De acordo com a Wikipedia, “Uma inserção em massa é um processo ou método fornecido por um sistema de gerenciamento de banco de dados para carregar várias linhas de dados em uma tabela de banco de dados”. Se ajustarmos esta explicação de acordo com a instrução BULK INSERT, a inserção em massa permite importar arquivos de dados externos para o SQL Server. Suponha que nossa organização tenha um arquivo CSV de 1.500.000 linhas e queremos importar esse arquivo para uma tabela específica no SQL Server, para que possamos usar facilmente a instrução BULK INSERT no SQL Server. Certamente, podemos encontrar várias metodologias de importação para lidar com esse processo de importação de arquivos CSV, por exemplo. podemos usar bcp (b ulk c opi p programa), Assistente de Importação e Exportação do SQL Server ou pacote do SQL Server Integration Service. No entanto, a instrução BULK INSERT é muito mais rápida e robusta do que usar outras metodologias. Outra vantagem da instrução de inserção em massa é que ela oferece vários parâmetros que ajudam a determinar as configurações do processo de inserção em massa.
A princípio, iniciaremos uma amostra bem básica e depois passaremos por vários cenários sofisticados.
Preparação
Antes de iniciar as amostras, precisamos de um arquivo CSV de amostra. Portanto, faremos o download de um arquivo CSV de amostra do site E for Excel, onde você poderá encontrar vários arquivos CSV de amostra com um número de linha diferente. Você pode encontrar o link no final do artigo. Em nossos cenários, usaremos 1.500.000 registros de vendas. Baixe um arquivo zip, descompacte o arquivo CSV e coloque-o em sua unidade local.

Importar arquivo CSV para a tabela do SQL Server
Cenário-1:destino e arquivo CSV têm o mesmo número de colunas
Neste primeiro cenário, importaremos o arquivo CSV para a tabela de destino da forma mais simples. Coloquei meu arquivo CSV de exemplo na unidade C:e agora vamos criar uma tabela na qual importaremos os dados do arquivo CSV.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
A instrução BULK INSERT a seguir importa o arquivo CSV para a tabela Sales.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); 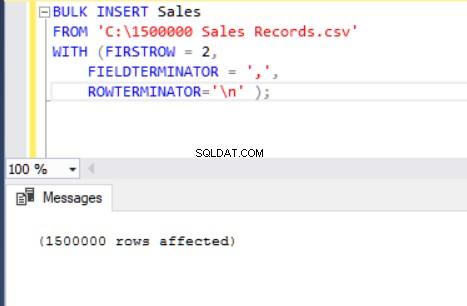
Agora, explicaremos os parâmetros da instrução de inserção em massa acima.
O parâmetro FIRSTROW especifica o ponto inicial da instrução de inserção. No exemplo abaixo, queremos pular os cabeçalhos das colunas, então definimos esse parâmetro como 2.

FIELDTERMINATOR define o caractere que separa os campos uns dos outros. O SQL Server detecta cada campo dessa maneira. ROWTERMINATOR não difere muito de FIELDTERMINATOR. Ele define o caráter de separação das linhas. No arquivo CSV de amostra, fieldterminator é muito claro e é uma vírgula (,). Mas como podemos detectar um fieldterminator? Abra o arquivo CSV no Notepad++ e navegue até View->Show Symbol->Show All Charters e descubra os caracteres CRLF no final de cada campo.
