Introdução
Este artigo é uma breve revisão das principais manutenções programadas com uma base de dados do sistema de informação 24 horas por dia, 7 dias por semana, que não possui downtime, bem como abordagens para sua execução em MS SQL Server.
Quaisquer comentários e atualizações ao artigo são muito apreciados.
Manutenção programada
Há a seguinte manutenção programada que gostaria de salientar:
- Backups programados com verificação adicional sem restauração
- Restauração programada de backups para verificar seu desempenho
- Análise do dispositivo de armazenamento de dados que contém o sistema e todos os bancos de dados necessários
- Teste programado dos serviços necessários
- Otimização programada do desempenho de um sistema
- Manutenção programada da integridade dos dados
- Manutenção programada de validação de dados
Os três primeiros pontos são os mais importantes, pois proporcionam uma restauração do sistema após várias falhas. No entanto, eu recomendaria executar pelo menos três pontos também, para que os usuários possam trabalhar à vontade (assim, todas as consultas devem ser executadas rapidamente) e para que os dados sejam validados em todos os sistemas de relatórios.
Para automatizar a manutenção programada, é possível organizar suas peças no Agent ou no Windows Scheduler.
O sexto ponto é baseado no comando CHECKDB.
O sétimo ponto é implementado em direção à área de domínio utilizada no sistema de informação.
Vou falar em detalhes sobre os primeiros cinco pontos.
Backups programados com verificação adicional sem restauração
Como existem muitos artigos sobre esse tópico, deve-se notar que é necessário executar regularmente essa manutenção programada em um servidor de backup, e não no servidor principal. Este servidor de backup deve conter dados atualizados (por exemplo, aquele que foi obtido com a replicação). Além disso, você precisa fazer backup de todos os bancos de dados do sistema (exceto tempdb) em cada instância do MS SQL Server.
Quando o backup falha ou uma verificação de backup identifica um problema, é necessário relatar essas informações aos administradores. Por exemplo, você pode enviá-los por e-mail.
É importante determinar uma estratégia de backup, que responderá às seguintes perguntas:
- Com que frequência e quando devemos fazer backup dos dados (completo, diferencial e log de transações)?
- Por quanto tempo e quando devemos excluir os backups?
Restauração programada de backups para verificar seu desempenho
Eu recomendo executar este procedimento em um servidor de backup com utilitários de terceiros ou o RESTORE comando.
Quando a restauração do backup falha, é necessário relatar essas informações aos administradores. Por exemplo, você pode enviá-los por e-mail.
Além disso, é necessário restaurar os backups dos bancos de dados do sistema. Para fazer isso, você precisa restaurá-los como um banco de dados de usuário comum com um nome diferente dos nomes dos bancos de dados do sistema.
Análise de dispositivos de armazenamento de dados que contêm sistema e todos os bancos de dados necessários
Você precisa analisar quanto espaço cada banco de dados ocupa, como os tamanhos dos arquivos mudam e como os tamanhos de espaço livre em todo o dispositivo de armazenamento mudam. Por exemplo, você pode realizar esta tarefa parcialmente com a coleta automática de dados sobre arquivos de bancos de dados e unidades lógicas do sistema operacional no MS SQL Server.
Você pode fazer essa verificação todos os dias e depois enviar os resultados. Como de costume, você pode enviá-los para um e-mail.
Também é necessário monitorar os bancos de dados do sistema para garantir que tudo funcione corretamente.
Além disso, é importante testar os dispositivos de armazenamento para verificar se há depreciação ou setores defeituosos.
Observe que, durante o teste, um dispositivo deve estar fora de operação e todos os dados devem ser copiados para outro dispositivo, pois o teste carrega o dispositivo drasticamente.
Esta tarefa está estritamente relacionada aos deveres do administrador do sistema, portanto, a deixaremos de lado. Para assumir o controle total sobre o caso, você precisa automatizar a entrega de relatórios por e-mail.
Eu recomendaria executar este teste duas vezes por ano.
Testes agendados dos serviços necessários
O tempo de inatividade do serviço é uma prática ruim. Portanto, um servidor de backup entrará em ação em caso de falhas. Ainda assim, é necessário verificar os logs de tempos em tempos. Além disso, você também pode pensar em uma coleta automática de dados com notificação adicional a um administrador enviando um e-mail.
É necessário verificar as tarefas do SQL Server Agent ou do Windows Scheduler com uma coleta automática de dados sobre as tarefas concluídas no MS SQL Server.
Otimização programada do desempenho de um sistema
Inclui os seguintes aspectos:
- Automatizando a desfragmentação de índice em bancos de dados MS SQL Server
- Automatizando a coleta de dados sobre alterações de esquemas de banco de dados no MS SQL Server. Você pode restaurar um backup e comparar as alterações, por exemplo, usando dbForge
- Automatizando a limpeza de processos travados no MS SQL Server
- Limpando o cache do procedimento. Aqui você precisa determinar quando e o que deve ser limpo
- Implementação de um indicador de desempenho
- Desenvolver e modificar índices clusterizados
Além disso, recomendo desativar o AUTO_CLOSE característica.
Às vezes, por diferentes motivos, um otimizador paraleliza uma consulta, o que nem sempre é ideal.
