De cabeça, tenho uma solução de 50% para você.
O problema
SSIS realmente se preocupa com metadados, de modo que variações neles tendem a resultar em exceções. DTS foi muito mais indulgente nesse sentido. Essa forte necessidade de metadados consistentes torna o uso do Flat File Source problemático.
Solução baseada em consultas
Se o problema for o componente, não vamos usá-lo. O que eu gosto nessa abordagem é que, conceitualmente, é o mesmo que consultar uma tabela - a ordem das colunas não importa nem a presença de colunas extras.
Variáveis
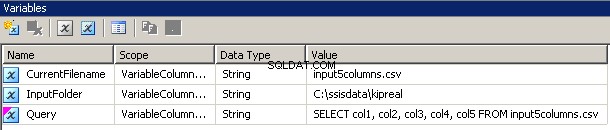
Criei 3 variáveis, todas do tipo string:CurrentFileName, InputFolder e Query.
- InputFolder está conectado à pasta de origem. No meu exemplo, é
C:\ssisdata\Kipreal - CurrentFileName é o nome de um arquivo. Durante o tempo de design, era
input5columns.csvmas isso mudará em tempo de execução. - Consulta é uma expressão
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Gerenciador de conexões
Configure uma conexão com o arquivo de entrada usando o driver JET OLEDB. Depois de criá-lo conforme descrito no artigo vinculado, renomeei-o para FileOLEDB e defini uma expressão no ConnectionManager de
"Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";" Fluxo de controle
Meu fluxo de controle se parece com uma tarefa de fluxo de dados aninhada em um enumerador de arquivo Foreach
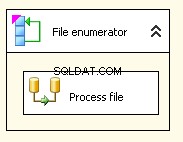
Enumerador de arquivo Foreach
Meu enumerador de arquivo Foreach está configurado para operar em arquivos. Eu coloquei uma expressão no diretório para
@[User::InputFolder] Observe que, neste ponto, se o valor dessa pasta precisar ser alterado, ele será atualizado corretamente no Connection Manager e no enumerador de arquivos. Em "Recuperar nome do arquivo", em vez do padrão "Totalmente qualificado", escolha "Nome e extensão" 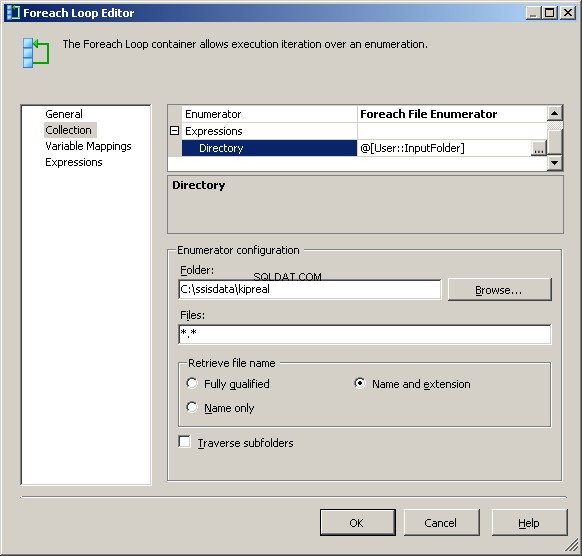
Na guia Mapeamentos de Variáveis, atribua o valor ao nosso
@[User::CurrentFileName] variável 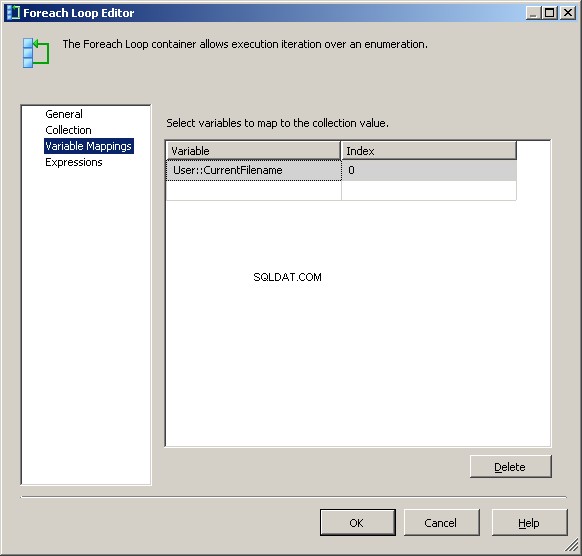
Neste ponto, cada iteração do loop alterará o valor do
@[User::Query para refletir o nome do arquivo atual. Fluxo de dados
Esta é realmente a peça mais fácil. Use uma fonte OLE DB e conecte-a conforme indicado.
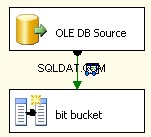
Use o gerenciador de conexões FileOLEDB e altere o modo de acesso a dados para "Comando SQL da variável". Use o
@[User::Query] variável lá, clique em OK e você está pronto para trabalhar. 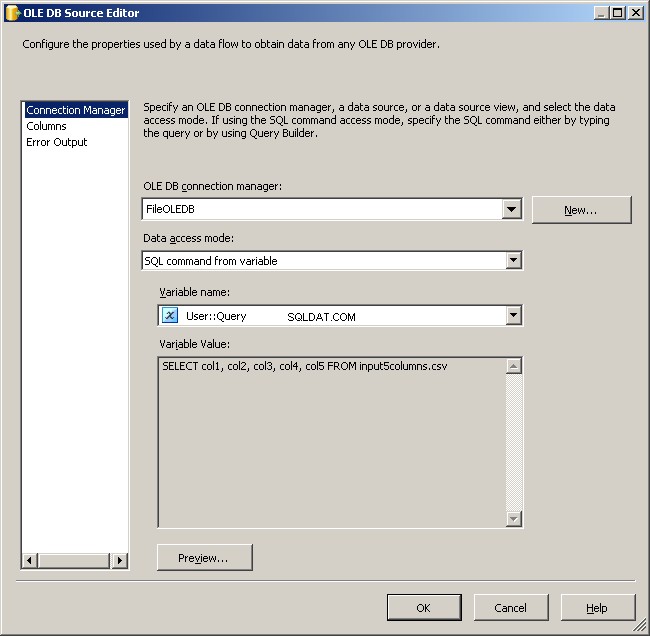
Dados de amostra
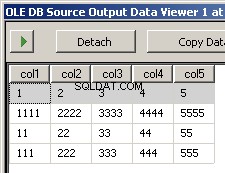
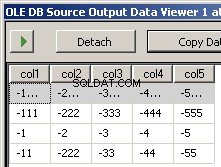
Eu criei dois arquivos de amostra input5columns.csv e input7columns.csv Todas as colunas de 5 estão em 7, mas 7 as tem em uma ordem diferente (col2 é a posição ordinal 2 e 6). Eu neguei todos os valores em 7 para tornar facilmente aparente qual arquivo está sendo operado.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
e
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
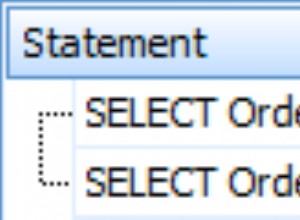
A execução do pacote resulta nessas duas capturas de tela
O que está faltando
Não conheço uma maneira de informar à abordagem baseada em consulta que está tudo bem se uma coluna não existir. Se houver uma chave exclusiva, suponho que você possa definir sua consulta para ter apenas as colunas que devem estar lá e, em seguida, realizar pesquisas no arquivo para tentar obter as colunas que deveriam estar lá e não falhar na pesquisa se a coluna não existir. Embora bastante kludgey.