O princípio "Não se repita" sugere que você deve reduzir a repetição. Esta semana me deparei com um caso em que DRY deveria ser jogado pela janela. Existem outros casos também (por exemplo, funções escalares), mas este foi interessante envolvendo lógica Bitwise.
Vamos imaginar a seguinte tabela:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); Os bits "WheelFlag" representam as seguintes opções:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Assim, as combinações possíveis são:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Vamos deixar de lado os argumentos, pelo menos por enquanto, sobre se isso deve ser empacotado em um único TINYINT em primeiro lugar, ou armazenado como colunas separadas, ou usar um modelo EAV... corrigir o design é uma questão separada. Trata-se de trabalhar com o que você tem.
Para tornar os exemplos úteis, vamos preencher esta tabela com vários dados aleatórios. (E vamos supor, para simplificar, que esta tabela contém apenas pedidos que ainda não foram enviados.) Isso inserirá 50.000 linhas de distribuição aproximadamente igual entre as seis combinações de opções:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Se olharmos para a repartição, podemos ver essa distribuição. Observe que seus resultados podem diferir um pouco dos meus dependendo dos objetos em seu sistema:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Resultados:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Agora, digamos que é terça-feira, e acabamos de receber uma remessa de rodas de 18", que estavam esgotadas anteriormente. Isso significa que podemos atender a todos os pedidos que exigem rodas de 18" - tanto aqueles que atualizaram pneus (6), e aqueles que não (2). Então, *poderíamos* escrever uma consulta como a seguinte:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); Na vida real, é claro, você não pode realmente fazer isso; e se mais opções forem adicionadas posteriormente, como travas de roda, garantia vitalícia de roda ou várias opções de pneus? Você não quer ter que escrever uma série de valores IN() para cada combinação possível. Em vez disso, podemos escrever uma operação BITWISE AND, para encontrar todas as linhas onde o 2º bit está definido, como:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; Isso me dá os mesmos resultados que a consulta IN(), mas se eu compará-los usando o SQL Sentry Plan Explorer, o desempenho é bem diferente:

É fácil perceber porquê. A primeira usa uma busca de índice para isolar as linhas que satisfazem a consulta, com um filtro na coluna WheelFlag:
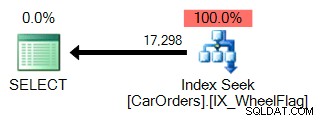

O segundo usa uma varredura, juntamente com uma conversão implícita e estatísticas terrivelmente imprecisas. Tudo devido ao operador BITWISE AND:
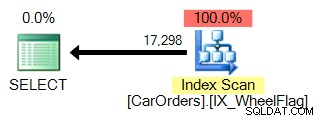


Então o que isso quer dizer? No fundo, isso nos diz que a operação BITWISE AND não é sargável .
Mas nem toda esperança está perdida.
Se ignorarmos o princípio DRY por um momento, podemos escrever uma consulta um pouco mais eficiente sendo um pouco redundante para aproveitar o índice na coluna WheelFlag. Assumindo que estamos atrás de qualquer opção WheelFlag acima de 0 (nenhuma atualização), podemos reescrever a consulta dessa maneira, informando ao SQL Server que o valor WheelFlag deve ser pelo menos o mesmo valor que o sinalizador (o que elimina 0 e 1 ) e, em seguida, adicionando as informações complementares que ele também deve conter esse sinalizador (eliminando assim 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
A parte>=desta cláusula é obviamente coberta pela parte BITWISE, então é aqui que violamos DRY. Mas como essa cláusula que adicionamos é sargável, relegando a operação BITWISE AND a uma condição de pesquisa secundária ainda produz o mesmo resultado, e a consulta geral produz melhor desempenho. Vemos uma busca de índice semelhante à versão codificada da consulta acima e, embora as estimativas estejam ainda mais distantes (algo que pode ser tratado como um problema separado), as leituras ainda são menores do que com a operação BITWISE AND sozinha:

Também podemos ver que um filtro é usado contra o índice, o que não vimos ao usar a operação BITWISE AND sozinha:

Conclusão
Não tenha medo de se repetir. Há momentos em que essas informações podem ajudar o otimizador; mesmo que não seja totalmente intuitivo *adicionar* critérios para melhorar o desempenho, é importante entender quando cláusulas adicionais ajudam a reduzir os dados para o resultado final, em vez de tornar "fácil" para o otimizador encontrar as linhas exatas sozinho.