O SQL DISTINCT é bom (ou ruim) quando você precisa remover duplicatas nos resultados?
Alguns dizem que é bom e adicionam DISTINCT quando aparecem duplicatas. Alguns dizem que é ruim e sugerem usar GROUP BY sem uma função de agregação. Outros dizem que DISTINCT e GROUP BY são os mesmos quando você precisa remover duplicatas.
Este post vai mergulhar nos detalhes para obter respostas corretas. Então, eventualmente, você usará a melhor palavra-chave com base na necessidade. Vamos começar.
Um breve lembrete sobre os fundamentos da instrução SQL SELECT DISTINCT
Antes de nos aprofundarmos, vamos relembrar o que é a instrução SQL SELECT DISTINCT. Uma tabela de banco de dados pode incluir valores duplicados por vários motivos, mas podemos querer obter apenas os valores exclusivos. Nesse caso, SELECT DISTINCT é útil. Essa cláusula DISTINCT faz com que a instrução SELECT busque apenas registros exclusivos.
A sintaxe do comando é simples:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Aqui, a condição WHERE é opcional.
A instrução se aplica a uma única coluna e a várias colunas. A sintaxe desta instrução aplicada a várias colunas é a seguinte:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Observe que o cenário de consulta de várias colunas sugerirá o uso da combinação de valores em todas as colunas definidas pela instrução para determinar a exclusividade.
E agora, vamos explorar o uso prático e as capturas da aplicação da instrução SELECT DISTINCT.
Como o SQL DISTINCT funciona para remover duplicatas
Obter respostas não é tão difícil de encontrar. O SQL Server nos forneceu planos de execução para ver como uma consulta será processada para nos fornecer os resultados necessários.
A seção a seguir se concentra no plano de execução ao usar DISTINCT. Você precisa pressionar Ctrl-M no SQL Server Management Studio antes de executar as consultas abaixo. Ou clique em Incluir Plano de Execução Real da barra de ferramentas.
Planos de consulta em SQL DISTINCT
Vamos começar comparando 2 consultas. A primeira não usará DISTINCT e a segunda consulta.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Aqui está o plano de execução:
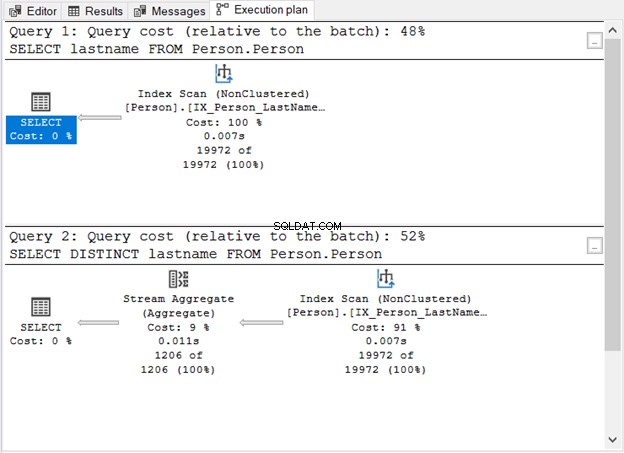
O que a Figura 1 nos mostrou?
- Sem a palavra-chave DISTINCT, a consulta é simples.
- Uma etapa extra aparece após adicionar DISTINCT.
- O custo de consulta do uso de DISTINCT é maior do que sem ele.
- Ambos têm operadores Index Scan. Isso é compreensível porque não há uma cláusula WHERE específica em nossas consultas.
- A etapa extra, o operador Stream Aggregate, é usada para remover as duplicatas.
O número de leituras lógicas é o mesmo (107) se você verificar o STATISTICS IO. No entanto, o número de registros é muito diferente. 19.972 linhas são retornadas pela primeira consulta. Enquanto isso, 1.206 linhas são retornadas pela segunda consulta.
Portanto, você não pode adicionar DISTINCT quando quiser. Mas se você precisar de valores exclusivos, essa é uma sobrecarga necessária.
Existem operadores usados para gerar valores exclusivos. Vamos examinar alguns deles.
STREAM AGREGATE
Este é o operador que você viu na Figura 1. Ele aceita uma única entrada e gera um resultado agregado. Na Figura 1, a entrada vem do operador Index Scan. No entanto, o Stream Aggregate precisa de uma entrada classificada.
Como você pode ver na Figura 1, ele usa o IX_Person_LastName_FirstName_MiddleName , um índice não exclusivo de nomes. Como o índice já classifica os registros por nome, o Stream Aggregate aceita a entrada. Sem o índice, o otimizador de consulta pode optar por usar um operador Sort extra no plano. E isso vai ser mais caro. Ou pode usar um Hash Match.
HASH MATCH (AGREGADO)
Outro operador usado pelo DISTINCT é o Hash Match. Este operador é usado para junções e agregações.