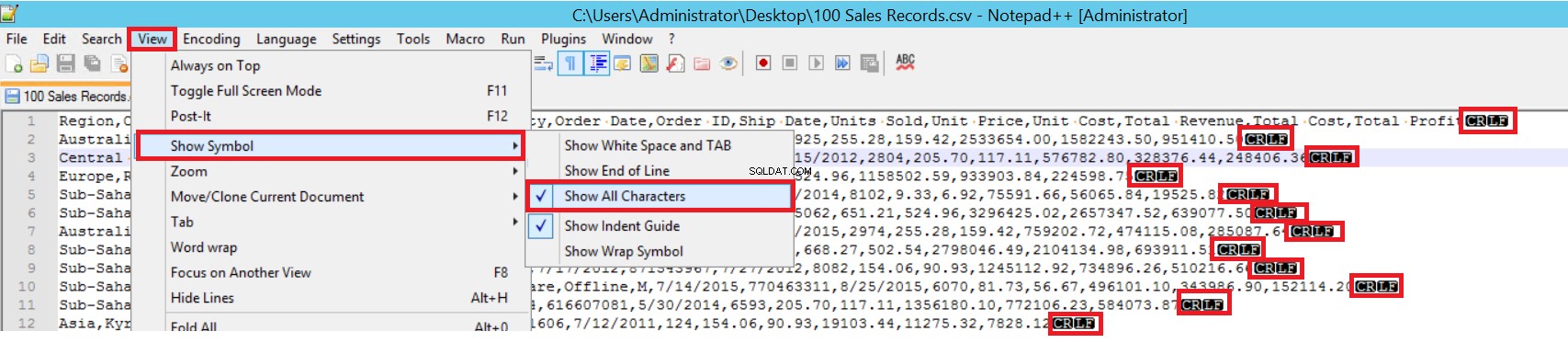
CR =Retorno de carro e LF =Alimentação de linha. Eles são usados para marcar uma quebra de linha em um arquivo de texto e é indicado pelo caractere “\n” na instrução de inserção em massa.
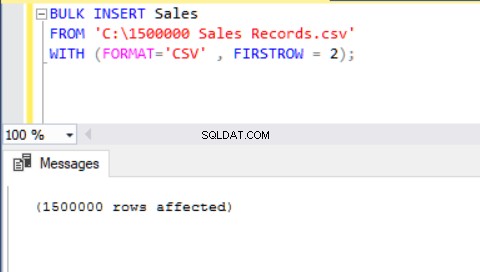
Outro método de importar um arquivo CSV para uma tabela com a ajuda da inserção em massa é usar o parâmetro FORMAT. Observe que o parâmetro FORMAT está disponível apenas no SQL Server 2017 e em versões posteriores.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Agora vamos analisar outro cenário.
Cenário-2:a tabela de destino tem mais colunas do que o arquivo CSV
Nesse cenário, adicionaremos uma chave primária à tabela Sales e, nesse caso, quebra os mapeamentos de coluna de igualdade. Agora, vamos criar a tabela Sales com uma chave primária, tentar importar o arquivo CSV através do comando bulk insert e, em seguida, receberemos um erro.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); 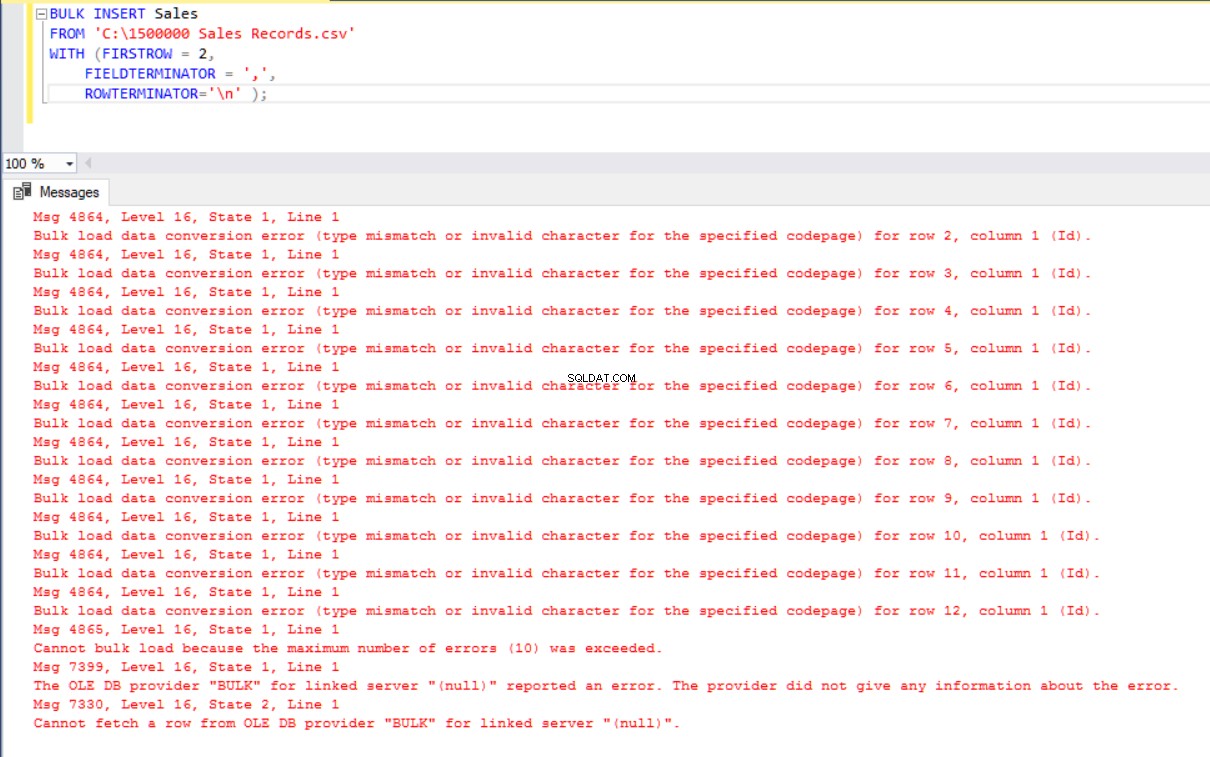
Para solucionar esse erro, criaremos uma visualização da tabela Sales com colunas de mapeamento para o arquivo CSV e importaremos os dados CSV dessa visualização para a tabela Sales.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Cenário-3:como separar e carregar arquivo CSV em um tamanho de lote pequeno?
