Em meus artigos anteriores, expliquei como criar e configurar o recurso FILESTREAM na instância do SQL Server. Além disso, demonstrei como criar uma tabela que possui uma coluna FILESTREAM e hot para inserir e deletar os dados dela.
Neste artigo, explicarei como fazer backup e restaurar o banco de dados habilitado para FILESTREAM. Além disso, vou demonstrar como restaurar o grupo de arquivos FILESTREAM sem deixar o banco de dados offline.
Como expliquei em meus artigos anteriores, quando habilitamos o FILESTREAM na instância do SQL Server, precisamos criar um contêiner FILESTREAM que tenha o grupo de arquivos FILESTREAM. Quando fazemos backup do banco de dados habilitado para FILESTREAM, o backup do grupo de arquivos FILESTREAM será incluído no conjunto de backup. Quando restaurarmos o banco de dados, o SQL Server restaurará o banco de dados e o contêiner FILESTREAM e os arquivos dentro dele.
Quando fazemos backup de um banco de dados habilitado para FILESTREAM, ele:
- Faça backup de todos os arquivos de dados disponíveis do banco de dados.
- Faça backup do grupo de arquivos FILESTREAM e dos arquivos dentro dele.
- Faça backup do T-Log.
O SQL Server oferece a flexibilidade de fazer backup apenas do contêiner FILESTREAM. Se os arquivos dentro do contêiner FILESTREAM forem corrompidos, não precisamos recuperar todo o banco de dados. Podemos restaurar apenas o grupo de arquivos FILESTREAM.
Nesta demonstração, vou:
- Explicar como fazer um backup completo do banco de dados FS e fazer backup apenas do contêiner FILESTREAM.
- Explicar como restaurar o banco de dados habilitado para FILESTREAM.
- Como restaurar o contêiner FILESTREAM online e offline. Observação:a edição do SQL Server Enterprise e a edição do desenvolvedor oferecem suporte à restauração ONLINE.
Configuração de demonstração:
Nesta demonstração, vou usar:
- Banco de dados :SQL Server 2017
- Software :estúdio de gerenciamento do SQL Server.
Fazendo backup do banco de dados habilitado para FILESTREAM
Para demonstrar o processo de backup, criei um banco de dados habilitado para FILESTREAM chamado FileStream_Demo . Ele tem uma tabela FILESTREAM chamada Document_Content .
Backup completo do banco de dados
Fazer backup de um banco de dados habilitado para FILESTREAM é um processo direto. Para gerar um backup completo dele, execute o seguinte script T-SQL.
BACKUP DATABASE [FileStream_Demo] TO DISK = N'E:\Backups\FileStream_Demo.bak' WITH NOFORMAT, NOINIT, NAME = N'FileStream_Demo-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO
A seguir está o log de backup gerado pela execução do comando de backup acima:
/*Begin Backup DataFile*/ Processed 568 pages for database 'FileStream_Demo', file 'FileStream_Demo' on file 1. /*Begin backup of FILESTREAM container*/ 10 percent processed. 20 percent processed. 30 percent processed. 40 percent processed. 50 percent processed. 60 percent processed. 70 percent processed. 80 percent processed. 90 percent processed. Processed 111106 pages for database 'FileStream_Demo', file 'Dummy-Documents' on file 1. /*Begin backup of FILESTREAM container*/ Processed 4 pages for database 'FileStream_Demo', file 'FileStream_Demo_log' on file 1. 100 percent processed. BACKUP DATABASE successfully processed 111677 pages in 18.410 seconds (47.391 MB/sec).
Como mencionei no início do artigo, primeiro, o SQL Server faz backup do arquivo de dados primário, depois dos arquivos de dados secundários e, por último, dos logs de transações. Como você pode ver no log de backup, em primeiro lugar, o arquivo de dados primário de backup do servidor SQL, em seguida, o grupo de arquivos FILESTREAM e os dados associados a ele e, finalmente, os logs de transações.
Backup do contêiner FILESTREAM
Como mencionei no início do artigo, também podemos gerar um backup do container FILESTREAM. Para criar um backup do contêiner FILESTREAM, execute o seguinte script T-SQL.
