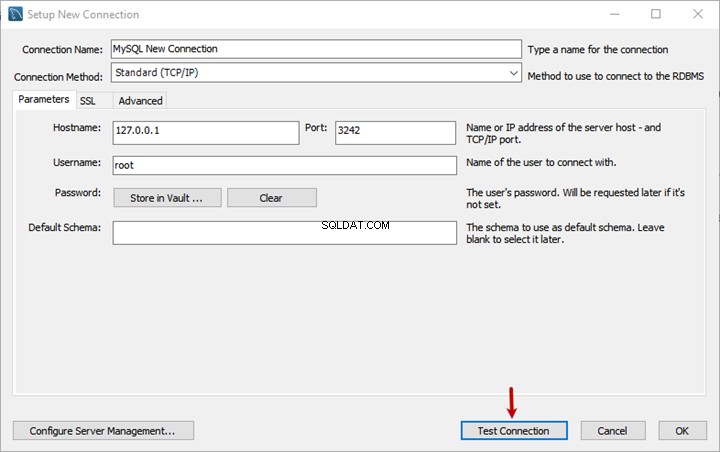
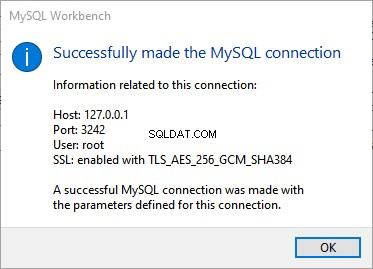
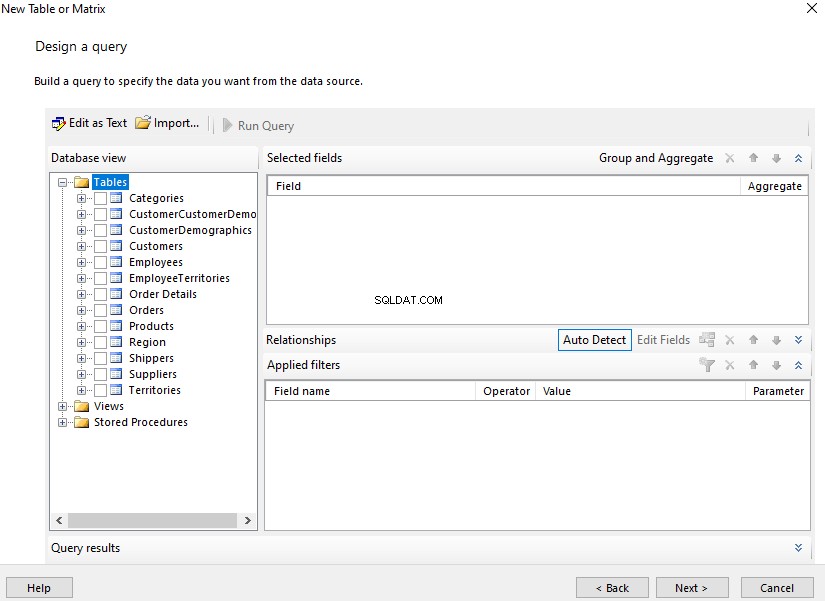
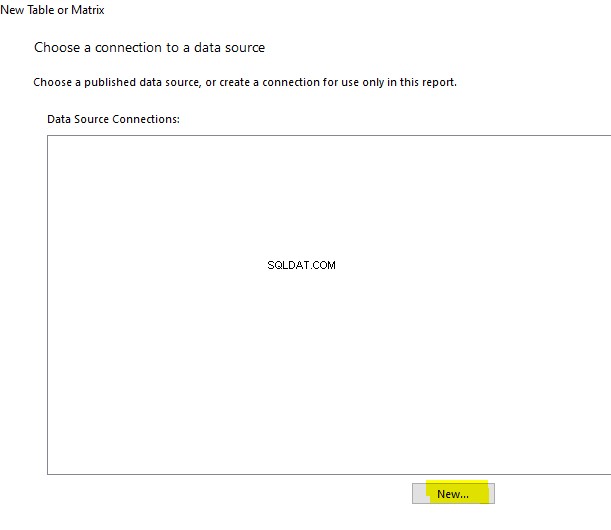
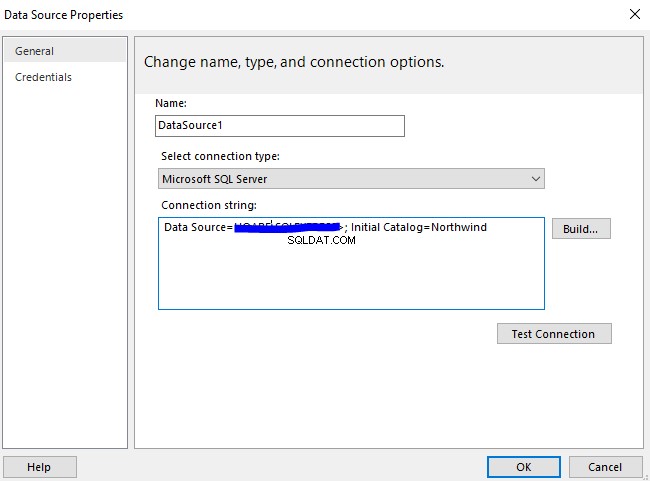
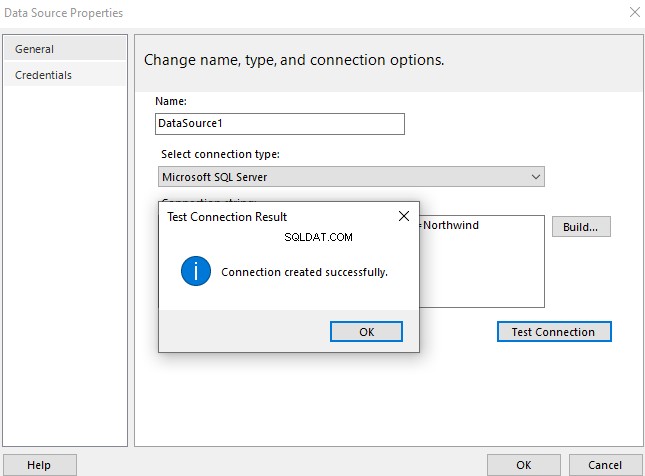
Esta é a segunda parte do material dedicado à Pesquisa Semântica do SQL Server . No artigo anterior, exploramos o básico. Agora, vamos nos concentrar na comparação de documentos armazenados no Windows File System e na análise comparativa com a Pesquisa Semântica no SQL Server.
Realizando Análise Comparativa de Documentos Baseados em Nomes
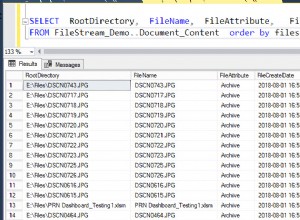
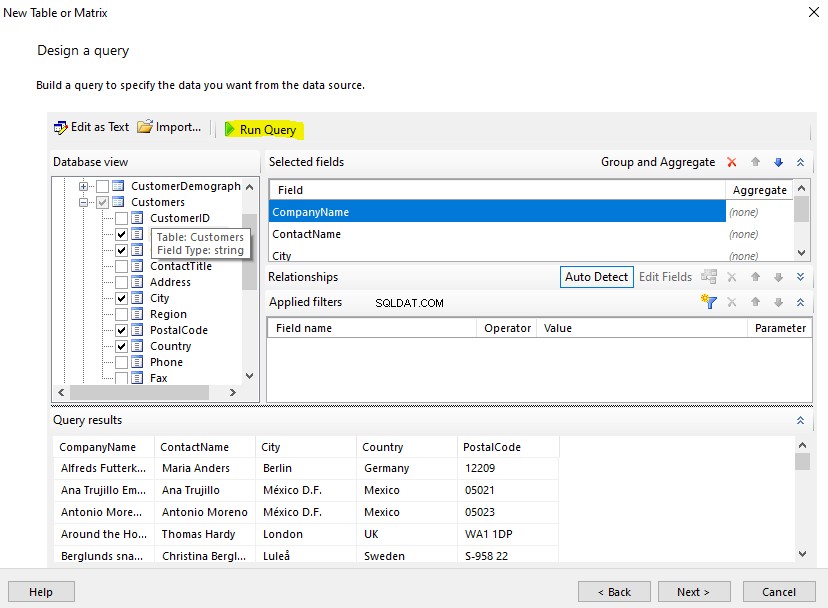
Faremos uma análise comparativa de documentos com base em sua nomenclatura padrão. Neste ponto, vamos fazer uma verificação rápida consultando o EmployeesFilestreamSample banco de dados que configuramos anteriormente:
-- View stored documents managed by File Table to check
SELECT stream_id
,[name]
,file_type
,creation_time
FROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore
Os resultados devem nos mostrar documentos armazenados:
Lista de verificação da pesquisa semântica
Já temos o banco de dados e dois exemplos de documentos do MS Word no Sistema de Arquivos usando a Tabela de Arquivos (você pode consultar a Parte 1 para atualizar o conhecimento, se necessário). No entanto, isso não qualificar automaticamente nossos documentos para o cenário de Busca Semântica.
