À medida que 2014 termina, estou iniciando uma série de postagens sobre verificações de integridade proativas do SQL Server, com base em uma que escrevi no início deste ano – Problemas de desempenho:o primeiro encontro. Nesse post, discuti o que procuro primeiro ao solucionar um problema de desempenho em um ambiente desconhecido. Nesta série de posts, quero falar sobre o que procuro quando faço check-in com meus clientes de longo prazo. Fornecemos um serviço de DBA Remoto e uma de nossas tarefas regulares é uma “mini” auditoria mensal de integridade de seu ambiente. Temos monitoramento e, normalmente, estou trabalhando em projetos, então estou no ambiente regularmente. Mas, como uma etapa adicional para garantir que não estamos perdendo nada, uma vez por mês analisamos os mesmos dados que coletamos em nossa auditoria de saúde padrão e procuramos algo fora do comum. Isso pode ser muitas coisas, certo? Sim! Então, vamos começar com o espaço.
Uau, espaço? Sim, espaço. Não se preocupe, eu vou chegar a outros tópicos. ☺
O que verificar
Por que eu começaria com o espaço? Porque é algo que muitas vezes vejo negligenciado e, se você ficar sem espaço em disco para seus arquivos de banco de dados, ficará extremamente limitado no que pode fazer em seu banco de dados. Precisa adicionar dados, mas não pode aumentar o arquivo porque o disco está cheio? Desculpe, agora os usuários não podem adicionar dados. Não está fazendo backups de log por algum motivo, então o log de transações enche a unidade? Desculpe, agora você não pode modificar nenhum dado. O espaço é crítico. Temos trabalhos que monitoram o espaço livre no disco e nos arquivos, mas ainda verifico o seguinte para cada auditoria e comparo os valores com os do mês anterior:
- Tamanho de cada arquivo de registro
- Tamanho de cada arquivo de dados
- Espaço livre em cada arquivo de dados
- Espaço livre em cada unidade com arquivos de banco de dados
- Espaço livre em cada unidade com arquivos de backup
Crescimento do arquivo de log
A maioria dos problemas que vejo relacionados ao espaço em disco são devido ao crescimento do arquivo de log. O crescimento geralmente ocorre por um dos dois motivos:
- O banco de dados está em recuperação COMPLETA e os backups de log de transações não estão sendo feitos por algum motivo
- Alguém executa uma única transação muito grande que consome todo o espaço de log existente, forçando o arquivo a crescer
Também vi o arquivo de log crescer como parte da manutenção do índice. Para reconstruções, cada alocação é registrada em log e para índices grandes, que podem gerar uma quantidade significativa de log. Mesmo com backups de log de transações regulares, o log ainda pode crescer mais rápido do que os backups podem ocorrer. Para gerenciar o log, você precisa ajustar a frequência de backup ou modificar sua metodologia de manutenção de índice.
Você precisa determinar por que o arquivo de log cresceu, o que pode ser complicado, a menos que você o esteja rastreando. Eu tenho um trabalho que é executado a cada hora para capturar o tamanho e o uso do arquivo de log:
USE [Baselines];
GO
IF (NOT EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'dbo'
AND TABLE_NAME = 'SQLskills_TrackLogSpace'))
BEGIN
CREATE TABLE [dbo].[SQLskills_TrackLogSpace](
[DatabaseName] [VARCHAR](250) NULL,
[LogSizeMB] [DECIMAL](38, 0) NULL,
[LogSpaceUsed] [DECIMAL](38, 0) NULL,
[LogStatus] [TINYINT] NULL,
[CaptureDate] [DATETIME2](7) NULL
) ON [PRIMARY];
ALTER TABLE [dbo].[SQLskills_TrackLogSpace] ADD DEFAULT (SYSDATETIME()) FOR [CaptureDate];
END
CREATE TABLE #LogSpace_Temp (
DatabaseName VARCHAR(100),
LogSizeMB DECIMAL(10,2),
LogSpaceUsed DECIMAL(10,2),
LogStatus VARCHAR(1)
);
INSERT INTO #LogSpace_Temp EXEC('dbcc sqlperf(logspace)');
INSERT INTO Baselines.dbo.SQLskills_TrackLogSpace
(DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus)
SELECT DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus
FROM #LogSpace_Temp;
DROP TABLE #LogSpace_Temp; Eu uso essas informações para determinar quando o arquivo de log começou a crescer e começo a examinar os logs e o histórico de trabalhos para ver quais informações adicionais posso encontrar. O crescimento do log deve ser estático – o log deve ser dimensionado e gerenciado adequadamente por meio de backups (se estiver executando em recuperação COMPLETA) e, se o arquivo precisar ser maior, preciso entender o motivo e redimensioná-lo adequadamente.
