NOTAS:
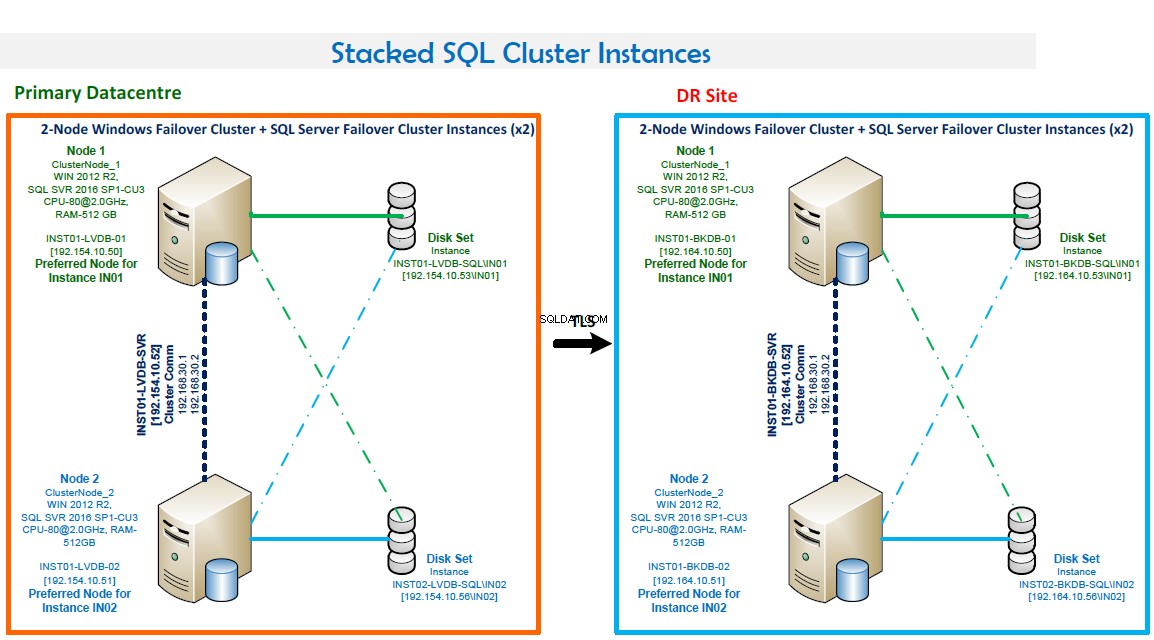
- Agrupamento de failover do Windows composto por dois nós.
- Duas instâncias de cluster de failover do SQL Server. Esta configuração otimiza o hardware. IN01 é preferido no Node1 e IN02 é preferido no Node2.
- Números de porta:IN01 escuta na porta 1435 e IN02 escuta na porta 1436.
- Alta disponibilidade. Ambos os nós fazem backup um do outro. O failover é automático em caso de falha.
- Modo de quórum é maioria de nós e discos.
- Faça backup da LAN no local e backup de rotina configurado usando a Veritas
Introdução
Não é incomum ter desenvolvedores e gerentes de projeto exigindo uma nova instância do SQL Server para cada novo aplicativo ou serviço. Embora tecnologias como virtualização e nuvem tenham facilitado a criação de novas instâncias, algumas técnicas antigas incorporadas ao SQL Server permitem obter tempos de retorno baixos quando há necessidade de fornecer um novo banco de dados para um novo serviço ou aplicativo. Esse estado de coisas pode ser criado por um DBA que pode projetar e implantar um grande cluster do SQL Server capaz de dar suporte à maioria dos bancos de dados do SQL Server exigidos pela organização. Há vantagens adicionais nesse tipo de consolidação, como custos de licença mais baixos, melhor governança e facilidade de administração. No artigo, destacaremos algumas considerações que tivemos a oportunidade de experimentar ao usar o clustering e o empilhamento como meio de consolidação de bancos de dados SQL Server.