A Pesquisa Semântica pode ser habilitada de uma das seguintes maneiras:
- Se você já configurou a Pesquisa de texto completo , você pode ativar a pesquisa semântica em uma única etapa.
- Você pode configurar a pesquisa semântica diretamente, mas antes de configurar a pesquisa de texto completo também.
Teste de pesquisa de texto completo antes da configuração da pesquisa semântica
Se uma consulta de texto completo funcionar, precisamos apenas habilitar a pesquisa semântica. Para verificar isso, execute uma consulta de texto completo na tabela desejada:
-- Searching word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
A saída:
Assim, precisamos primeiro atender aos requisitos de pesquisa de texto completo e, em seguida, habilitar a pesquisa semântica.
Ativando a pesquisa semântica para uso
Pelo menos dois dos seguintes pontos são necessários para usar a pesquisa semântica:
- Índice exclusivo
- Um catálogo de texto completo
- Um índice de texto completo
Execute o seguinte script T-SQL para criar um índice exclusivo:
-- Create unique index required for Semantic Search
CREATE UNIQUE INDEX UQ_Stream_Id
ON EmployeesDocumentStore(stream_id)
GO
Crie um catálogo de texto completo com base no índice exclusivo recém-criado. E então, crie um índice Full-Text conforme mostrado abaixo:
-- Getting Semantic Search ready to be used with File Table
CREATE FULLTEXT CATALOG EmployeesFileTableCatalog WITH ACCENT_SENSITIVITY = ON;
CREATE FULLTEXT INDEX ON EmployeesDocumentStore
(
name LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_type LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_stream TYPE COLUMN file_type LANGUAGE 1033 STATISTICAL_SEMANTICS
)
KEY INDEX UQ_Stream_Id
ON EmployeesFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM;
Os resultados:
Teste de pesquisa de texto completo após configuração de pesquisa semântica
Vamos executar a mesma consulta de texto completo para pesquisar a palavra Funcionário nos documentos armazenados:
-- Searching (after Semantic Search setup) word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
A saída:
Não há problema em que as consultas de Texto Completo funcionem na Tabela de Arquivos enquanto a preparamos para a Pesquisa Semântica.
Adicionar mais documentos do MS Word
Vamos para a EmployeesDocumentStore File Table e clique em Explorar o diretório FileTable :
Crie e armazene um novo documento chamado Sadaf Contract Employee :
Em seguida, adicione o seguinte texto ao documento recém-criado. A primeira linha deve ser o título do documento!
Funcionário contratado da Sadaf (título)
Sadaf é um analista de negócios muito eficiente que trabalha com base em contato. Ela é totalmente capaz de lidar com os requisitos de negócios e transformá-los em especificações técnicas para os desenvolvedores trabalharem. Ela é uma analista de negócios muito experiente.
Adicione outro documento chamado Mike Permanent Employee :
Atualize o documento com o seguinte texto:
Mike Funcionário Permanente (Título do documento)
Mike é um programador novo cuja experiência inclui desenvolvimento web. Ele é um aprendiz rápido e feliz em trabalhar em qualquer projeto. Ele tem fortes habilidades de resolução de problemas, mas tem menos conhecimento de negócios. Ele precisa da ajuda de outros desenvolvedores ou analistas de negócios para entender o problema e atender aos requisitos.