O SQL Server adquire um bloqueio para a tabela de destino durante a operação de inserção em massa. Por padrão, se você não definir o parâmetro BATCHSIZE, o SQL Server abre uma transação e insere todos os dados CSV nessa transação. No entanto, se você definir o parâmetro BATCHSIZE, o SQL Server dividirá os dados CSV de acordo com esse valor de parâmetro. No exemplo a seguir, dividiremos todos os dados CSV em vários conjuntos de 300.000 linhas cada. Assim os dados serão importados em 5 vezes.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); 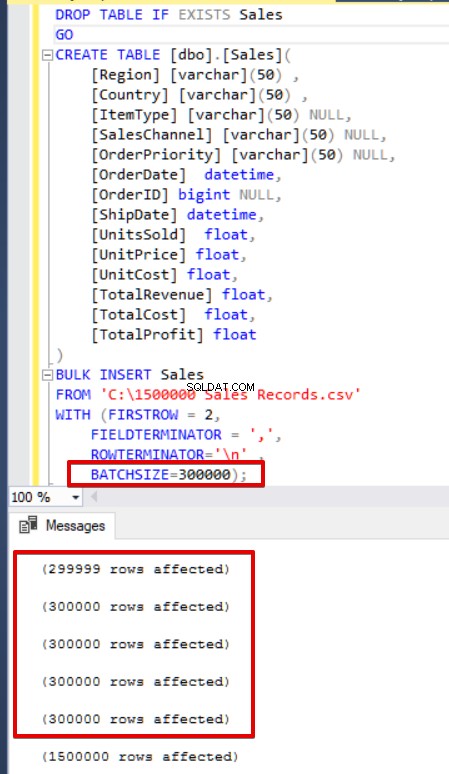
Se a instrução de inserção em massa não incluir o parâmetro de tamanho do lote (BATCHSIZE), ocorrerá um erro e o SQL Server reverterá todo o processo de inserção em massa. Por outro lado, se você definir o parâmetro de tamanho do lote como instrução de inserção em massa, o SQL Server reverterá apenas esta parte dividida em que ocorreu o erro. Não há valor ideal ou melhor para esse parâmetro porque esse valor de parâmetro pode ser alterado de acordo com os requisitos do sistema de banco de dados.
Cenário-4:como cancelar o processo de importação ao receber um erro?
Em alguns cenários de cópia em massa, se ocorrer um erro, podemos cancelar o processo de cópia em massa ou manter o processo em andamento. O parâmetro MAXERRORS permite especificar o número máximo de erros. Se o processo de inserção em massa atingir esse valor máximo de erro, a operação de importação em massa será cancelada e revertida. O valor padrão para este parâmetro é 10.