BACKUP DATABASE [FileStream_Demo] FILEGROUP = N'Dummy-Documents' TO DISK = N'E:\Backups\FS_Container.bak' WITH NOFORMAT, NOINIT, NAME = N'FileStream_Demo-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO
Restaurar banco de dados habilitado para FILESTREAM
Quando restauramos o banco de dados FILESTREAM, o SQL restaura o contêiner FileStream junto com todos os arquivos dentro do contêiner FILESTREAM.
Para restaurar o banco de dados, execute as seguintes tarefas:
- No SSMS, clique com o botão direito do mouse no banco de dados e selecione Restaurar banco de dados .
- Na caixa de diálogo Restaurar, selecione Dispositivo e clique em Procurar . Outra caixa de diálogo será aberta. Na caixa de diálogo, clique em Adicionar .
- No Localizar arquivo de backup caixa de diálogo, navegue pela estrutura de diretórios, clique em um backup adequado e clique em OK .
- Depois que as informações de backup forem carregadas nos Conjuntos de backup a serem restaurados visualização em grade, clique em OK para iniciar a restauração do processo.
Como alternativa, você pode restaurar um banco de dados executando o seguinte comando:
USE [master] RESTORE DATABASE [FileStream_Demo] FROM DISK = N'E:\Backups\FileStream_Demo.bak' WITH FILE = 1, NOUNLOAD, STATS = 5 GO
Cenário de recuperação de banco de dados habilitado para FILESTREAM
O grupo de arquivos FILESTREAM restaura o processo como o processo de restauração de grupos de arquivos.
Para gerar o cenário de restauração, crie um banco de dados habilitado para FILESTREAM chamado FileStream-Demo . O banco de dados tem uma tabela FILESTREAM chamada Document_Content . Insira alguns dados e arquivos aleatórios no Document_Content tabela.
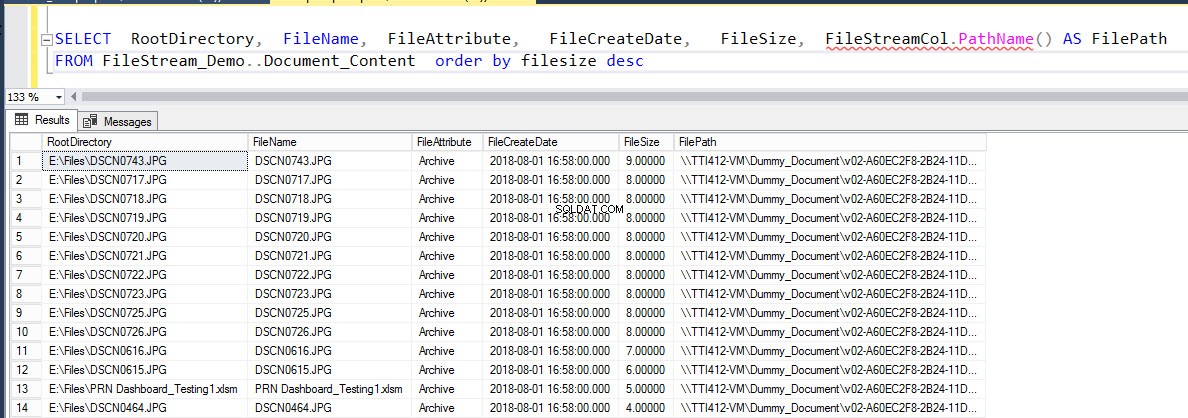
Execute a seguinte consulta para preencher os detalhes dos arquivos inseridos na tabela.
SELECT RootDirectory, FileName, FileAttribute, FileCreateDate, FileSize, FileStreamCol.PathName() AS FilePath FROM Document_Content order by filesize desc
A saída é a seguinte:
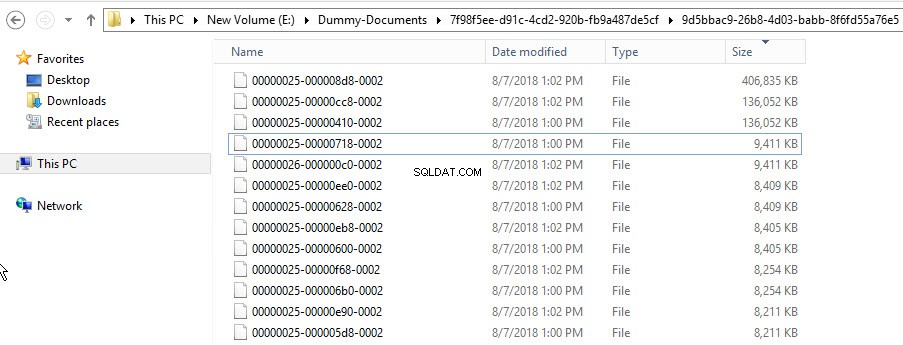
Veja a seguir uma captura de tela do contêiner FILESTREAM:
Primeiramente, gere um backup completo do banco de dados. Para isso, execute o seguinte comando.