Ele é bom quando trabalha em projetos pequenos, mas tem dificuldades se recebe um projeto grande ou complexo.
Temos quatro documentos armazenados no Windows File System gerenciados pelo File Table. Esses documentos devem ser consumidos pela Pesquisa Semântica (incluindo Pesquisa de Texto Completo).
Importante:Embora tenhamos armazenado apenas quatro documentos do MS Word na pasta como exemplo, você pode imaginar a importância de usar a Pesquisa Semântica quando centenas desses documentos são mantidos por um banco de dados SQL Server e você precisa consultar esses documentos para encontrar informações valiosas.
A nomenclatura padrão de documentos é muito importante para a implementação bem-sucedida dessa abordagem.
Contagem Simples de Documentos
Podemos comparar esses documentos e definir as diferenças e semelhanças com base em sua nomenclatura padrão usando a pesquisa semântica. Por exemplo, uma simples consulta pode nos dizer o número total de documentos armazenados na pasta Windows:
-- Getting total number of stored documents
SELECT COUNT(*) AS Total_Documents FROM EmployeesDocumentStore

Comparação de funcionários permanentes versus contratados
Desta vez, estamos usando a Pesquisa semântica para comparar o número de funcionários permanentes e contratados em nossa organização:
-- Creating a summary table variable
DECLARE @Documents TABLE
(DocumentType VARCHAR(100),
DocumentsCount INT)
INSERT INTO @Documents -- Storing total number of stored documents into summary table
SELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStore
INSERT INTO @Documents -- Storing total number of permanent employees documents stored into summary table
SELECT 'Total Permanent Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Permanent'
INSERT INTO @Documents --Storing total number of permanent employees documents stored
SELECT 'Total Contract Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Contract'
SELECT DocumentType,DocumentsCount FROM @Documents
A saída:
Vamos executar uma consulta de pesquisa semântica simples (com base no nome do documento) para visualizar a frase-chave e sua pontuação relativa para cada documento:
-- Getting keyphrase and relative score for all the documents
SELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
ORDER BY score
A saída:
Vamos adicionar mais detalhes aos nomes dos documentos. Vamos renomeá-los da seguinte forma:
- Asif Funcionário Permanente - Gerente de Projetos Experiente
- Mike Funcionário Permanente – Novo Programador
- Peter Funcionário Permanente - Novo Gerente de Projeto
- Funcionário contratado da Sadaf – Analista de negócios experiente
Encontrando novos funcionários (documentos)
Encontre os documentos relacionados aos novos funcionários com base em seus títulos (nomeação padrão):
-- Getting document name-based scoring to find fresh employees for a new project
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName
,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) where keyphrase='fresh'
order by DocumentName desc
Os resultados:
Encontrando funcionários experientes (documentos)
Suponha que queremos revisar rapidamente todos os detalhes de funcionários experientes para o projeto complexo que temos pela frente. Use a seguinte consulta de pesquisa semântica:
-- Getting document name-based scoring to find all experienced employees
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='experienced' order by DocumentName
A saída:
Encontrando todos os gerentes de projeto (documentos)
Por fim, se quisermos percorrer rapidamente os documentos de todos os gerentes de projeto, precisamos da seguinte consulta de pesquisa semântica:
-- Getting document name-based scoring to find all project managers
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='Project'
Os resultados:
Depois de implementar o passo a passo, você pode armazenar com êxito dados não estruturados, como documentos do MS Word, em uma pasta do Windows usando a tabela de arquivos.
Revisão de análise baseada em nome
Até agora, aprendemos como realizar uma análise baseada em nome de documentos armazenados em uma tabela de arquivos usando a pesquisa semântica. No entanto, precisamos que as seguintes condições sejam cumpridas:
- A nomenclatura padrão deve estar em vigor.
- Os nomes devem fornecer as informações necessárias para análise.
Essas condições também são limitações da análise baseada em nomes. Mas isso não significa que não podemos fazer muito com isso.
