Introdução
Neste artigo, falaremos sobre o uso do nvarchar tipo de dados. Exploraremos como o SQL Server armazena esse tipo de dados no disco e como ele é processado na RAM. Também examinaremos como o tamanho de nvarchar pode afetar o desempenho.
Tamanho real dos dados:nchar vs nvarchar
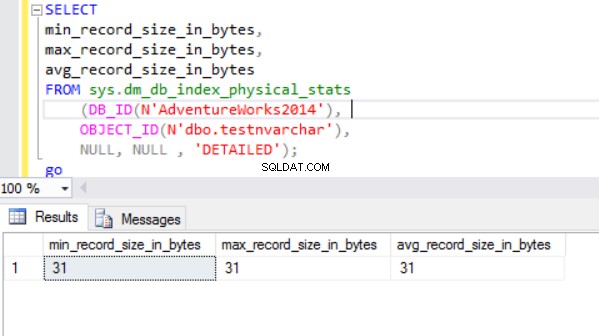
Usamos nvarchar quando o tamanho das entradas de dados da coluna provavelmente irá variar consideravelmente. O tamanho do armazenamento (em bytes) é o dobro do tamanho real dos dados inseridos + 2 bytes. Isso nos permite economizar armazenamento em disco em comparação com o uso de nchar tipo de dados. Consideremos o seguinte exemplo. Estamos criando duas tabelas. Uma tabela contém a coluna nvarchar, outra tabela contém colunas nchar. O tamanho da coluna é de 2.000 caracteres (4.000 bytes).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
O tamanho real da linha é:
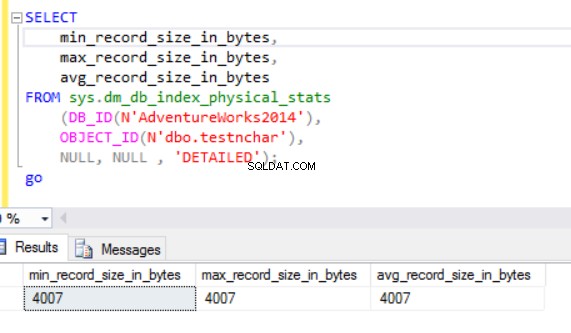
Como podemos ver, o tamanho real da linha do tipo de dados nvarchar é muito menor que o tipo de dados nchar. No caso do tipo de dados nchar, usamos ~4000 bytes para armazenar uma string de caracteres de 10 símbolos. Usamos ~20 bytes para armazenar a mesma string de caracteres no caso do tipo de dados nvarchar.
O mecanismo do SQL Server processa dados na RAM (pool de buffers). E quanto ao tamanho da linha na memória?
Tamanho real dos dados:HDD vs RAM
Vamos executar a seguinte consulta:
SELECT col1 FROM dbo.testnchar;

Não há diferença entre a utilização do disco e da RAM no caso da cadeia de caracteres de comprimento fixo.
SELECT col1 FROM dbo.testnvarchar;

Podemos ver que o SQL Server Engine solicitou a memória apenas para metade do tamanho da linha declarada (2000 bytes em vez de 20 bytes reais) e vários bytes para obter informações adicionais. De um lado, diminuímos o uso de espaço em disco, mas de outro podemos inflar a RAM solicitada. Este é um efeito colateral do uso de tipos de dados de caracteres variados. Esse efeito colateral pode impactar fortemente os recursos em alguns casos.
FORMAT():RAM solicitada vs RAM utilizada
Usamos a função FORMAT, que retorna um valor formatado com o formato especificado e cultura opcional. O valor de retorno é nvarchar ou nulo. O comprimento do valor de retorno é determinado pelo formato . FORMAT(getdate(), 'yyyyMMdd','en-US') resultará em '20170412'. Precisamos de 16 bytes para armazenar este resultado na coluna do disco (o resultado será nvarchar(8)). Qual é o tamanho dos dados na RAM para os dados específicos?
Vamos executar a seguinte consulta. Utilizamos o seguinte ambiente:
- AdventureWorks2014
- Edição de desenvolvimento do MS SQL 2016
- dbo.Customer (19.820.000 registros) contém dados de Sales.Customer (19.820 registros foram enviados 1.000 vezes):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
O plano de execução da consulta é bastante simples:

A primeira operação é “Verificação de índice clusterizado” na tabela dbo.Customer. ~19 000 000 registros foram lidos. O tamanho de dados estimado é de 435 Mb.
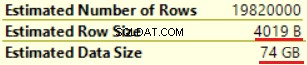
A próxima operação é “Compute Scalar” (cálculo da função FORMAT()). O resultado é bastante inesperado, pois formatamos uma cadeia de caracteres de 16 bytes. O tamanho da linha aumentou drasticamente de 23 bytes para 4019 bytes. O mesmo com o tamanho de dados estimado — de 435 MB a 74 GB. Podemos ver que FORMAT() retorna NVARCHAR(4000).
O MS SQL Server 2016 tem a grande capacidade de mostrar concessão de memória excessiva. Podemos ver o aviso na última operação (T-SQL SELECT INTO):
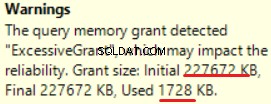
Isso é “sobreconcedido” da memória:mais de 90% da memória concedida não é usada.
As estatísticas de tempo de consulta são:
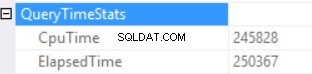
O longo tempo de execução depende de uma execução de função escalar não efetiva e do efeito colateral de um Excessive Memory Grant – Hash Match (Right Outer Join). Temos um efeito cumulativo de duas causas diferentes:execução de múltiplas funções escalares e concessão excessiva de memória.
O mecanismo do SQL Server não pode conceder mais de 25% da memória permitida por consulta. Podemos alterar esse valor na edição corporativa do MS SQL Server usando o governador de recursos. A memória concedida consiste em duas partes:necessária e adicional. Uma memória necessária é usada para as necessidades internas – para operações de classificação e junção de hash. A memória adicional é baseada no Tamanho de Dados Estimado. Se a memória necessária e a adicional excederem o limite de 25%, o mecanismo do SQL Server concederá outros 25% da memória disponível. Leia a postagem de concessão de memória do SQL Server para obter detalhes.
Vamos executar a mesma consulta sem a função FORMAT().
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
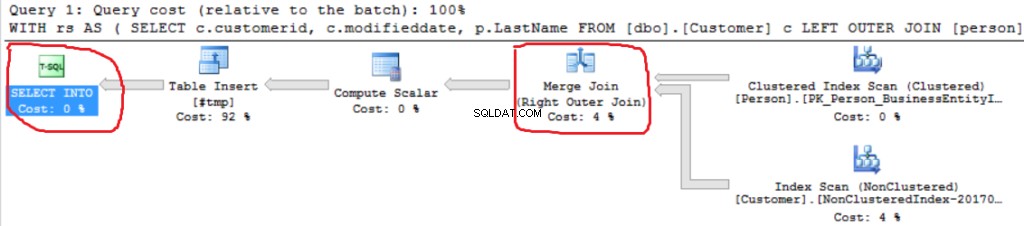
Podemos ver outra implementação do Right Outer Join (Merge Join em vez de Hash Join).
As informações de concessão de memória são (se não houver classificação e o hash Join SQL Server não puder conceder memória):
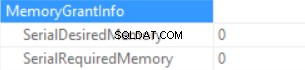
As estatísticas de tempo de consulta são (o tempo é reduzido de forma previsível:nenhuma execução de função escalar, o tamanho estimado dos dados é menor do que no exemplo anterior):

Portanto, estamos inflando a “memória concedida” em até 222 MB (e estamos usando menos de 2 MB) usando a função FORMAT(). O volume de dados no exemplo é pequeno.
Consulta de execução longa
Considere a consulta SQL real de um ambiente de produção. Esta consulta foi executada durante um processo de carregamento em lote (não um cenário transacional clássico). Usamos o MS SQL Server iniciado na Amazon Web Services (AWS, Amazon Relational Database Service). As características da instância de banco de dados são 160 GB de RAM (não mais que ~ 30 GB de RAM podem ser concedidos por consulta) e 40 vCPU. A consulta SQL foi quase igual ao exemplo acima (a diferença está na quantidade de tabelas e no tamanho dos dados):CTE incluiu junção entre 6 tabelas. A “tabela mestra” (uma tabela na cláusula FROM) contém aproximadamente 175.000.000 registros e o tamanho dos dados é de 20 GB. As tabelas Lookup (tabela direita na cláusula JOIN) são pequenas (em comparação com a tabela principal). A consulta SQL contém duas chamadas da função FORMAT() (duas colunas da tabela “master table” são o parâmetro desta função).
A consulta de produção se parece com isso:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
A “imagem” do plano de execução está abaixo (o plano de execução é simples:junções sequenciais e ordenação (palavras-chave DISTINTAS) no topo):

Vamos explorar as informações em detalhes.
A primeira operação é “Table scan” (tudo está correto, sem surpresas):

A operação de “computação escalar” aumenta drasticamente o tamanho estimado da linha, bem como o tamanho estimado da linha (de 19 GB até 1,3 TB). Duas chamadas da função FORMAT() adicionaram cerca de 8.000 bytes ao tamanho estimado da linha (mas o tamanho real dos dados é menor).

Uma das operações JOIN (Hash Match, Right Outer Join) usa colunas não exclusivas da tabela direita. Não importa no caso de alguns registros. Este não é o nosso caso. Como resultado, o tamanho estimado dos dados está aumentando em até ~2,4 TB.

Há um aviso também (não há RAM suficiente para processar esta operação):
A consulta SQL contém uma operação “Distinct Sort” na parte superior, que se parece com a cereja no topo de um bolo. Podemos ver o mesmo aviso lá.
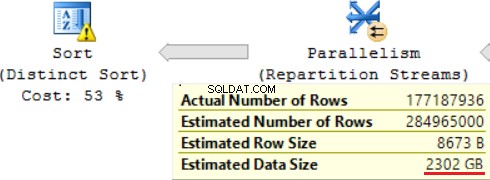
Um resultado do uso de uma função escalar é um longo tempo para execução da consulta:24 horas. Uma das causas desse problema é uma estimativa incorreta do tamanho dos dados solicitados com base no “Tamanho estimado dos dados”. Sem usar a função FORMAT(), o MS SQL Server executa essa consulta em 2 horas.
Conclusão
Os desenvolvedores devem ter cuidado ao usar os tipos de dados nvarchar e varchar. A seleção de tipos de dados redundantes para colunas pode levar ao aumento da memória necessária. Como resultado, a RAM será desperdiçada, o desempenho do banco de dados será degradado.