Introdução
Não importa o quanto tentemos projetar e desenvolver aplicativos, sempre ocorrerão erros. Existem duas categorias gerais – erros de sintaxe ou lógicos podem ser erros de programação ou consequências do design incorreto do banco de dados. Caso contrário, você pode receber um erro devido à entrada incorreta do usuário.
T-SQL (a linguagem de programação do SQL Server) permite o tratamento de ambos os tipos de erro. Você pode depurar o aplicativo e decidir o que precisa fazer para evitar erros no futuro.
A maioria dos aplicativos exige que você registre erros, implemente relatórios de erros fáceis de usar e, quando possível, lide com erros e continue a execução do aplicativo.
Os usuários lidam com erros em um nível de instrução. Isso significa que quando você executa um lote de comandos SQL e o problema ocorre na última instrução, tudo que precede esse problema será confirmado no banco de dados como transações implícitas. Isso pode não ser o que você deseja.
Os bancos de dados relacionais são otimizados para execução de instruções em lote. Assim, você precisa executar um lote de instruções como uma unidade e falhar em todas as instruções se uma instrução falhar. Você pode fazer isso usando transações. Este artigo se concentrará no tratamento de erros e nas transações, pois esses tópicos estão fortemente conectados.
Tratamento de erros SQL
Para simular exceções, precisamos produzi-las de forma repetível. Vamos começar com o exemplo mais simples – divisão por zero:
SELECT 1/0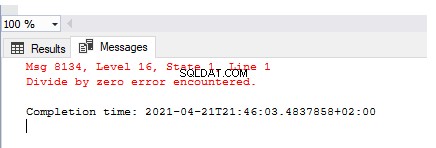
A saída descreve o erro lançado – Dividir por zero erro encontrado . Mas esse erro não foi tratado, registrado ou personalizado para produzir uma mensagem amigável.
O tratamento de exceção começa colocando as instruções que você deseja executar no bloco BEGIN TRY…END TRY.
O SQL Server manipula (captura) erros no bloco BEGIN CATCH…END CATCH, onde você pode inserir uma lógica personalizada para log ou processamento de erros.
A instrução BEGIN CATCH deve seguir imediatamente após a instrução END TRY. A execução é então passada do bloco TRY para o bloco CATCH na primeira ocorrência de erro.
Aqui você pode decidir como lidar com os erros, se deseja registrar os dados sobre exceções levantadas ou criar uma mensagem amigável.
O SQL Server possui funções internas que podem ajudá-lo a extrair detalhes do erro:
- ERROR_NUMBER():retorna o número de erros de SQL.
- ERROR_SEVERITY():Retorna o nível de gravidade que indica o tipo de problema encontrado e seu nível. Os níveis 11 a 16 podem ser manipulados pelo usuário.
- ERROR_STATE():Retorna o número do estado do erro e fornece mais detalhes sobre a exceção lançada. Você usa o número do erro para pesquisar na base de conhecimento da Microsoft detalhes específicos do erro.
- ERROR_PROCEDURE():retorna o nome do procedimento ou gatilho no qual o erro foi gerado ou NULL se o erro não ocorreu no procedimento ou gatilho.
- ERROR_LINE():Retorna o número da linha em que ocorreu o erro. Pode ser o número da linha de procedimentos ou acionadores ou o número da linha no lote.
- ERROR_MESSAGE():retorna o texto da mensagem de erro.
O exemplo a seguir mostra como lidar com erros. O primeiro exemplo contém a Divisão por zero erro, enquanto a segunda afirmação está correta.
BEGIN TRY
PRINT 1/0
SELECT 'Correct text'
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH

Se a segunda instrução for executada sem tratamento de erros (SELECT ‘Texto correto’), ela será bem-sucedida.
Como implementamos o tratamento de erros personalizado no bloco TRY-CATCH, a execução do programa é passada para o bloco CATCH após o erro na primeira instrução e a segunda instrução nunca foi executada.
Desta forma, você pode modificar o texto dado ao usuário e controlar melhor o que acontece se ocorrer um erro. Por exemplo, registramos erros em uma tabela de log para análise posterior.
Usando transações
A lógica de negócios pode determinar que a inserção da primeira instrução falha quando a segunda instrução falha ou que você pode precisar repetir as alterações da primeira instrução na falha da segunda instrução. O uso de transações permite executar um lote de instruções como uma unidade que falha ou é bem-sucedida.
O exemplo a seguir demonstra o uso de transações.
Primeiro, criamos uma tabela para testar os dados armazenados. Em seguida, usamos duas transações dentro do bloco TRY-CATCH para simular as coisas que acontecem se uma parte da transação falhar.
Usaremos a instrução CATCH com a instrução XACT_STATE(). A função XACT_STATE() é usada para verificar se a transação ainda existe. Caso a transação seja revertida automaticamente, a ROLLBACK TRANSACTION produziria uma nova exceção.
Dê um loot no código abaixo:
-- CREATE TABLE TEST_TRAN(VALS INT)
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(1);
COMMIT TRANSACTION
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(2);
INSERT INTO TEST_TRAN(VALS) VALUES('A');
INSERT INTO TEST_TRAN(VALS) VALUES(3);
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() > 0 ROLLBACK TRANSACTION
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
SELECT * FROM TEST_TRAN
-- DROP TABLE TEST_TRAN
A imagem mostra os valores na tabela TEST_TRAN e as mensagens de erro:
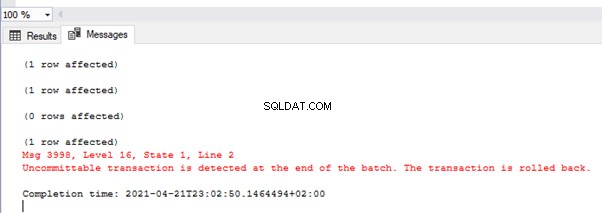
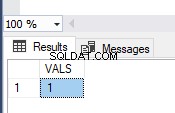
Como você vê, apenas o primeiro valor foi confirmado. Na segunda transação, tivemos um erro de conversão de tipo na segunda linha. Assim, todo o lote foi revertido.