Nosso foco permanece na abordagem de pesquisa semântica baseada em nome/coluna.
Visualizar as colunas de nome dos documentos
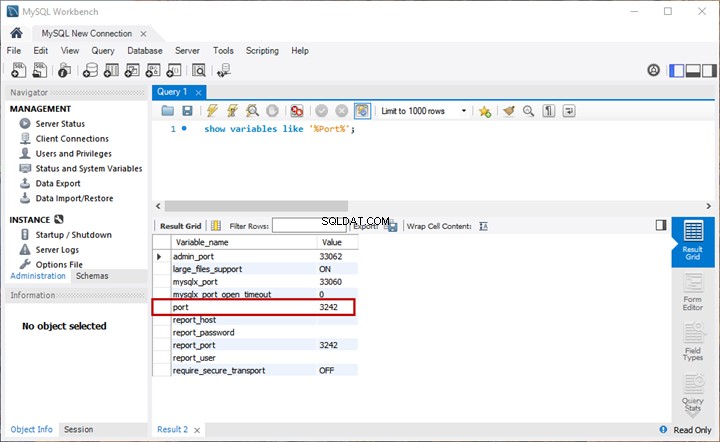
Vamos ver algumas das colunas principais da tabela Documentos, incluindo o Nome coluna:
USE EmployeesFilestreamSample
-- View name column with the file types of the stored documents in File Table for analysis
SELECT name,file_type
FROM dbo.EmployeesDocumentStore
A saída:
Compreendendo a função SEMANTICKEYPHRASETABLE
O SQL Server oferece a SEMANTICKEYPHRASETABLE função para analisar o documento com Pesquisa Semântica. A sintaxe é a seguinte:
SEMANTICKEYPHRASETABLE
(
table,
{ column | (column_list) | * }
[ , source_key ]
)
Esta função nos fornece frases-chave associadas ao documento. Podemos usá-los para analisar documentos com base em seus nomes ou conteúdo. No nosso caso, precisamos não apenas usar essa função, mas também entender como utilizá-la corretamente.
A função requer os seguintes dados:
- Nome da tabela de arquivos a ser usada para análise de pesquisa semântica.
- Nome da coluna a ser usada para análise de pesquisa semântica.
Em seguida, ele retorna os seguintes dados:
- Coluna_id – o número da coluna
- Document_Key – a chave primária padrão para o documento Tabela de Arquivos
- Frase-chave – é uma frase que a Busca Semântica decide indexar para análise. Aplica-se ao nome e ao conteúdo do documento, dependendo de qual coluna queremos ver as frases-chave para
- Pontuação – determina a força de uma frase-chave associada a um documento, por exemplo, como um documento é melhor reconhecido por sua frase-chave. A pontuação pode estar entre 0,0 e 1,0.
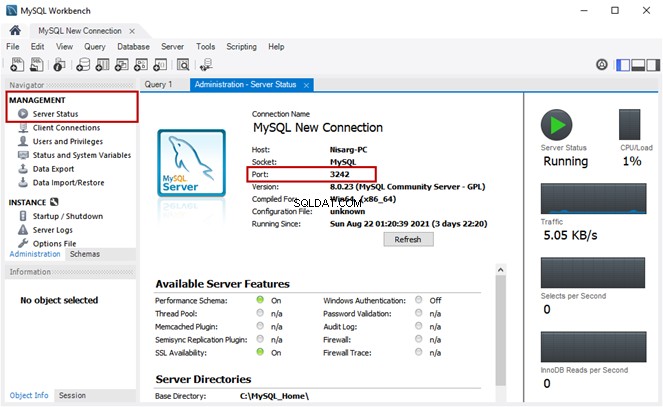
Analisando todos os documentos usando a função SEMANTICKEYPHRASETABLE
Usamos a SEMANTICKEYPHRASETABLE função para a análise baseada no nome dos documentos armazenados na pasta do Windows gerenciada pela Tabela de Arquivos.
