A seguir, um trecho de nosso whitepaper “Como projetar ambientes de banco de dados de código aberto altamente disponíveis”, que pode ser baixado gratuitamente.
Algumas palavras sobre "Alta disponibilidade"
Atualmente, a alta disponibilidade é essencial para qualquer implantação séria. Longe vão os dias em que você poderia agendar um tempo de inatividade do seu banco de dados por várias horas para realizar uma manutenção. Se seus serviços não estiverem disponíveis, você está perdendo clientes e dinheiro. Portanto, tornar um ambiente de banco de dados altamente disponível geralmente é uma das prioridades mais altas.
Isso representa um desafio significativo para os administradores de banco de dados. Em primeiro lugar, como você sabe se seu ambiente está altamente disponível ou não? Como você mediria? Quais são as etapas que você precisa tomar para melhorar a disponibilidade? Como projetar sua configuração para torná-la altamente disponível desde o início?
Existem muitas soluções de alta disponibilidade disponíveis no ecossistema MySQL (e MariaDB), mas como sabemos em quais podemos confiar? Algumas soluções podem funcionar sob certas condições específicas, mas podem causar mais problemas quando aplicadas fora dessas condições. Mesmo uma funcionalidade básica como a replicação do MySQL, que pode ser configurada de várias maneiras, pode causar danos significativos - por exemplo, replicação circular com vários mestres graváveis. Embora seja fácil configurar uma 'configuração de vários mestres' usando a replicação, ela pode facilmente quebrar e nos deixar com conjuntos de dados divergentes em servidores diferentes. Para um banco de dados, que muitas vezes é considerado a única fonte de verdade, a integridade de dados comprometida pode ter consequências catastróficas.
Nos capítulos a seguir, discutiremos os requisitos para alta disponibilidade em configurações
do banco de dados e como projetar o sistema desde o início.
Medindo a alta disponibilidade
O que é alta disponibilidade? Para poder decidir se um determinado ambiente é altamente disponível ou não, é preciso ter algumas métricas para isso. Existem várias maneiras de medir a alta disponibilidade, vamos nos concentrar em algumas das coisas mais básicas.
Primeiro, porém, vamos pensar sobre o que é toda essa alta disponibilidade? Qual é seu propósito? Trata-se de garantir que seu ambiente atenda ao seu propósito. O propósito pode ser definido de várias maneiras, mas, normalmente, será sobre a entrega de algum serviço. No mundo do banco de dados, normalmente está um pouco relacionado aos dados. Pode estar servindo dados para seu aplicativo interno. Pode ser armazenar dados e torná-los consultáveis por processos analíticos. Pode ser armazenar alguns dados para seus usuários e fornecê-los quando solicitados sob demanda. Uma vez que tenhamos clareza sobre o propósito, podemos estabelecer os fatores de sucesso envolvidos. Isso nos ajudará a definir o que significa alta disponibilidade em nosso caso específico.
SLAs
Acordo de Nível de Serviço (SLA). Também é bastante comum definir SLA’s para serviços internos. O que é um SLA? É uma definição do nível de serviço que você planeja fornecer aos seus clientes. Isso é para que eles entendam melhor qual nível de estabilidade você planeja para um serviço que eles compraram ou planejam comprar. Existem vários métodos que você pode aproveitar para preparar um SLA, mas os mais comuns são:
- Disponibilidade do serviço (porcentagem)
- Resposta do serviço - latência (média, máx., percentil 95, percentil 99)
- Perda de pacotes na rede (porcentagem)
- Rendimento (média, mínimo, percentil 95, percentil 99)
Pode ficar mais complexo do que isso, no entanto. Em um ambiente multiusuário fragmentado, você pode definir, digamos, seu SLA como:“O serviço estará disponível 99,99% do tempo, o tempo de inatividade é declarado quando mais de 2% dos usuários são afetados. Nenhum incidente pode levar mais de 15 minutos para ser resolvido”. Esse SLA também pode ser estendido para incorporar o tempo de resposta da consulta:“tempo de inatividade é chamado se 99 percentil de latência para consultas excederem 200 milissegundos”.
