenção. Uma das responsabilidades fundamentais de um DBA é garantir que as seguintes tarefas de manutenção sejam executadas regularmente:
- Backups
- Verificações de integridade
- Manutenção do índice
- Atualizações de estatísticas
Minha aposta é que você já tem empregos para gerenciar essas tarefas. E também aposto que você tem notificações configuradas para enviar e-mail para você e sua equipe se um trabalho falhar. Se ambas forem verdadeiras, você já está sendo proativo em relação à manutenção. E se você não estiver fazendo as duas coisas, isso é algo para corrigir agora – como, pare de ler isso, baixe os scripts de Ola Hallengren, agende-os e certifique-se de configurar as notificações. (Outra alternativa específica para manutenção de índices, que também recomendamos aos clientes, é o SQL Sentry Fragmentation Manager.)
Se você não sabe se seus trabalhos estão configurados para enviar e-mail se falharem, use esta consulta:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
No entanto, ser proativo em relação à manutenção vai um passo além. Além de apenas garantir que seus trabalhos sejam executados, você precisa saber quanto tempo eles levam. Você pode usar as tabelas do sistema no msdb para monitorar isso:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Ou, se você estiver usando os scripts e as informações de registro de Ola, poderá consultar sua tabela CommandLog:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
O script acima lista a duração do backup para cada backup completo do banco de dados AdventureWorks2014. Você pode esperar que as durações das tarefas de manutenção aumentem lentamente ao longo do tempo, à medida que os bancos de dados crescem. Como tal, você está procurando grandes aumentos ou diminuições inesperadas na duração. Por exemplo, eu tinha um cliente com uma duração média de backup inferior a 30 minutos. De repente, os backups começam a demorar mais de uma hora. O tamanho do banco de dados não mudou significativamente, nenhuma configuração foi alterada para a instância ou banco de dados, nada mudou com a configuração de hardware ou disco. Algumas semanas depois, a duração do backup caiu para menos de meia hora. Um mês depois disso, eles subiram novamente. Por fim, correlacionamos a alteração na duração do backup aos failovers entre os nós do cluster. Em um nó, os backups levaram menos de meia hora. Por outro, eles levaram mais de uma hora. Uma pequena investigação sobre a configuração das NICs e da malha SAN e conseguimos identificar o problema.
Compreender o tempo médio de execução das operações CHECKDB também é importante. Isso é algo sobre o qual Paul fala em nosso Evento de imersão de alta disponibilidade e recuperação de desastres:você deve saber quanto tempo o CHECKDB normalmente leva para ser executado, para que, se você encontrar corrupção e executar uma verificação em todo o banco de dados, saiba quanto tempo deve levar para CHECKDB para ser concluído. Quando seu chefe pergunta:“Quanto tempo falta para sabermos a extensão do problema?” você poderá fornecer uma resposta quantitativa do tempo mínimo que precisará esperar. Se CHECKDB demorar mais do que o normal, você sabe que encontrou algo (o que pode não ser necessariamente corrupção; você deve sempre deixar a verificação terminar).
Agora, se você estiver gerenciando centenas de bancos de dados, não deseja executar a consulta acima para todos os bancos de dados ou todos os trabalhos. Em vez disso, talvez você queira apenas encontrar trabalhos que estejam fora da duração média em uma determinada porcentagem, que você pode obter usando esta consulta:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Esta consulta lista os trabalhos que demoraram 25% a mais do que a média. A consulta exigirá alguns ajustes para fornecer as informações específicas que você deseja - alguns trabalhos com duração pequena (por exemplo, menos de 5 minutos) aparecerão se levarem apenas alguns minutos extras - isso pode não ser uma preocupação. No entanto, esta consulta é um bom começo, e perceba que existem muitas maneiras de encontrar desvios – você também pode comparar cada execução com a anterior e procurar por tarefas que demoraram uma certa porcentagem a mais que a anterior.
Obviamente, a duração do trabalho é o identificador mais lógico a ser usado para possíveis problemas – seja um trabalho de backup, uma verificação de integridade ou o trabalho que remove a fragmentação e atualiza as estatísticas. Descobri que a maior variação na duração geralmente está nas tarefas para remover a fragmentação e atualizar as estatísticas. Dependendo de seus limites para reorganização versus reconstrução, e a volatilidade de seus dados, você pode passar dias com reorganizações e, de repente, ter algumas reconstruções de índice para tabelas grandes, onde essas reconstruções alteram completamente a duração média. Você pode querer alterar seus limites para alguns índices ou ajustar o fator de preenchimento para que as reconstruções ocorram com mais ou menos frequência – dependendo do índice e do nível de fragmentação. Para fazer esses ajustes, você precisa observar com que frequência cada índice é reconstruído ou reorganizado, o que você só pode fazer se estiver usando os scripts do Ola e logando na tabela CommandLog, ou se tiver lançado sua própria solução e estiver registrando cada reorganização ou reconstrução. Para ver isso usando a tabela CommandLog, você pode começar verificando quais índices são alterados com mais frequência:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
A partir dessa saída, você pode começar a ver quais tabelas (e, portanto, índices) têm mais volatilidade e, em seguida, determinar se o limite para reorganização versus reconstrução precisa ser ajustado ou o fator de preenchimento modificado.