No exemplo a seguir, corromperemos intencionalmente o tipo de dados em 3 linhas do arquivo CSV e definiremos o parâmetro MAXERRORS como 2. Como resultado, toda a operação de inserção em massa será cancelada porque o número do erro excede o parâmetro de erro máximo.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); 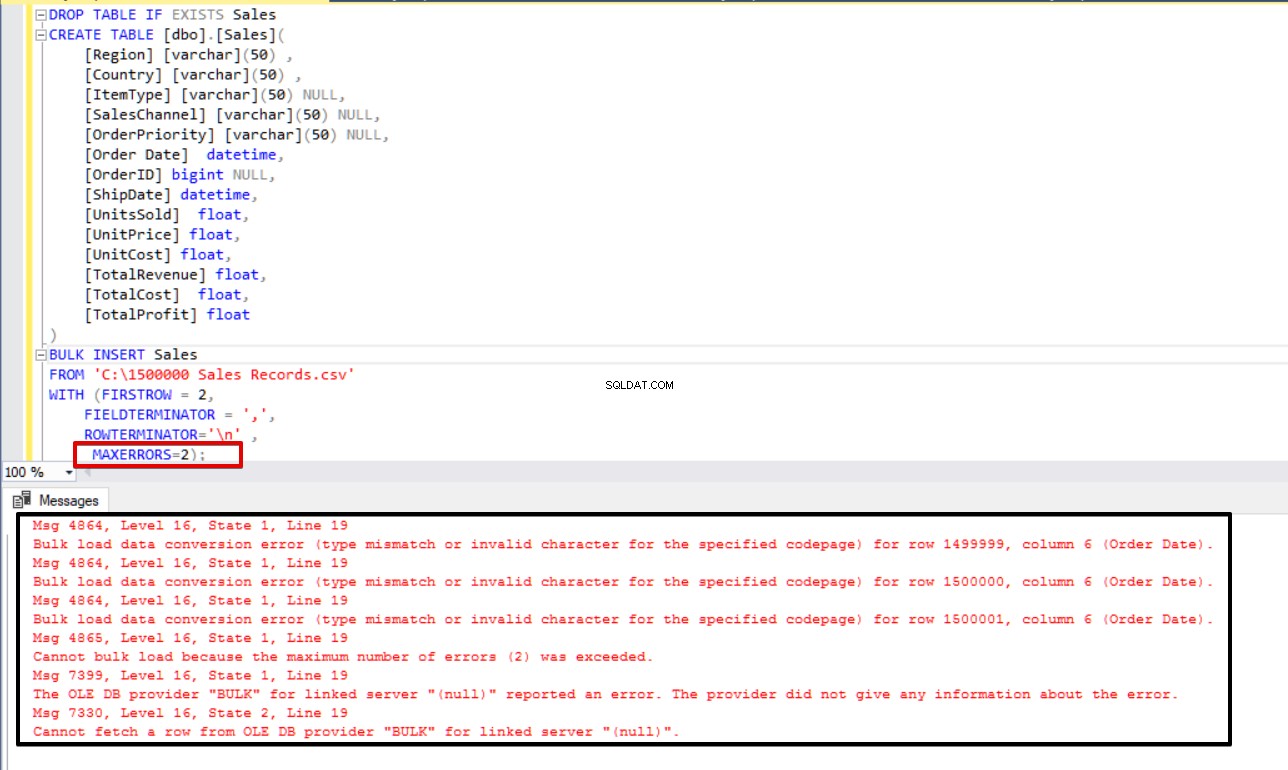
Agora, alteraremos o parâmetro max error para 4. Como resultado, a instrução de inserção em massa ignorará essas linhas e inserirá as linhas estruturadas de dados adequadas e concluirá o processo de inserção em massa.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales 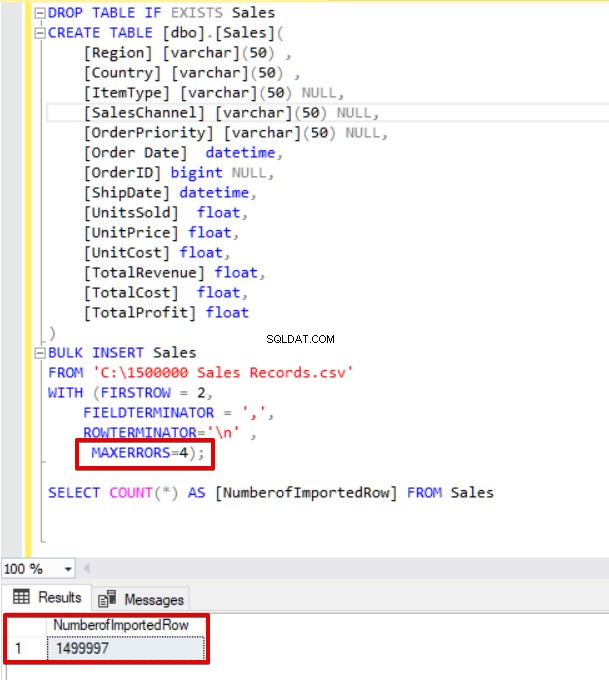