BACKUP DATABASE [FileStream_Demo] TO DISK = N'E:\Backups\Full_FileStream_Demo_20180810.bak' WITH NOFORMAT, NOINIT,NAME = N'FileStream_Demo-Full Database Backup'
Em segundo lugar, gere um backup FILEGROUP do grupo de arquivos FILESTREAM chamado Dummy-Document executando o seguinte comando:
BACKUP DATABASE [FileStream_Demo] FILEGROUP = N'Dummy-Documents' TO DISK = N'E:\Backups\FileStream_Filegroup_Demo.bak' WITH NOFORMAT, NOINIT, NAME = N'FileStream_Demo-Full FILEGROUP Backup'
Para gerar a corrupção de FILESTREAM, exclua alguns arquivos do contêiner FILESTREAM. Depois que esses arquivos forem excluídos, tente recuperar dados de “Document_Content” executando o seguinte comando:
Use FileStream_Demo Go select * from Document_Content
Você receberá o seguinte erro:
Msg 233, Level 20, State 0, Line 122 A transport-level error has occurred when receiving results from the server. (provider: Shared Memory Provider, error: 0 - No process is on the other end of the pipe.)
Veja a captura de tela a seguir:
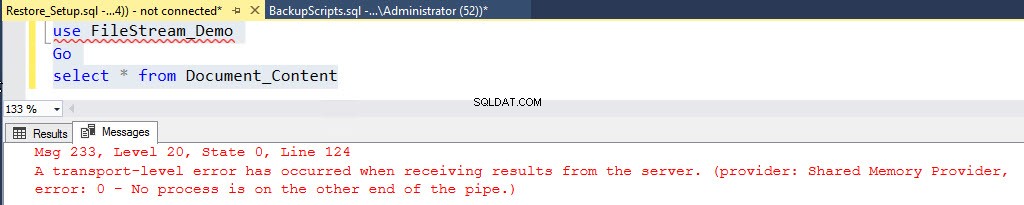
Agora, precisamos restaurar o contêiner FILESTREAM para corrigir esse erro. Geramos um backup completo e um backup do documento fictício grupo de arquivos.
Podemos restaurar todo o contêiner FILESTREAM restaurando o grupo de arquivos FILESTREAM. vou mostrar:
- Restauração offline do grupo de arquivos FILESTREAM.
- Restauração online do grupo de arquivos FILESTREAM.
Restauração offline do grupo de arquivos do contêiner FILESTREAM
Como eu havia deletado arquivos do container FILESTREAM, não precisamos restaurar todo o banco de dados. Portanto, em vez de restaurar todo o banco de dados, restauraremos o único grupo de arquivos. Para fazer isso, primeiro, gere um backup do Tail-Log para capturar as alterações de dados que não foram copiadas. O backup do Tail-log deve ser feito usando a opção NORECOVERY para trazer o banco de dados no estado de restauração, e isso permite aplicar backups no banco de dados. Para isso, execute a seguinte consulta:
backup log [FileStream_Demo] to disk ='E:\Backups\FileStream_Filegroup_Demo_Log_1.trn' With NORECOVERY
Depois que o backup do Tail-log for gerado, o banco de dados estará no modo de restauração. Agora, podemos aplicar o backup FILEGROUP em um banco de dados com a opção NORECOVERY. Para isso, execute o seguinte comando:
use master go RESTORE DATABASE [FileStream_Demo] FILE='Dummy-Documents' FROM DISK = N'E:\Backups\FileStream_Filegroup_Demo.bak' WITH NORECOVERY,REPLACE;
Agora aplique o backup do Tail-log com a opção RECOVERY. Para isso, execute o seguinte comando:
RESTORE LOG [FileStream_Demo] FROM DISK = N'E:\Backups\FileStream_Filegroup_Demo_Log_1.trn'
Depois que o backup for restaurado, o banco de dados ficará online e todos os arquivos serão restaurados no contêiner FILESTREAM. Para verificar, execute o seguinte comando:
SELECT RootDirectory, FileName, FileAttribute, FileCreateDate, FileSize, FileStreamCol.PathName() AS FilePath FROM Document_Content order by filesize desc
A saída da consulta acima é a seguinte:
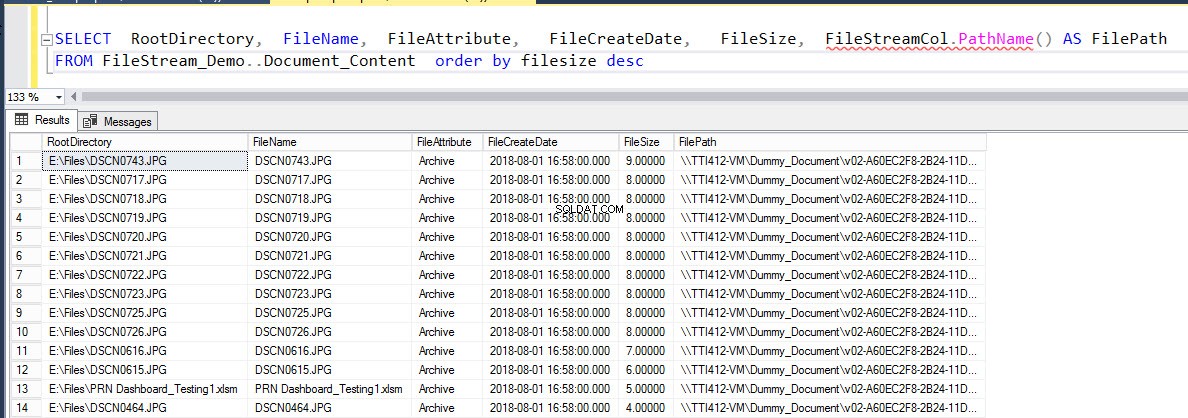
Restauração online do grupo de arquivos FILESTREAM
Usando o SQL Server Enterprise Edition, podemos restaurar o backup quando o banco de dados estiver online. Por exemplo, se um arquivo F1 do grupo de arquivos secundário FG-1 estiver corrompido, podemos restaurar o arquivo F1 enquanto o banco de dados permanece online. A sequência de restauração da restauração offline e a restauração online são as mesmas.
Como mencionado acima, para executar uma restauração online do grupo de arquivos FILESTREAM, faça o Dummy-Document arquivo de dados offline. Para isso, execute o seguinte comando.
use master go Alter database [FileStream_Demo] MODIFY FILE (NAME='Dummy-Documents',OFFLINE)
Para verificar o status do arquivo, execute a seguinte consulta:
Use [FileStream_Demo] Go select File_id, type_desc,name, physical_name,state_desc,size from FileStream_Demo.sys.database_files
A saída é a seguinte:
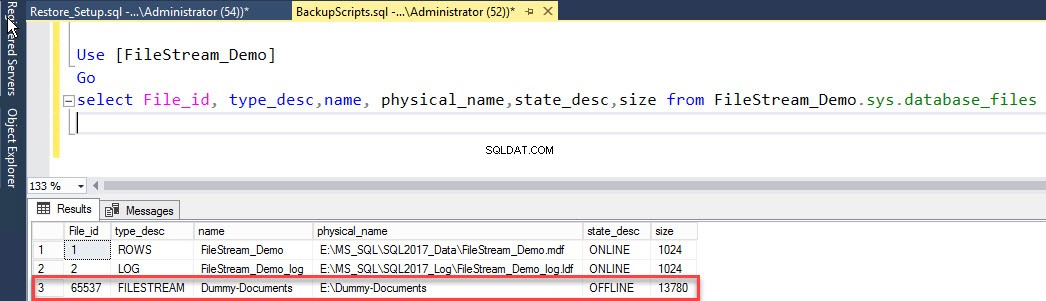
Já fizemos backup do documento fictício grupo de arquivos. Assim, uma vez que o arquivo de dados esteja offline, restaure o backup FILEGROUP em um banco de dados com a opção NORECOVERY. Para isso, execute o seguinte comando:
use master go RESTORE DATABASE [FileStream_Demo] FILE='Dummy-Documents' FROM DISK = N'E:\Backups\FileStream_Filegroup_Demo.bak' WITH NORECOVERY, REPLACE;
Agora, faça um backup de log do banco de dados para garantir que o ponto em que o arquivo de dados ficou offline seja capturado. Para isso, execute o seguinte comando:
backup log [FileStream_Demo] to disk ='E:\Backups\FileStream_Filegroup_Demo_Log1.trn'
Execute o seguinte comando para restaurar o último backup do T-Log.