Ao usar DISTINCT, o Hash Match agrega os resultados para produzir valores exclusivos. Aqui está um exemplo.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
E aqui está o plano de execução:
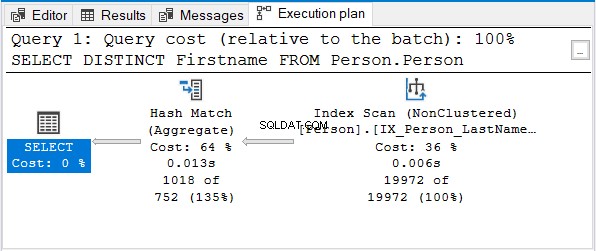
Mas por que não Stream Aggregate?
Observe que o mesmo índice de nome é usado. Esse índice classifica com Sobrenome primeiro. Portanto, um Nome somente a consulta ficará sem classificação.
Hash Match (Aggregate) é a próxima opção lógica para remover as duplicatas.
HASH MATCH (FLOW DISTINCT)
O Hash Match (Aggregate) é um operador de bloqueio. Assim, ele não produzirá a saída que processou em todo o fluxo de entrada. Se restringirmos o número de linhas (como usar TOP com DISTINCT), ele produzirá uma saída exclusiva assim que essas linhas estiverem disponíveis. É disso que se trata o Hash Match (Flow Distinct).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
A consulta usa TOP 100 junto com DISTINCT. Aqui está o plano de execução:
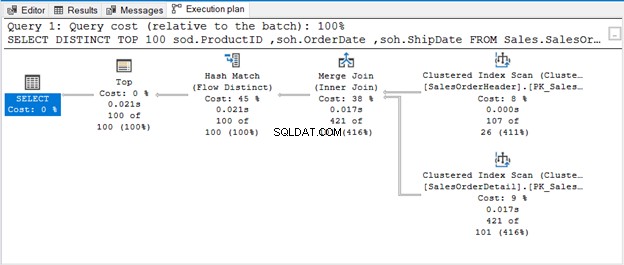
QUANDO NÃO HÁ OPERADOR PARA REMOVER DUPLICATAS
Sim. Isso pode acontecer. Considere o exemplo abaixo.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Em seguida, verifique o plano de execução:
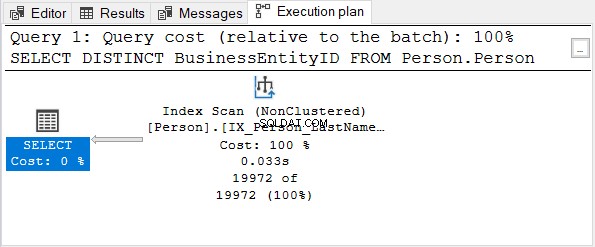
O BusinessEntityID coluna é a chave primária. Como essa coluna já é exclusiva, não adianta aplicar DISTINCT. Tente remover DISTINCT da instrução SELECT – o plano de execução é o mesmo da Figura 4.
O mesmo acontece ao usar DISTINCT em colunas com um índice exclusivo.
SQL DISTINCT funciona em TODAS as colunas na lista SELECT
Até agora, usamos apenas 1 coluna em nossos exemplos. No entanto, DISTINCT funciona em TODAS as colunas especificadas na lista SELECT.
Aqui está um exemplo. Essa consulta garantirá que os valores de todas as 3 colunas sejam exclusivos.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Observe as primeiras linhas no conjunto de resultados na Figura 5.
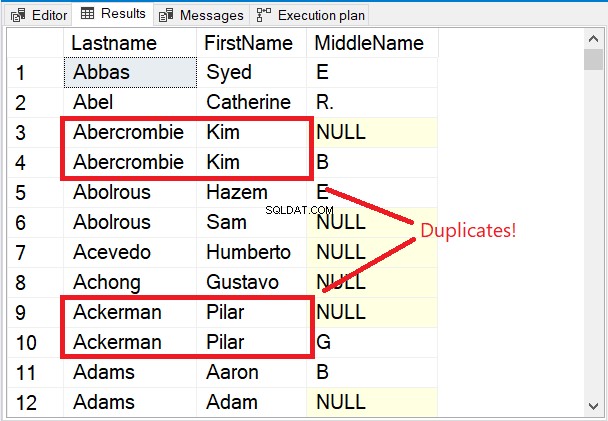
As primeiras linhas são todas exclusivas. A palavra-chave DISTINCT garantiu que o Nome do meio coluna também é considerada. Observe os 2 nomes marcados em vermelho. Considerando o Sobrenome e Nome só irá torná-los duplicados. Mas adicionar Nome do meio para a mistura mudou tudo.
E se você quiser obter nomes e sobrenomes exclusivos, mas incluir o nome do meio no resultado?
Você tem 2 opções:
- Adicione uma cláusula WHERE para remover nomes do meio NULL. Isso removerá todos os nomes com um nome do meio NULL.
- Ou adicione uma cláusula GROUP BY em Sobrenome e Nome colunas. Em seguida, use a função de agregação MIN no Nome do meio coluna. Isso obterá 1 nome do meio com o mesmo sobrenome e nome.
SQL DISTINCT vs. GROUP BY
Ao usar GROUP BY sem uma função de agregação, ele age como DISTINCT. Como nós sabemos? Uma maneira de descobrir é usar um exemplo.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Execute-os e confira o plano de execução. É como a imagem abaixo?