Se você estiver lidando com esse problema e ainda não estiver rastreando proativamente os eventos de crescimento de arquivos, ainda poderá descobrir o que aconteceu. Os eventos de crescimento automático são capturados pelo SQL Server; Aaron Bertrand, do SQL Sentry, fez um blog sobre isso em 2007, onde mostra como descobrir quando esses eventos aconteceram (desde que sejam recentes o suficiente para ainda existirem no rastreamento padrão).
Tamanho e espaço livre em arquivos de dados
Você provavelmente já ouviu falar que seus arquivos de dados devem ser pré-dimensionados para que não precisem crescer automaticamente. Se você seguir esta orientação, provavelmente não experimentou o evento em que o arquivo de dados cresce inesperadamente. Mas se você não estiver gerenciando seus arquivos de dados, provavelmente terá um crescimento ocorrendo regularmente – quer você perceba ou não (especialmente com as configurações de crescimento padrão de 10% e 1 MB).
Há um truque para pré-dimensionar arquivos de dados – você não quer dimensionar um banco de dados muito grande, porque lembre-se, se você restaurar, digamos, um ambiente de desenvolvimento ou controle de qualidade, os arquivos terão o mesmo tamanho, mesmo que sejam não está cheio de dados. Mas você ainda deseja gerenciar manualmente o crescimento. Acho que os DBAs têm mais dificuldade com novos bancos de dados. Os usuários de negócios não têm idéia sobre as taxas de crescimento e quantos dados estão sendo adicionados, e esse banco de dados é um canhão solto em seu ambiente. Você precisa prestar muita atenção a esses arquivos até ter uma noção do tamanho e do crescimento esperado. Eu uso uma consulta que fornece informações sobre o tamanho e o espaço livre:
SELECT
[file_id] AS [File ID],
[type] AS [File Type],
substring([physical_name],1,1) AS [Drive],
[name] AS [Logical Name],
[physical_name] AS [Physical Name],
CAST([size] as DECIMAL(38,0))/128. AS [File Size MB],
CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128. AS [Space Used MB],
(CAST([size] AS DECIMAL(38,0))/128) - (CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128.) AS [Free Space],
[max_size] AS [Max Size],
[is_percent_growth] AS [Percent Growth Enabled],
[growth] AS [Growth Rate],
SYSDATETIME() AS [Current Date]
FROM sys.database_files; Todos os meses, verifico o tamanho dos arquivos de dados e o espaço usado, depois decido se o tamanho precisa ser aumentado. Também monitoro o rastreamento padrão para eventos de crescimento, pois isso me informa exatamente quando ocorre o crescimento. Com exceção de novos bancos de dados, sempre posso ficar à frente do crescimento automático de arquivos e tratá-lo manualmente. Tudo bem, quase sempre. Pouco antes das férias do ano passado, fui notificado pelo departamento de TI de um cliente sobre pouco espaço livre em uma unidade (mantenha esse pensamento para a próxima seção). Agora, a notificação é baseada em um limite inferior a 20% gratuito. Esta unidade tinha mais de 1 TB, então havia cerca de 150 GB livres quando verifiquei a unidade. Ainda não era uma emergência, mas eu precisava entender para onde o espaço tinha ido.