Agrupamento
O cluster de failover do Windows Server é uma solução de alta disponibilidade muito conhecida que sobreviveu a muitas versões do Windows Server e na qual a Microsoft pretende continuar investindo e aprimorando. As instâncias do cluster de failover do SQL Server dependem do WSFC. As edições Standard e Enterprise do SQL Server oferecem suporte a instâncias de cluster de failover do SQL Server, mas a Standard Edition é limitada a apenas dois nós. A consolidação de bancos de dados em um único SQL Server FCI oferece benefícios como:
- HA por padrão — Todos os bancos de dados implantados em uma instância clusterizada do SQL Server são altamente disponíveis por padrão! Depois que uma instância em cluster é criada, novas implantações são tratadas com antecedência em termos de alta disponibilidade.
- Facilidade de administração – Menos DBAs podem gastar tempo configurando, monitorando e, quando necessário, solucionando problemas de UMA instância em cluster que dá suporte a muitos aplicativos. Corretamente, documentar a instância também é muito mais fácil ao lidar com um ambiente grande. A configuração de uma solução Enterprise Backup para lidar com todos os bancos de dados em seu ambiente é facilitada pelo fato de você precisar fazer essa configuração apenas um ao usar instâncias consolidadas.
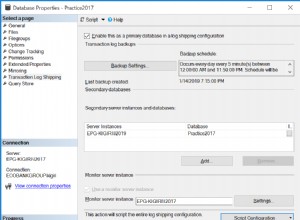
- Conformidade – Requisitos importantes como aplicação de patches e até mesmo proteção podem ser feitos uma vez com tempo de inatividade mínimo em um grande número de bancos de dados em um único esforço administrativo. Em nossa loja, usamos o Transaction Log Shipping entre instâncias em cluster em dois data centers para garantir que os bancos de dados estejam protegidos contra o risco de desastres.
- Padronização – A aplicação de padrões como convenções de nomenclatura, gerenciamento de acesso, autenticação do Windows, auditoria e gerenciamento baseado em políticas é muito mais fácil ao lidar com apenas um ou dois ambientes, dependendo do tamanho da sua loja
Listagem 1: Extrair informações sobre sua instância
-- Extract Instance Details
-- Includes a Column to Check Whether Instance is Clustered
SELECT SERVERPROPERTY('MachineName') AS [MachineName]
, SERVERPROPERTY('ServerName') AS [ServerName]
, SERVERPROPERTY('InstanceName') AS [Instance]
, SERVERPROPERTY('IsClustered') AS [IsClustered]
, SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS]
, SERVERPROPERTY('Edition') AS [Edition]
, SERVERPROPERTY('ProductLevel') AS [ProductLevel]
, SERVERPROPERTY('ProductVersion') AS [ProductVersion]
, SERVERPROPERTY('ProcessID') AS [ProcessID]
, SERVERPROPERTY('Collation') AS [Collation]
, SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled]
, SERVERPROPERTY('IsIntegratedSecurityOnly') AS [IsIntegratedSecurityOnly]
, SERVERPROPERTY('IsHadrEnabled') AS [IsHadrEnabled]
, SERVERPROPERTY('HadrManagerStatus') AS [HadrManagerStatus]
, SERVERPROPERTY('IsXTPSupported') AS [IsXTPSupported];
Empilhamento
O SQL Server oferece suporte a até cinquenta instâncias únicas em um servidor e até 25 instâncias de cluster de failover em um cluster de failover do Windows Server. Diferentes versões do SQL Server podem ser empilhadas no mesmo ambiente para fornecer um ambiente robusto que dará suporte a diferentes aplicativos. Em tal configuração, a atualização de bancos de dados pode assumir a forma de simplesmente promovê-los de uma instância do SQL Server para a próxima versão no mesmo cluster até o hardware envelhecer. Uma consideração importante a ter em mente ao empilhar o SQL Server é que você deve alocar memória para cada instância de forma que a quantidade total de memória alocada não exceda a memória disponível no sistema operacional. O outro ponto nessa direção é garantir que a conta de serviço do SQL Server para cada instância deve ter as páginas de bloqueio nos privilégios de memória. A atribuição de páginas de bloqueio na memória garante que, quando o SQL Server adquirir memória, o sistema operacional não tentará recuperá-la quando outros processos no servidor precisarem de memória. Configurar uma conta de serviço do SQL Server definida, configurar MAX_SERVER_MEMORY e conceder privilégios de Bloquear Páginas na Memória são um trio essencial ao empilhar instâncias do SQL Server.