Além disso, se usarmos ambos, o tamanho do lote e os parâmetros de erro máximo ao mesmo tempo, o processo de cópia em massa não cancelará toda a operação de inserção, apenas cancelará a parte dividida.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales 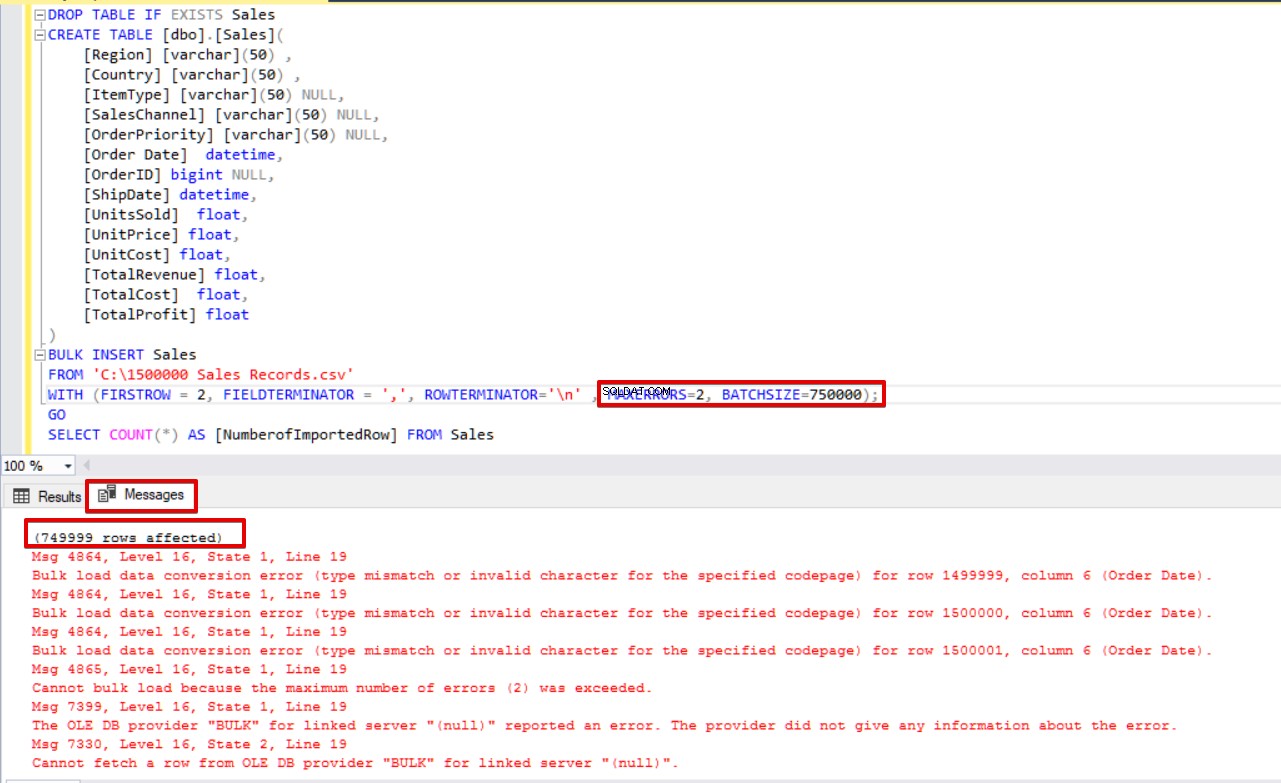
Nesta primeira parte desta série de artigos, discutimos os fundamentos do uso da operação de inserção em massa no SQL Server e analisamos vários cenários que estão próximos dos problemas da vida real.
Inserção em massa do SQL Server – Parte 2
Links úteis:
Inserção em massa
E para Excel - Arquivos CSV de Amostra / Conjuntos de Dados para Teste (até 1,5 milhão de registros)
Baixar Bloco de Notas++
Ferramenta útil:
dbForge Data Pump – um add-in SSMS para preencher bancos de dados SQL com dados de origem externa e migrar dados entre sistemas.