Ao verificar os arquivos de banco de dados de um banco de dados, pude ver que eles estavam cheios – e no mês anterior cada arquivo tinha mais de 50 GB livres. Em seguida, pesquisei os tamanhos das tabelas e descobri que em uma tabela, mais de 270 milhões de linhas foram adicionadas nos últimos 16 dias – totalizando mais de 100 GB de dados. Acontece que houve uma modificação no código e o novo código estava registrando mais informações do que o pretendido. Rapidamente configuramos um trabalho para limpar as linhas e recuperar o espaço livre nos arquivos (e eles corrigiram o código). No entanto, não consegui recuperar o espaço em disco – teria que reduzir os arquivos, e isso não era uma opção. Eu então tive que determinar quanto espaço restava no disco e decidir se era uma quantidade com a qual eu estava confortável ou não. Meu nível de conforto depende de saber quantos dados estão sendo adicionados por mês – a taxa de crescimento típica. E só sei quantos dados estão sendo adicionados porque monitoro o uso de arquivos e posso estimar quanto espaço será necessário para este mês, para este ano e para os próximos dois anos.
Espaço do Drive
Mencionei anteriormente que temos trabalhos para monitorar o espaço livre no disco. Isso é baseado em uma porcentagem, não em um valor fixo. Minha regra geral é enviar notificações quando menos de 10% do disco estiver livre, mas para algumas unidades, talvez seja necessário definir esse valor mais alto. Por exemplo, com uma unidade de 1 TB, sou notificado quando há menos de 100 GB livres. Com uma unidade de 100 GB, sou notificado quando há menos de 10 GB livres. Com uma unidade de 20 GB ... bem, você vê onde estou indo com isso. Esse limite precisa alertá-lo antes que haja um problema. Se eu tiver apenas 10 GB livres em uma unidade que hospeda um arquivo de log, talvez não tenha tempo suficiente para reagir antes que isso apareça como um problema para os usuários - dependendo da frequência com que estou verificando o espaço de tamanho livre e qual o problema é.
É muito fácil usar xp_fixeddrives para verificar o espaço livre, mas eu não recomendaria isso, pois não está documentado e o uso de procedimentos armazenados estendidos em geral foi preterido. Ele também não informa o tamanho total de cada unidade e pode não relatar todos os tipos de unidade que seus bancos de dados podem estar usando. Contanto que você esteja executando o SQL Server 2008R2 SP1 ou superior, você pode usar o sys.dm_os_volume_stats muito mais conveniente para obter as informações necessárias, pelo menos sobre as unidades onde existem arquivos de banco de dados:
SELECT DISTINCT vs.volume_mount_point AS [Drive], vs.logical_volume_name AS [Drive Name], vs.total_bytes/1024/1024 AS [Drive Size MB], vs.available_bytes/1024/1024 AS [Drive Free Space MB] FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) AS vs ORDER BY vs.volume_mount_point;
Muitas vezes vejo um problema com o espaço em disco em volumes que hospedam tempdb. Perdi a conta das vezes que tive clientes com crescimento inexplicável de tempdb. Às vezes são apenas alguns GB; mais recentemente foi de 200 GB. Tempdb é uma fera complicada - não há fórmula a seguir ao dimensioná-lo e, muitas vezes, é colocado em uma unidade com pouco espaço livre que não pode lidar com o evento maluco causado pelo desenvolvedor novato ou DBA. Dimensionar os arquivos de dados tempdb requer que você execute sua carga de trabalho para um ciclo de negócios “normal” para determinar quanto ele usa tempdb e, em seguida, dimensione-o adequadamente.