A Microsoft cobra alguns milhares de dólares por par de núcleos de CPU. O empilhamento de instâncias do SQL Server permite que você aproveite esse modelo de licenciamento fazendo com que as instâncias compartilhem o mesmo conjunto de CPUs (suando o ativo). Já mencionamos que você pode empilhar diferentes versões do SQL Server, cuidando de aplicativos herdados que ainda executam versões anteriores ao SQL Server 2016, por exemplo. Ao usar diferentes edições do SQL Server, convém considerar o uso de afinidade do processador conforme descrito por Glen Berry neste artigo. A afinidade do processador também pode ser usada para controlar como os recursos da CPU são compartilhados entre as instâncias, assim como você controla a memória. O empilhamento também aborda questões de segurança para aplicativos que devem usar a conta SA, por exemplo, ou questões de configuração para aplicativos que exigem uma instância dedicada ou essas opções são um agrupamento específico. A preocupação com o desempenho do TempDB compartilhado é outro motivo pelo qual você pode querer empilhar em vez de agrupar todos os bancos de dados em uma instância clusterizada.
Vale a pena notar que o valor do agrupamento, conforme destacado anteriormente, se estende ainda mais com o empilhamento. Por exemplo, ao corrigir uma instância do SQL Server com várias FCIs, todas as FCIs podem ser corrigidas de uma só vez.
Pontos a serem observados
Ao usar o clustering, certas convenções tornarão a administração e o gerenciamento do ambiente um pouco mais fáceis e melhorarão os ativos. Abordaremos brevemente alguns deles:
- Ferramentas de cliente atuais — Você pode encontrar erros incomuns ao tentar gerenciar uma instância do SQL Server 2016 usando o SQL Server Management Studio 2012. Os erros não informam especificamente que o problema é a versão da ferramenta de cliente. Normalmente, temos uma instância do SQL Server Management Studio 17.3 no cliente que desejamos usar para se conectar às nossas instâncias.
- Convenções de nomenclatura — Uma convenção de nomenclatura facilita a certeza de qual instância você está trabalhando a qualquer momento. Usando aliases, você pode reduzir ainda mais o fardo de lembrar o nome longo da instância em usuários finais que precisam de acesso ao banco de dados.
- Nó preferencial – Definir um nó preferencial para cada função do SQL Server no Gerenciador de cluster de failover é uma boa ideia, uma boa maneira de garantir que o poder de processamento de todos os nós de cluster esteja sendo utilizado. Em nossa loja, depois de configurar os nós preferenciais, configuramos a função para fazer failback entre 0500 HRS e 0600 HRS caso haja um failover inadvertido.
- Transaction Log Shipping – Ao configurar a recuperação de desastres para FCIs, faz sentido identificar todos os caminhos UNC usando nomes virtuais, não os nomes ou o endereço IP dos nós do cluster. Isso garante que as coisas continuem funcionando corretamente se ocorrer um failover. Também é muito importante garantir que as contas do SQL Server Agent em ambos os sites tenham controle total sobre esses caminhos.