Assim, existem algumas recomendações que você deve ter em mente:
- Se você obtiver muitos dados, deixe o paralelismo.
- Se você obtiver alguns dados, não use paralelismo.
Existem dois parâmetros nas configurações da instância do SQL Server responsáveis pelo paralelismo:
- máximo grau de paralelismo. Para desativar o paralelismo, defina "1" como um valor, o que significa que apenas um processador executará um código.
- limite de custo para paralelismo. Ele deve ser definido por padrão.
Existem duas filas principais:
- uma fila para o tempo de CPU (fila QCPU). Ocorre quando uma consulta foi habilitada e está esperando que um processador a execute.
- uma fila para recursos (fila QR). Ocorre quando uma consulta está aguardando que os recursos sejam desvinculados para executar o processo.
A fórmula a seguir descreve a execução da consulta (T):
T=TP+TQR+TCPU+TQCPU, onde:
- TP está compilando o tempo para um plano
- TQR é o tempo de fila para recursos (fila QR)
- TQCPU é o tempo de fila para que os recursos sejam desvinculados (fila QCPU)
- TCPU é hora de executar uma consulta
Na exibição do sistema sys.dm_exec_query_stats:
- total_worket_time =TP+TCPU+TQCPU
- total_elapsed_time =TQR+TCPU
As ferramentas integradas não permitem avaliar com precisão o tempo de execução da consulta.
Na maioria dos casos, total_elapsed_time fornece o tempo próximo ao tempo de execução da consulta.
Você pode determinar o tempo de execução da consulta com mais precisão usando o rastreamento. Como alternativa, você pode registrar o horário de início e término da consulta. Tenha cuidado com os rastreamentos, pois eles carregam significativamente o sistema. Assim, é melhor realizá-lo em um servidor de backup e coletar dados do servidor principal. Neste caso, apenas a rede será carregada.
Ao paralelizar, o SQL Server aloca N processos para uma consulta (na edição Standard n<=4). Cada processo requer tempo de CPU para executar uma consulta (um processo nem sempre deve ser executado em cada núcleo).
Quanto mais processos você tiver, mais chances de alguns serem substituídos por outros, o que leva ao aumento do TQCPU.
Pode levar muito mais tempo para executar uma consulta ao paralelizar, nos seguintes casos:
- Baixa taxa de transferência do subsistema de disco. Nesse caso, a decomposição da consulta leva muito mais tempo.
- Os dados podem ser bloqueados para o processo.
- Não há índice para o predicado, o que leva a uma verificação da tabela.
Observações:
Você precisa desabilitar as consultas de paralelismo em servidores onde não há necessidade de realizar uma seleção enorme (total_worket_time deve ser reduzido devido a uma possível diminuição de TCPU e TQCPU). Para fazer isso, você precisa definir o grau máximo de recurso de paralelismo em '1' para que apenas um processador funcione.
Além disso, você pode usar outros frameworks para construir um sistema que determina o desempenho de alta velocidade dos bancos de dados . É importante entender como essas estruturas funcionam e como interpretar os números recuperados.
Quanto ao desenvolvimento e modificação de índices, nomeadamente índices clusterizados, o ponto principal é perceber como é definida a lógica dos índices e como funciona.
Lembre-se de que chaves primárias e clusterizadas não significam a mesma coisa:
Uma chave primária é uma coluna ou um conjunto de colunas, que tornam um registro exclusivo na tabela. Para a chave primária, você pode criar um índice clusterizado ou não clusterizado exclusivo. A chave primária é usada em outras tabelas como chave estrangeira para fornecer integridade de dados.
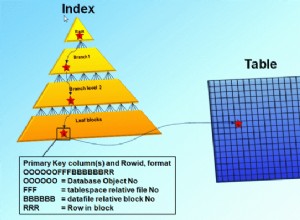
Um índice clusterizado é uma árvore B ou sua modificação. As folhas contêm os dados em si, enquanto os nós contêm informações de índice. Além disso, um índice clusterizado também pode ser não exclusivo. Ainda assim, recomendo que seja único.
Gostaria de lembrar que uma árvore B é uma estrutura que armazena dados na ordem filtrada por um índice clusterizado. Assim, é importante agrupar os campos selecionados como um índice clusterizado em ordem decrescente ou crescente. Para um índice clusterizado, você pode usar colunas de inteiro (identidade), assim como dados e hora. Ainda assim, colunas como identificador único não são adequadas, pois este último levará à reestruturação regular de uma árvore B, o que aumentará a quantidade de leituras e registros em um dispositivo de armazenamento onde o banco de dados está localizado.
Além disso, você precisa certificar-se de que o índice seja usado com a exibição do sistema sys.dm_db_index_usage_stats.
P.S. É necessário verificar se os dados estão atualizados em um servidor de backup, bem como verificar um sistema que sincronize esses dados (por exemplo, replicações).
Leia também:
Automatizando a desfragmentação de índice em bancos de dados MS SQL Server
Coleta Automática de Dados de Alterações de Esquema de Banco de Dados no MS SQL Server
Exclusão automática de processos presos no MS SQL Server
Solucionando problemas de consultas de longa duração no MS SQL Server
Implementação de um indicador de desempenho