Noves
A disponibilidade é normalmente medida em "nove", vamos ver o que exatamente uma determinada quantidade de "nove" garante. A tabela abaixo foi retirada da Wikipedia:
| % de disponibilidade | Tempo de inatividade por ano | Tempo de inatividade por mês | Tempo de inatividade por semana | Tempo de inatividade por dia |
|---|---|---|---|---|
| 90% ("um nove") | 36,5 dias | 72 horas | 16,8 horas | 2,4 horas |
| 95% ("um e meio noves") | 18,25 dias | 36 horas | 8,4 horas | 1,2 hora |
| 97% | 10,96 dias | 21,6 horas | 5,04 horas | 43,2 min |
| 98% | 7,30 dias | 14,4 horas | 3,36 horas | 28,8 minutos |
| 99% ("dois noves") | 3,65 dias | 7,20 horas | 1,68 horas | 14,4 minutos |
| 99,5% ("dois noves e meio") | 1,83 dias | 3,60 horas | 50,4 min | 7,2 minutos |
| 99,8% | 17,52 horas | 86,23 min | 20,16 min | 2,88 minutos |
| 99,9% ("três noves") | 8,76 horas | 43,8 min | 10,1 min | 1,44 min |
| 99,95% ("três e meio noves") | 4,38 horas | 21,56 min | 5,04 minutos | 43,2 s |
| 99,99% ("quatro noves") | 52,56 min | 4,38 minutos | 1,01 min | 8,64 s |
| 99,995% ("quatro e meio noves") | 26,28 minutos | 2,16 minutos | 30,24 s | 4,32 s |
| 99,999% ("cinco noves") | 5,26 minutos | 25,9 s | 6,05 s | 864,3 ms |
| 99,9999% ("seis noves") | 31,5 s | 2,59 s | 604,8 ms | 86,4 ms |
| 99,99999% ("sete noves") | 3,15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999% ("oito noves") | 315,569 ms | 26,297 ms | 6,048 ms | 0,864 ms |
| 99,9999999% ("nove noves") | 31,5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Como podemos ver, isso aumenta rapidamente. Cinco noves (99.999% de disponibilidade) equivalem a 5,26 minutos de inatividade ao longo de um ano. A disponibilidade também pode ser calculada em diferentes intervalos menores:por mês, por semana, por dia. Tenha em mente esses números, pois eles serão úteis quando começarmos a discutir os custos associados à manutenção de diferentes níveis de disponibilidade.
Medindo a disponibilidade
Para saber se há um tempo de inatividade ou não, é preciso ter uma visão do ambiente. Você precisa acompanhar as métricas que definem a disponibilidade de seus sistemas. É importante ter em mente que você deve medi-lo do ponto de vista do cliente, levando em consideração o quadro mais amplo. Não importa se seus bancos de dados estão ativos se, digamos, devido a um problema de rede, nenhum aplicativo não puder alcançá-los. Cada bloco de construção de sua configuração tem seu impacto na disponibilidade.
Um dos bons lugares onde procurar dados de disponibilidade são os logs do servidor web. Todas as solicitações que terminaram com erros significam que algo aconteceu. Pode ser o erro HTTP 500 retornado pelo aplicativo, porque a conexão com o banco de dados falhou. Esses podem ser erros programáticos apontando para alguns problemas de banco de dados e que acabaram no log de erros do Apache. Você também pode usar métrica simples como tempo de atividade dos servidores de banco de dados, embora, com SLAs mais complexos, possa ser complicado determinar como a indisponibilidade de um banco de dados afetou sua base de usuários. Não importa o que você faça, você deve usar mais de uma métrica - isso é necessário para capturar problemas que podem ter acontecido em diferentes camadas do seu ambiente.