Lista 2: Configurar o monitoramento para envio de log de transações usando e-mail
-- Create Table to Store Log Shipping Data
create table msdb dbo log_shipping_report
(status bit,
is_primary bit,
server sysname,
database_name sysname,
time_since_last_backup int,
last_backup_file nvarchar (500),
backup_threshold int,
is_backup_alert_enabled bit,
time_since_last_copy int,
last_copied_file nvarchar 500),
time_since_last_restore int,
last_restored_file nvarchar(500),
last_restored_latency int,
restore_threshold int,
is_restore_alert_enabled bit);
go
-- Create an SQL Agent Job with the Following Script
-- This will send an Email at Intervals determined by the job Schedule
-- The Job Should be Created on the Log Shipping Secondary Clustered Instance
-- This Job Requires that Database Mail is Enabled
truncate table msdb dbo log_shipping_report
go
insert into msdb dbo log_shipping_report
EXEC sp_help_log_shipping_monitor;
go
/*
select [server]
, database_name [database]
, time_since_last_copy [Last Copy Time]
, last_copied_file [Last Copied File]
, time_since_last_restore [Last Restore Time]
, last_restored_file [Last Restored File]
, restore_threshold [Restore Threshold]
, restore_threshold - time_since_last_restore [Restore Latency]
from msdb.dbo.log_shipping_report;
go
*/
DECLARE @tableHTML NVARCHAR(MAX) ;
DECLARE @SecServer SYSNAME ;
SET @SecServer = @@SERVERNAME
SET @tableHTML =
N'<H1><font face="Verdana" size="4">Transaction Logshipping Status from Secondary
Server ' + @SecServer + N'</H1>' +
N'<p style="margin-top: 0; margin-bottom: 0"><font face="Verdana" size="2">Please
find below status of Secondary databases: </font></p> ' +
N'<table border="1" style="BORDER-COLLAPSE: collapse" borderColor="#111111"
cellPadding="0" width="2000" bgColor="#ffffff" borderColorLight="#000000"
border="1"><font face="Verdana" size="2">' +
N'<tr><th><font face="Verdana" size="2">Secondary Server</th>
<th><font face="Verdana" size="2">Secondary Database</th>
<th><font face="Verdana" size="2">Last Copy Time</th>' +
N'<th><font face="Verdana" size="2">Last Copied File</th><th>
<font face="Verdana" size="2">Last Restore Time</th>' +
N'<th><font face="Verdana" size="2">Last Restored File</th><th>
<font face="Verdana" size="2">Restore Threshold</th>
<th><font face="Verdana" size="2">Restore Latency</th>' +
CAST ( ( SELECT td = lsr.server, '',
td = lsr [database_name], td = lsr time_since_last_copy '',
td = lsr last_copied_file td = lsr time_since_last_restore '',
td = lsr last_restored_file, '',
td = lsr restore_threshold '',
td =
case
when lsr restore_threshold
lsr time_since_last_restore < 0 then + '<td bgcolor="#FFCC99"><b><font face="Verdana"
size="1">' + 'CRITICAL' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore < 20 and lsr restore_threshold
lsr time_since_last_restore > 0 then + '<td bgcolor="#FFBB33"><b><font face="Verdana
size="1">' + 'WARNING' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore > 20 then + '<td bgcolor="#21B63F"><b><font face="Verdana
size="1">' + 'OK' + '</font></b></td>'
end , ''
FROM msdb dbo log_shipping_report as lsr
ORDER BY lsr.[database_name]
FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +
N'</table>' + ' ';
EXEC msdb dbo.sp_send_dbmail
@recipients='example@sqldat.com',
@copy_recipients='example@sqldat.com',
@subject = 'Transaction Log Shipping Report',
@body = @tableHTML,
@body_format = 'HTML' ;
Unidades de disco
Um efeito colateral de empilhar a instância do SQL Server e fazer provisão para vários bancos de dados é a tendência de ficar sem letras de unidade. Contornamos esse problema configurando os pontos de montagem de volume. Cada disco atribuído a uma função de cluster é configurado como um ponto de montagem com uma letra de unidade necessária apenas para uma ou duas unidades por instância. Um ponto importante a ser observado ao usar pontos de montagem de volume em um cluster é que, no futuro, quando você precisar adicionar mais pontos de montagem para executar tarefas de manutenção semelhantes, será necessário colocar AMBOS a unidade primária que possui a letra da unidade e a montagem ponto no modo de manutenção no cluster.
Em nosso caso, encontramos o nome de cada ponto de montagem de volume com base na função de cluster à qual foi atribuído. Com tantas unidades para lidar, você definitivamente precisaria descobrir uma maneira para você e o administrador de armazenamento identificar um disco exclusivo para que a manutenção dos discos no nível de armazenamento, por exemplo, não fosse muito trabalhosa.