Recentemente, ouvi uma sugestão de uma maneira de evitar ficar sem espaço em uma unidade:crie um banco de dados sem dados e dimensione os arquivos para que eles consumam o espaço que você deseja "reservar". Então, se você tiver algum problema, basta soltar o banco de dados e violar, você tem espaço livre novamente. Pessoalmente, acho que isso cria todos os tipos de outros problemas e não o recomendaria. Mas se você tiver administradores de armazenamento que não gostam de ver centenas de GBs não utilizados em uma unidade, essa seria uma maneira de fazer uma unidade “parecer” cheia. Isso me lembra algo que ouvi um bom amigo meu dizer:“Se eu não posso trabalhar com você, vou trabalhar ao seu redor”.
Backups
Uma das principais tarefas de um DBA é proteger os dados. Os backups são um método usado para protegê-lo e, como tal, as unidades que mantêm esses backups são parte integrante da vida de um DBA. Presumivelmente, você está mantendo um ou mais backups online, para restaurar imediatamente, se necessário. Seu livro de execução de SLA e DR ajuda a ditar quantos backups você mantém online, e você deve garantir que esse espaço esteja disponível. Eu defendo que você também não exclua backups antigos até que o backup atual seja concluído com sucesso. É muito fácil cair na armadilha de excluir backups antigos e executar o backup atual. Mas o que acontece se o backup atual falhar? E o que acontece se você estiver usando compressão? Espere um segundo… os backups compactados são menores, certo? Eles são menores, no final. Mas você sabia que o tamanho do arquivo .bak geralmente começa maior que o tamanho final? Você pode usar o sinalizador de rastreamento 3042 para alterar esse comportamento, mas deve estar pensando que, com backups, precisa de muito espaço. Se seu backup for de 100 GB e você estiver mantendo o valor de 3 dias online, precisará de 300 GB para os 3 dias de backups e, provavelmente, uma quantidade saudável (2X o tamanho atual do banco de dados) livre para o próximo backup. Sim, isso significa que a qualquer momento você terá muito mais de 100 GB livres nesta unidade. Isso está ok. É melhor do que ter o trabalho de exclusão bem-sucedido e o trabalho de backup falhar e descobrir três dias depois que você não tem backups (isso aconteceu com um cliente no meu trabalho anterior).
A maioria dos bancos de dados aumenta com o tempo, o que significa que os backups também aumentam. Não se esqueça de verificar regularmente o tamanho dos arquivos de backup e alocar espaço adicional conforme necessário – ter uma política de “200 GB livres” para um banco de dados que cresceu para 350 GB não será muito útil. Se os requisitos de espaço mudarem, certifique-se de alterar também os alertas associados.
Usando o Performance Advisor
Existem várias consultas incluídas neste post que você pode usar para monitorar o espaço, se precisar rolar seu próprio processo. Mas se você tiver o SQL Sentry Performance Advisor em seu ambiente, isso fica muito mais fácil com as Condições Personalizadas. Existem várias condições de estoque incluídas por padrão, mas você também pode criar as suas próprias.
No cliente SQL Sentry, abra o Navegador, clique com o botão direito do mouse em Shared Groups (Global) e selecione Add Custom Condition → SQL Sentry. Forneça um nome e uma descrição para a condição, adicione uma comparação numérica e altere o tipo para Consulta de repositório. Digite a consulta:
SELECT MIN(FreeSpace*100.0/Size) FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk;
Altere Igual a Is less than e defina um Explicit Value de 10. Por fim, altere a Default Evaluation Frequency para algo menos frequente do que a cada 10 segundos. Uma vez por dia ou uma vez a cada 12 horas é provavelmente um bom valor – você não deve precisar verificar o espaço livre com mais frequência do que uma vez por dia, mas pode verificar quantas vezes quiser. A captura de tela abaixo mostra a configuração final:
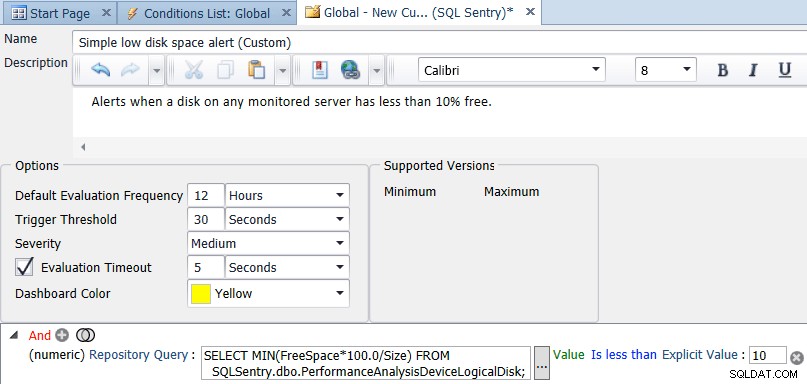
Depois de clicar em salvar para a condição, você será perguntado se deseja atribuir ações para a condição personalizada. A opção Enviar para canais de alerta é selecionada por padrão, mas você pode querer executar outras tarefas, como Executar um trabalho – digamos, copiar backups antigos para outro local (se for a unidade com pouco espaço).