Número Mágico:“Três”
Embora a alta disponibilidade também tenha a ver com redundância, no caso de clusters de banco de dados, três é um número mágico. Não é suficiente ter dois nós para redundância - essa configuração não fornece alta disponibilidade integrada. Claro, pode ser melhor do que apenas um único nó, mas a intervenção humana é necessária para recuperar os serviços. Vejamos porque é assim.
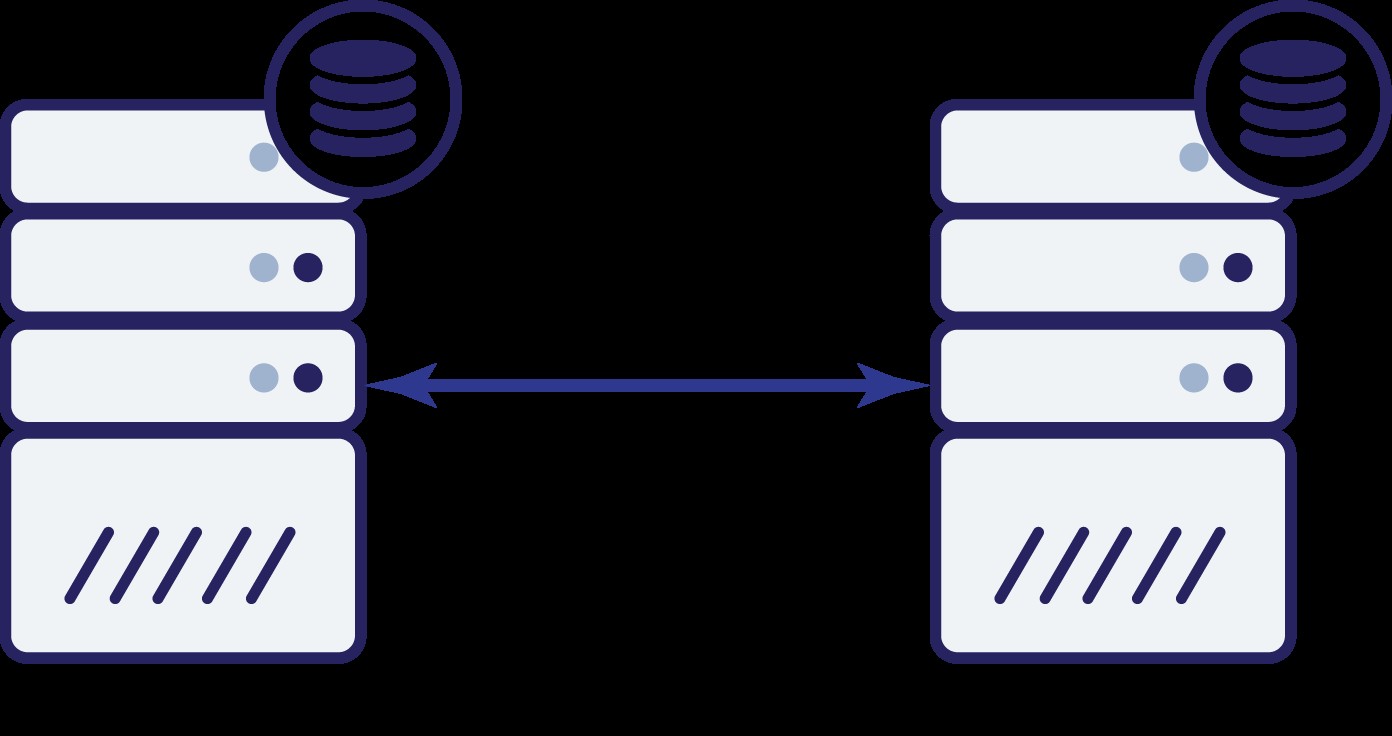
Vamos supor que temos dois nós, A e B. Há um link de rede entre eles. Vamos supor que tanto A quanto B servem gravações e o aplicativo escolhe aleatoriamente onde se conectar (o que significa que parte do aplicativo se conectará ao nó A e a outra parte se conectará ao nó B). Agora, vamos imaginar que temos um problema de rede que resulta na perda de conectividade de rede entre A e B.