use master go RESTORE LOG [FileStream_Demo] FROM DISK = N'E:\Backups\FileStream_Filegroup_Demo_Log1.trn'
Depois que o backup de log for restaurado, todos os arquivos no contêiner FILESTREAM serão restaurados e o grupo de arquivos ficará online. Para verificar isso, execute a seguinte consulta:
Use [FileStream_Demo] Go select File_id, type_desc,name, physical_name,state_desc,size from FileStream_Demo.sys.database_files
A saída é a seguinte:
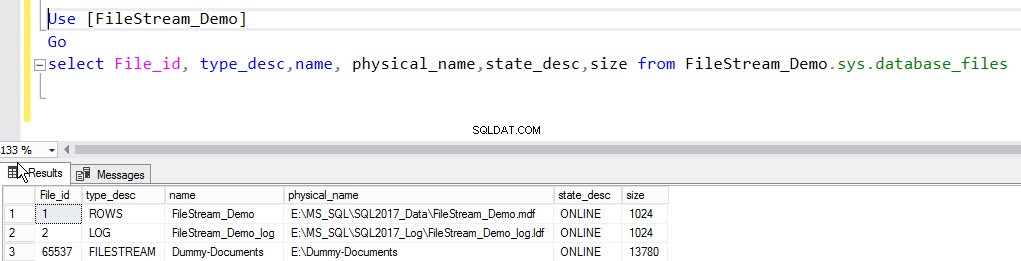
Depois que o backup for restaurado, o banco de dados ficará online e todos os arquivos serão restaurados no contêiner FILESTREAM. Para verificar, execute o seguinte comando:
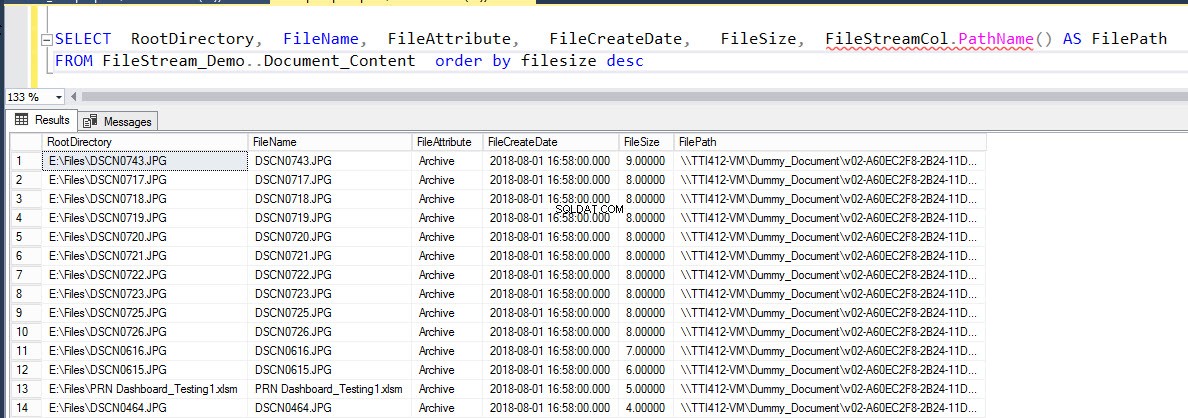
SELECT RootDirectory, FileName, FileAttribute, FileCreateDate, FileSize, FileStreamCol.PathName() AS FilePath FROM Document_Content order by filesize desc
A saída é a seguinte:
Resumo
Neste artigo, expliquei:
- Como fazer backup e restaurar o banco de dados habilitado para FILESTREAM e o grupo de arquivos FILESTREAM.
- Como restaurar o grupo de arquivos FILESTREAM online e offline.