Como mencionei anteriormente, um padrão de 10% de espaço livre para todas as unidades provavelmente não é apropriado para todas as unidades em seu ambiente. Você pode personalizar a consulta para diferentes instâncias e unidades, por exemplo:
SELECT Alert = MAX(CASE WHEN Name = N'C:' AND [FreeSpace%] < 10 THEN 1 WHEN Name = N'S:' AND [FreeSpace%] < 25 THEN 1 WHEN Name = N'T:' AND [FreeSpace%] < 20 THEN 1 ELSE 0 END) FROM ( SELECT d.Name, d.FreeSpace * 100.0/d.Size AS [FreeSpace%] FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk AS d INNER JOIN SQLSentry.dbo.EventSourceConnection AS c ON d.DeviceID = c.DeviceID WHERE c.ObjectName = N'HANK\SQL2012' -- replace with your server/instance ) AS s;
Você pode alterar e expandir essa consulta conforme necessário para seu ambiente e, em seguida, alterar a comparação na condição de acordo (basicamente avaliando como true se o resultado for 1):
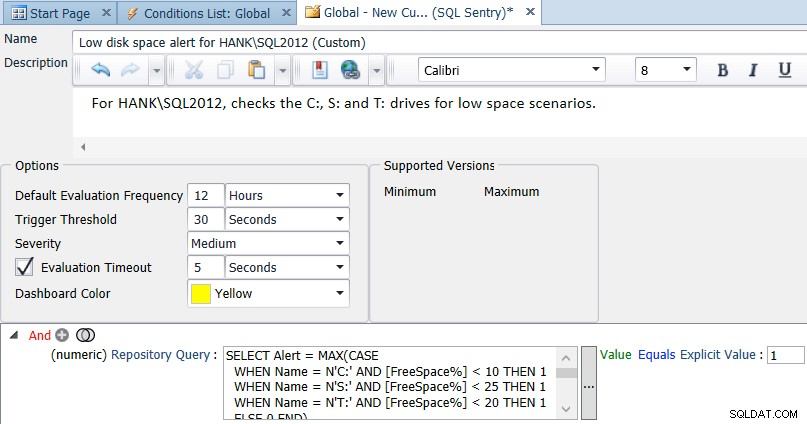
Se você quiser ver o Performance Advisor em ação, sinta-se à vontade para baixar uma avaliação.
Observe que para ambas as condições, você só será alertado uma vez, mesmo que várias unidades fiquem abaixo do seu limite. Em ambientes complexos, você pode optar por um número maior de condições mais específicas para fornecer alertas mais flexíveis e personalizados, em vez de menos condições “pega-tudo”.
Resumo
Há muitos componentes críticos em um ambiente SQL Server, e o espaço em disco precisa ser monitorado e mantido proativamente. Com apenas um pouco de planejamento, isso é simples de fazer e alivia muitas incógnitas e resolução de problemas reativa. Se você usa seus próprios scripts ou uma ferramenta de terceiros, garantir que haja bastante espaço livre para arquivos de banco de dados e backups é um problema facilmente solucionável e que vale a pena o esforço.