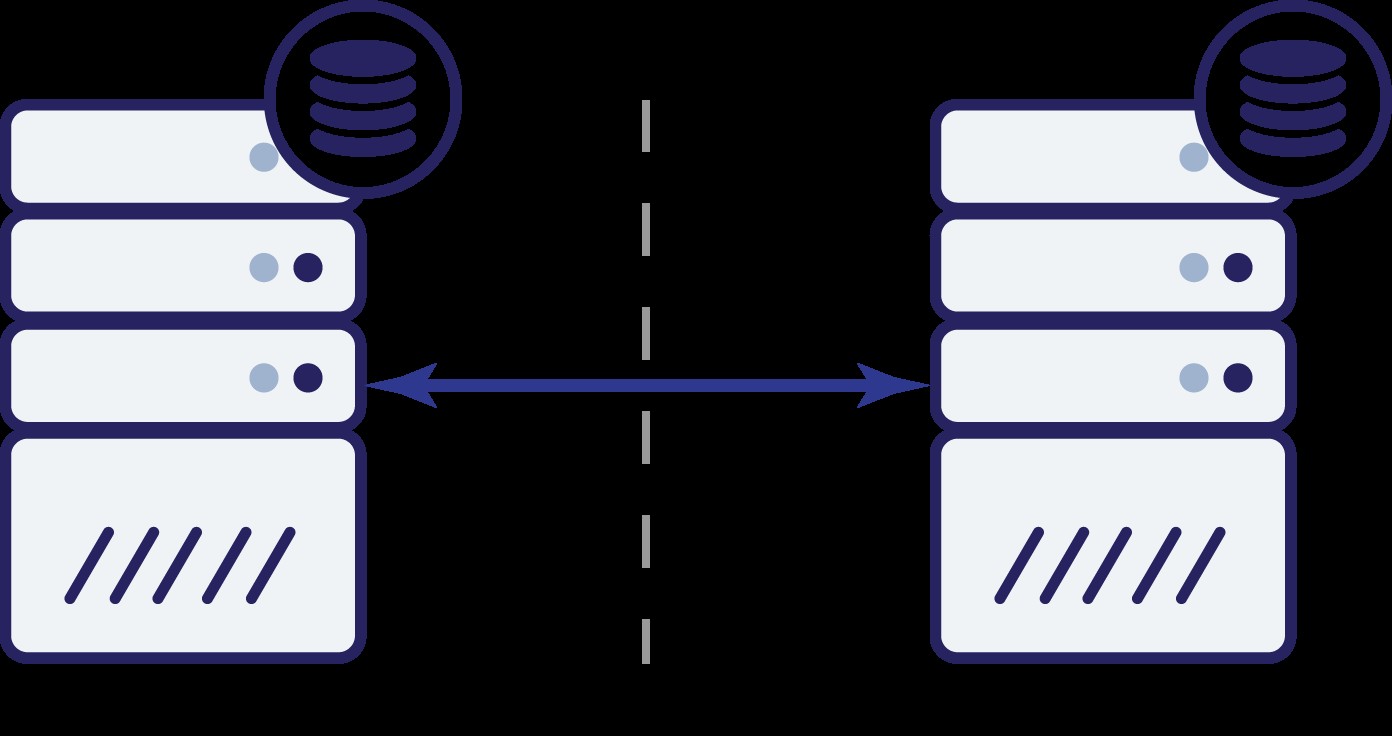
E agora? Nem A nem B podem saber o estado do outro nó. Existem duas ações que podem ser tomadas por ambos os nós:
- Eles podem continuar aceitando tráfego
- Eles podem deixar de operar e se recusar a atender qualquer tráfego
Vamos pensar na primeira opção. Desde que o outro nó esteja realmente inativo, esta é a ação preferencial a ser tomada - queremos que nosso banco de dados continue atendendo ao tráfego. Afinal, essa é a ideia principal por trás da alta disponibilidade. O que aconteceria, porém, se ambos os nós continuassem a aceitar tráfego enquanto estivessem desconectados um do outro? Novos dados serão adicionados em ambos os lados e os conjuntos de dados ficarão fora de sincronia. Quando o problema de rede for resolvido, será uma tarefa difícil mesclar esses dois conjuntos de dados. Portanto, não é aceitável manter ambos os nós funcionando. O problema é - como o nó A pode dizer se o nó B está vivo ou não (e vice-versa)? A resposta é - não pode. Se toda a conectividade estiver inativa, não há como distinguir um nó com falha de uma rede com falha. Como resultado, a única ação segura é que ambos os nós interrompam todas as operações e se recusem a atender
tráfego.