Execute o seguinte script T-SQL:
USE EmployeesFilestreamSample
-- View key phrases and their score for the name column
SELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)
order by score desc
A saída:
Temos uma lista de todas as frases-chave anexadas a todos os documentos e suas pontuações. O column_id 3 na linha superior está o nome coluna. Além disso, também chamamos a função fornecendo esta coluna (nome):
Você pode encontrar a document_key : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 executando o script a seguir (embora esteja claro que este documento é aquele em que o nome contém a frase-chave sadaf ):
USE EmployeesFilestreamSample
-- Finding document name by its key (path_locator)
SELECT name,path_locator FROM dbo.EmployeesDocumentStore
WHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260
A saída:
A frase-chave sadaf recebeu a melhor pontuação :1.0 .
Assim, no caso da nomenclatura padrão de documentos com informações suficientes para a análise da Busca Semântica, nossa frase-chave sadaf é a melhor correspondência para esse nome de documento específico.
Analisando um documento específico usando a função SEMANTICKEYPHRASETABLE
Podemos restringir nossa análise de pesquisa semântica com base no nome coluna. Por exemplo, só precisamos ver a coluna nome- frases-chave baseadas em um determinado documento. Podemos especificar a chave do documento na SEMANTICKEYPHRASETABLE Função.
Primeiro, identificamos a chave do documento em que queremos ver todas as frases-chave. Execute o seguinte script T-SQL:
-- Find document_key of the document where the name contains Peter
SELECT name,path_locator as document_key From EmployeesDocumentStore
WHERE name like '%Peter%'
A chave do documento é 0xFF6A92952500812FF013376870181CFA6D7C070220
Agora, vamos ver este documento sobre todas as frases-chave que podem definir o nome do documento:
-- View all the key phrases and their score for a document related to Peter permanent employee
SELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)
INNER JOIN dbo.EmployeesDocumentStore on path_locator=document_key
order by score desc
Os resultados:
A frase-chave empregado obtém a pontuação mais alta neste documento. Podemos ver que todas as palavras da coluna são frases-chave que determinam o significado do documento.
Compreendendo a função SEMANTICSSIMILARITYTABLE
Esta função nos ajuda a comparar um documento com todos os outros documentos com base em frases-chave. A sintaxe desta função é a seguinte:
SEMANTICSIMILARITYTABLE
(
table,
{ column | (column_list) | * },
source_key
)
Requer o nome da tabela, a coluna e a chave do documento para corresponder a outros documentos. Por exemplo, podemos afirmar que dois documentos são semelhantes se tiverem uma boa pontuação de correspondência de frase-chave.
Comparando documentos usando a função SEMANTICSSIMILARITYTABLE
Vamos comparar um documento com outros documentos usando a SEMANTICSIMILARITYTABLE Função.
Comparando todos os documentos dos gerentes de projeto
Precisamos ver todos os documentos relacionados aos gerentes de projeto. A partir dos exemplos acima, sabemos que a chave do documento para o documento especificado é 0xFF6A92952500812FF013376870181CFA6D7C070220 . Portanto, podemos usar essa chave para encontrar outras correspondências, incluindo gerentes de projeto:
USE EmployeesFilestreamSample
-- View all the documents closely related to Peter project manager
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
A saída:
O documento mais relacionado é Asif Permanent Employee – Experienced Project Manager.docx
Comparando documentos de analistas de negócios experientes
Agora, vamos comparar os documentos relacionados ao analista de negócios experiente s e encontre a correspondência mais próxima usando a Pesquisa semântica. Estamos limitados à análise baseada no nome do documento:
USE EmployeesFilestreamSample
-- Finding document_key for experienced business analyst
select name,path_locator as document_key from EmployeesDocumentStore
where name like '%experienced business analyst%'
-- View all the documents closely related to experienced business analyst
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
A saída:
Como podemos ver pelos resultados acima, a correspondência mais próxima para o documento está relacionada ao analista de negócios experiente é o documento do gerente de projeto experiente porque ambos são experientes . No entanto, a pontuação de 0,3 indica que não há muito em comum entre esses dois documentos.
Conclusão
Parabéns! Aprendemos com sucesso como armazenar documentos em pastas do Windows e analisá-los utilizando a Pesquisa Semântica. Também exploramos as funções para usar na prática. Agora você pode aplicar o novo conhecimento e tentar os seguintes exercícios para
Fique atento para mais materiais!