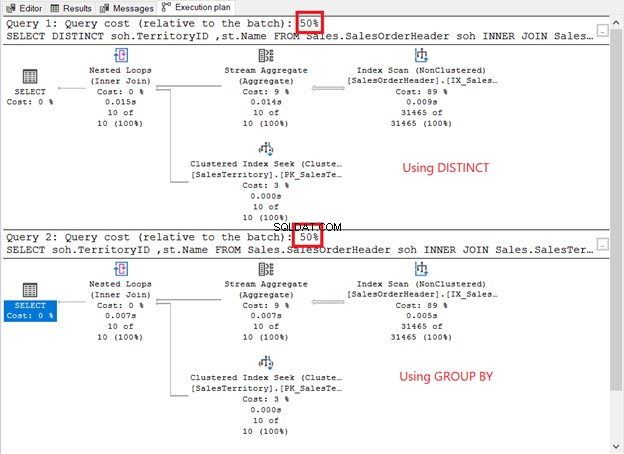
Como eles se comparam?
- Eles têm os mesmos operadores de plano e sequência.
- O custo do operador de cada um e os custos de consulta são os mesmos.
Se você verificar o QueryPlanHash propriedades dos 2 operadores SELECT, eles são os mesmos. Portanto, o otimizador de consulta usou o mesmo processo para retornar os mesmos resultados.
No final, não podemos dizer que usar GROUP BY é melhor que DISTINCT para retornar valores únicos. Você pode provar isso usando os exemplos acima para substituir DISTINCT por GROUP BY.
Agora é uma questão de preferência qual você vai usar. Eu prefiro DISTINTO. Ele informa explicitamente a intenção na consulta – para produzir resultados exclusivos. E para mim, GROUP BY é para agrupar resultados usando uma função de agregação. Essa intenção também é clara e consistente com a própria palavra-chave. Eu não sei se alguém vai manter minhas consultas um dia. Portanto, o código deve ser claro.
Mas esse não é o fim da história.
Quando SQL DISTINCT não é o mesmo que GROUP BY
Eu apenas expressei minha opinião, e então isso?
É verdade. Eles não serão os mesmos o tempo todo. Considere este exemplo.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Embora o conjunto de resultados não seja classificado, as linhas são as mesmas do exemplo anterior. A única diferença é o uso de uma subconsulta:
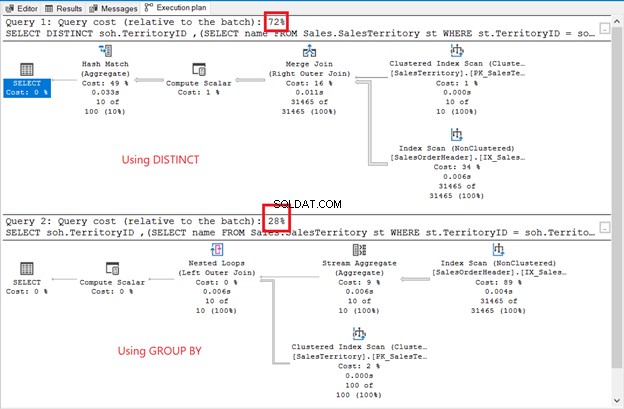
As diferenças são óbvias:operadores, custo de consulta, plano geral. Desta vez, GROUP BY ganha com apenas 28% do custo da consulta. Mas aqui está a coisa.
O objetivo é mostrar que eles podem ser diferentes. Isso é tudo. Isso não é de forma alguma uma recomendação. Usar uma junção tem um plano de execução melhor (veja a Figura 6 novamente).
O resultado final
Aqui está o que aprendemos até agora:
- DISTINCT adiciona um operador de plano para remover duplicatas.
- DISTINCT e GROUP BY sem uma função agregada resultam no mesmo plano. Em suma, eles são os mesmos na maioria das vezes.
- Às vezes, DISTINCT e GROUP BY podem ter planos diferentes quando uma subconsulta está envolvida na lista SELECT.
Então, o SQL DISTINCT é bom ou ruim na remoção de duplicatas nos resultados?
Os resultados dizem que é bom. Não é melhor nem pior que GROUP BY porque os planos são os mesmos. Mas é um bom hábito verificar o plano de execução. Pense na otimização desde o início. Dessa forma, se você tropeçar com quaisquer diferenças em DISTINCT e GROUP BY, você as identificará.
Além disso, as ferramentas modernas tornam essa tarefa muito mais simples. Por exemplo, um produto popular dbForge SQL Complete da Devart tem um recurso específico que calcula valores nas funções agregadas no conjunto de resultados prontos da grade de resultados do SSMS. Os valores DISTINCT também estão presentes lá.
Gostou da postagem? Então, por favor, espalhe a notícia compartilhando-a em suas plataformas de mídia social favoritas.
Artigos relacionados para obter mais informações
- SQL GROUP BY:3 dicas fáceis para agrupar resultados como um profissional
- SQL INSERT INTO SELECT:5 maneiras fáceis de lidar com duplicatas
- O que são funções de agregação SQL? (Dicas fáceis para iniciantes)
- Otimização de consultas SQL:5 fatos essenciais para impulsionar consultas