Vamos pensar agora como um terceiro nó pode nos ajudar em tal situação.
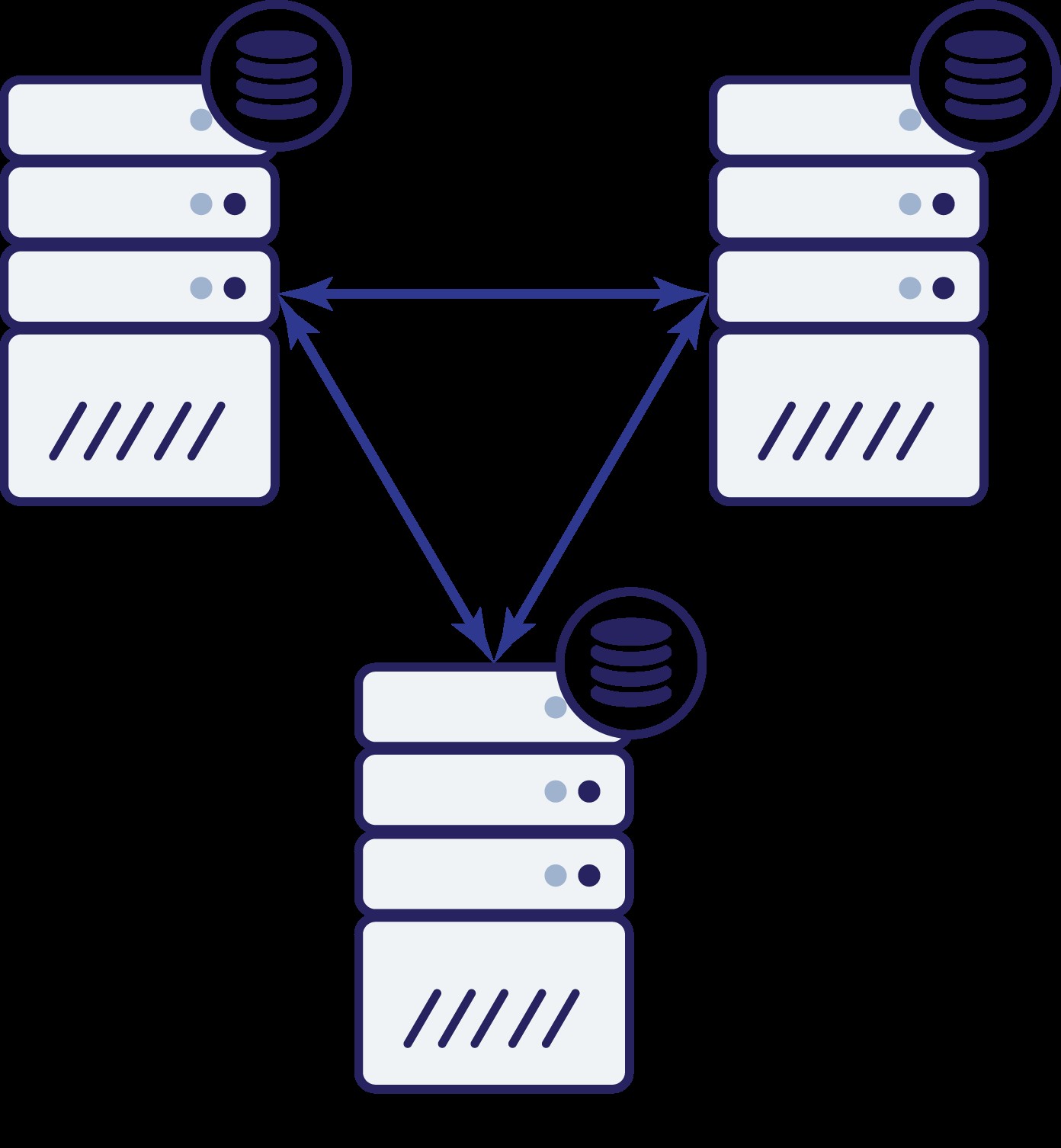
Portanto, agora temos três nós:A, B e C. Todos estão interconectados, todos estão lidando com leituras e gravações.