Facilitando a vida
Agora, existe uma solução mais fácil do que escrever suas próprias consultas, desde que você esteja usando o SQL Sentry Event Manager (EM). A ferramenta monitora todos os trabalhos do Agente configurados em uma instância e, usando a visualização do calendário, você pode ver rapidamente quais trabalhos falharam, foram cancelados ou executados por mais tempo que o normal:
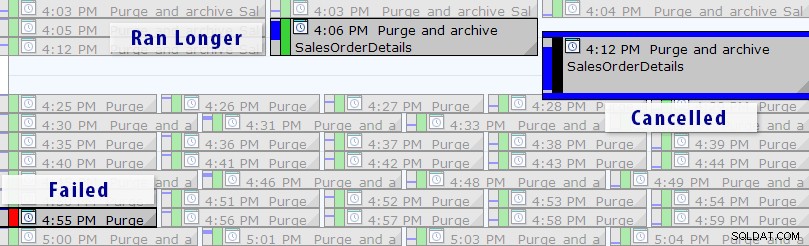 Visualização de calendário do SQL Sentry Event Manager (com rótulos adicionados no Photoshop)
Visualização de calendário do SQL Sentry Event Manager (com rótulos adicionados no Photoshop) Você também pode detalhar execuções individuais para ver quanto tempo demorou para um trabalho ser executado, e também há gráficos de tempo de execução úteis que permitem visualizar rapidamente quaisquer padrões em anomalias de duração ou condições de falha. Nesse caso, posso ver que a cada 15 minutos, a duração do tempo de execução para esse trabalho específico aumentou quase 400%:
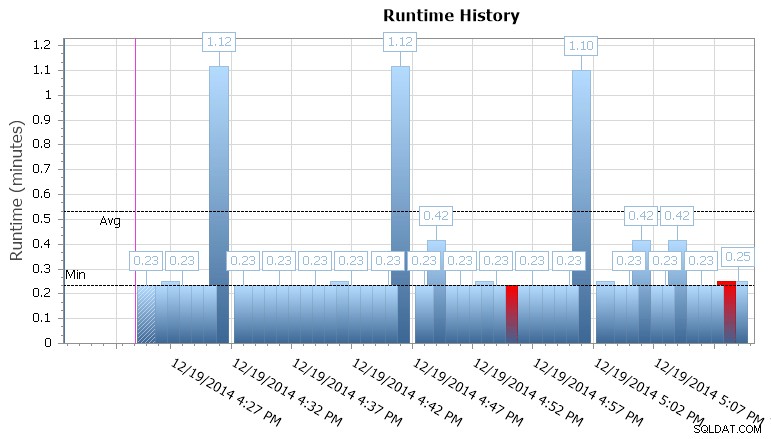 Gráfico de tempo de execução do SQL Sentry Event Manager
Gráfico de tempo de execução do SQL Sentry Event Manager Isso me dá uma pista de que devo analisar outros trabalhos agendados que podem estar causando alguns problemas de simultaneidade aqui. Eu poderia diminuir o zoom no calendário novamente para ver quais outros trabalhos estão sendo executados ao mesmo tempo, ou talvez nem precise olhar para reconhecer que este é um trabalho de relatório ou backup executado nesse banco de dados.
Resumo
Aposto que a maioria de vocês já tem os trabalhos de manutenção necessários e que também tem notificações configuradas para falhas de trabalho. Se você não estiver familiarizado com as durações médias de seus trabalhos, esse é o próximo passo para ser proativo. Observação:você também pode precisar verificar por quanto tempo está retendo o histórico de trabalhos. Ao procurar desvios na duração do trabalho, prefiro analisar os dados de alguns meses, em vez de algumas semanas. Você não precisa memorizar esses tempos de execução, mas depois de verificar se está mantendo dados suficientes para ter o histórico a ser usado para pesquisa, comece a procurar variações regularmente. Em um cenário ideal, o aumento do tempo de execução pode alertá-lo sobre um possível problema, permitindo que você o resolva antes que ocorra um problema em seu ambiente de produção.