Listagem 3: Monitorar o uso do espaço em disco ao usar pontos de montagem de volume
-- The Following Script Will Show Disk Space Usage from Within SQL Server -- It is Especially Helpful When Using Volume Mount Points -- Volume Mount Point Space Usage Can Also Be Monitored from Computer Management (OS Level) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name , CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Total Size (GB)] , CONVERT(DECIMAL(18 2 vs available_bytes 1073741824.0' AS [Available Size (GB)] , CAST(CAST(vs available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats f database_id, f [file_id]i AS vs OPTION (RECOMPILE);
Implantação de banco de dados
No nosso caso, nossa estratégia foi garantir que os novos bancos de dados seguissem nosso padrão. Bancos de dados mais antigos foram tratados com um pouco mais de cuidado, pois estávamos consolidando e atualizando ao mesmo tempo. O Database Migration Assistant ajudou a nos dizer quais bancos de dados definitivamente não seriam compatíveis com nossa sagrada instância do SQL Server 2016 e os deixamos em paz (alguns com níveis de compatibilidade tão baixos quanto 100). Cada banco de dados implantado deve ter seus próprios volumes para dados e arquivos de log, dependendo de seu tamanho. Usar volumes separados para cada banco de dados é mais um passo para ter um ambiente muito bem organizado, o que é importante considerando a potencial complexidade desse ambiente consolidado. A última instrução também implica que, quando você permite que um aplicativo crie seus próprios bancos de dados, você deve, como DBA, realocar os arquivos de dados após a implementação, pois o aplicativo usará os mesmos locais de arquivo usados pelo banco de dados modelo.
Listagem 4: Relocação de bancos de dados de usuários
-- 1. Set the database offline -- Be sure to replace DB_NAME with the actual database name ALTER DATABASE DB_NAME SET OFFLINE -- 2. Move the file or files to the new location. -- This means actually copying the datafiles at OS level -- You may also need grant the SQL Server Service account full permissions on the data file -- 3. For each file moved, run the following statement. ALTER DATABASE DB_NAME MODIFY FILE ( NAME = logical_name FILENAME = 'new_path\os_file_name') -- 4. Bring the database back online ALTER DATABASE database name SET ONLINE -- 5. Verify the file change: SELECT name, physical_name AS CurrentLocation, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'DB_NAME');
Gerenciamento de acesso
Você concordará que em nosso ambiente consolidado, podemos acabar tendo uma lista muito longa de objetos de nível de servidor, como logins. O uso de grupos do Windows ajudará a reduzir essa lista e simplificar o gerenciamento de acesso em cada instância clusterizada. Normalmente, você precisará de grupos criados no Active Directory para administradores de aplicativos que precisam de acesso, contas de serviços de aplicativos, usuários de negócios que precisam extrair relatórios e, claro, administradores de banco de dados. Um dos principais benefícios do uso de Grupos do Windows é que o acesso pode ser concedido ou revogado simplesmente gerenciando a associação desses grupos diretamente no Active Directory.
Provavelmente já é óbvio que esse benefício na área de Gerenciamento de Acesso só é possível com a Autenticação do Windows. Os logons do SQL Server não podem ser gerenciados em grupos.
Listagem 5: Logins de instância, usuários de banco de dados e suas funções
create table #userlist (
[Server Name] varchar(20)
,[Database Name] varchar(50)
,[Database User] varchar(50)
, [Database Role] varchar(50)
, [Instance Login] varchar(50)
, [Status] varchar(15)
)
go
insert into #userlist
exec sp_MSforeachdb @command1 ='
USE [?]
IF ''?'' NOT IN ("tempdb","model"J"msdb"J"master")
BEGIN
select @@servername as instance_name , ''?'' as database_name , rp.name as database_user , mp.name as database_role , sp.name as instance_login , case
when sp.is_disabled = 1 then ''Disabled'' when sp.is_disabled = 0 then ''Enabled'' end
[login_status]
from sys.database_principals rp
left outer join sys.database_role_members drm on (drm.member_principal_id = rp.principal_id)
left outer join sys.database_principals mp on (drm.role_principal_id = mp.principal_id)
left outer join sys.server_principals sp on (rp.sid=sp.sid)
where rp.type_desc in (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')
END' go
select * from #userlist go
drop table #userlist
Conclusão
Examinamos em um nível muito alto os benefícios que podem ser obtidos com o clustering e o empilhamento de instâncias do SQL Server como meio de obter consolidação, otimização de custos e facilidade de gerenciamento. Se você for capaz de comprar hardware grande, poderá explorar essa opção e colher os benefícios que descrevemos acima.