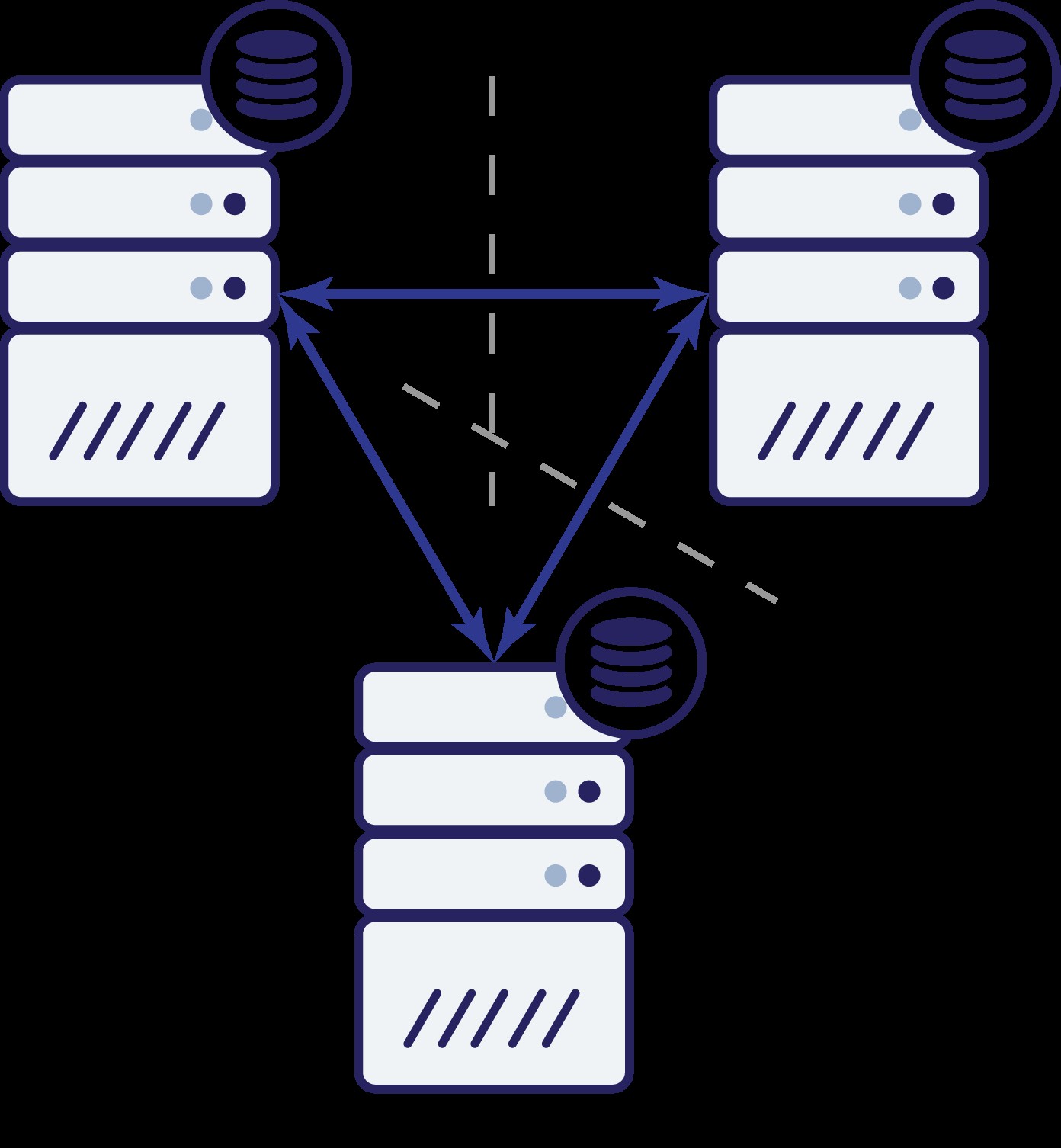
Novamente, como no exemplo anterior, o nó B foi cortado do resto do cluster devido a problemas de rede. O que pode acontecer a seguir? Bem, a situação é bastante semelhante ao que discutimos anteriormente. Duas opções - o nó B pode estar inativo (e o resto do cluster deve continuar) ou pode estar ativo, caso em que não deve ter permissão para lidar com nenhum tráfego. Podemos agora dizer qual é o estado do cluster? Na verdade sim. Podemos ver que os nós A e C podem conversar entre si e, como resultado, eles podem concordar que o nó B não está disponível. Eles não poderão dizer por que isso aconteceu, mas o que eles sabem é que de três nós no cluster, dois ainda têm conectividade entre si. Dado que esses dois nós formam a maioria do cluster, é possível continuar tratando o tráfego. Ao mesmo tempo, o nó B também pode deduzir que o problema está do seu lado. Ele não pode acessar nem o nó A nem o nó C, tornando o nó B separado do resto do cluster. Como é isolado e não faz parte de uma maioria (1 de 3), a única ação segura que pode tomar é parar de atender o tráfego e se recusar a aceitar qualquer consulta, garantindo que o desvio de dados não aconteça.
Claro, isso não significa que você pode ter apenas três nós no cluster. Se você deseja uma melhor tolerância a falhas, pode adicionar mais. No entanto, lembre-se de que deve ser um número ímpar se você quiser melhorar a alta disponibilidade. Além disso, estávamos falando sobre “nós” nos exemplos acima. Lembre-se de que isso também vale para datacenters, zonas de disponibilidade etc. Se você tiver dois datacenters, cada um com o mesmo número de nós (digamos, três nós cada) e perder a conectividade entre esses dois DCs, os mesmos princípios se aplicam aqui - você não pode dizer qual metade do cluster deve começar a lidar com o tráfego. Para poder dizer isso, você precisa ter um observador em um terceiro datacenter. Pode ser mais um conjunto de nós, ou apenas um único host, com a tarefa
de observar o estado dos dataceters restantes e tomar parte na tomada de decisões (um exemplo aqui seria o árbitro Galera).
Pontos únicos de falha
Alta disponibilidade significa remover pontos únicos de falha (SPOF) e não introduzir novos pontos no processo. O que são os SPOFs? Qualquer parte de sua infraestrutura que, quando falha, causa tempo de inatividade conforme definido no SLA, é chamada de SPOF. O projeto de infraestrutura requer uma abordagem holística, os diferentes componentes não podem ser projetados independentemente uns dos outros. Muito provavelmente, você não é responsável por todo o projeto -
administradores de banco de dados tendem a se concentrar em bancos de dados e não, por exemplo, na camada de rede. Ainda assim, você deve ter em mente as outras partes e trabalhar com as equipes que são responsáveis por elas, para garantir que não apenas a parte pela qual você é responsável seja projetada corretamente, mas também que os bits restantes da infraestrutura foram projetados usando o mesmos princípios. Além disso, esse conhecimento de como toda
infraestrutura é projetada também ajuda a projetar a pilha de banco de dados. Saber quais problemas podem ocorrer ajuda a construir alguns mecanismos para evitar que eles afetem a disponibilidade do banco de dados.