Dessa forma, você pode controlar quais dados entram no banco de dados e como os lotes são processados.
Gerando mensagem de erro personalizada no SQL
Às vezes, queremos criar mensagens de erro personalizadas. Normalmente, eles são destinados a cenários em que sabemos que um problema pode ocorrer. Podemos produzir nossas próprias mensagens personalizadas dizendo que algo errado aconteceu sem mostrar detalhes técnicos. Para isso, estamos usando a palavra-chave THROW.
BEGIN TRY
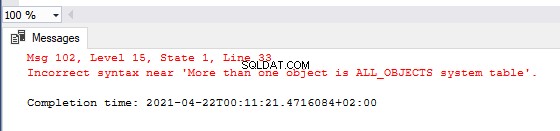
IF ( SELECT COUNT(sys.all_objects) > 1 )
THROW ‘More than one object is ALL_OBJECTS system table’
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
Ou gostaríamos de ter um catálogo de mensagens de erro personalizadas para categorização e consistência do monitoramento e relatório de erros. O SQL Server nos permite predefinir o código, a gravidade e o estado da mensagem de erro.
Um procedimento armazenado chamado “sys.sp_addmessage” é usado para adicionar mensagens de erro personalizadas. Podemos usá-lo para chamar a mensagem de erro em vários lugares.
Podemos chamar RAISERROR e enviar o número da mensagem como um parâmetro em vez de codificar os mesmos detalhes do erro em vários lugares no código.
Ao executar o código selecionado abaixo, estamos adicionando o erro personalizado no SQL Server, levantando-o e usando sys.sp_dropmessage para descartar a mensagem de erro definida pelo usuário especificada:
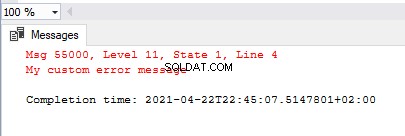
exec sys.sp_addmessage @msgnum=55000, @severity = 11,
@msgtext = 'My custom error message'
GO
RAISERROR(55000,11,1)
GO
exec sys.sp_dropmessage @msgnum=55000
GO
Além disso, podemos visualizar todas as mensagens no SQL Server executando o formulário de consulta abaixo. Nossa mensagem de erro personalizada é visível como o primeiro item no conjunto de resultados:
SELECT * FROM master.dbo.sysmessages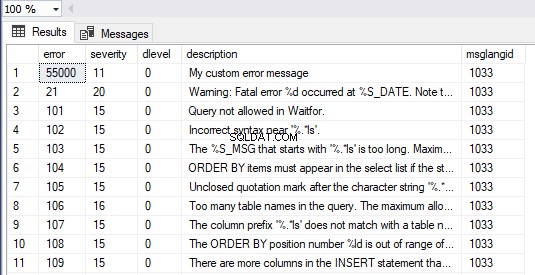
Criar um sistema para registrar erros
É sempre útil registrar erros para depuração e processamento posteriores. Você também pode colocar gatilhos nessas tabelas registradas e até configurar uma conta de e-mail e ser um pouco criativo na maneira de notificar as pessoas quando ocorrer um erro.
Para registrar erros, criamos uma tabela chamada DBError_Log , que pode ser usado para armazenar os dados de detalhes do log:
CREATE TABLE DBError_Log
(
DBError_Log_ID INT IDENTITY(1, 1) PRIMARY KEY,
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME
);
Para simular o mecanismo de registro, estamos criando o GenError procedimento armazenado que gera a Divisão por zero error e registra o erro no DBError_Log tabela:
CREATE PROCEDURE dbo.GenError
AS
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
INSERT INTO dbo.DBError_Log
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE()
);
END CATCH
GO
EXEC dbo.GenError
SELECT * FROM dbo.DBError_Log
O DBError_Log table contém todas as informações que precisamos para depurar o erro. Além disso, fornece informações adicionais sobre o procedimento que causou o erro. Embora isso possa parecer um exemplo trivial, você pode estender essa tabela com campos adicionais ou usá-la para preenchê-la com exceções personalizadas.
Conclusão
Se queremos manter e depurar aplicativos, pelo menos queremos relatar que algo deu errado e também registrá-lo nos bastidores. Quando temos um aplicativo de nível de produção usado por milhões de usuários, o tratamento de erros consistente e reportável é a chave para depurar problemas em tempo de execução.
Embora possamos registrar o erro original no log de erros do banco de dados, os usuários devem ver uma mensagem mais amigável. Portanto, seria uma boa ideia implementar mensagens de erro personalizadas que são lançadas para aplicativos de chamada.
Qualquer que seja o design que você implemente, você precisa registrar e tratar as exceções do usuário e do sistema. Essa tarefa não é difícil com o SQL Server, mas você precisa planejá-la desde o início.
Adicionar as operações de tratamento de erros em bancos de dados que já estão sendo executados em produção pode envolver séria refatoração de código e problemas de desempenho difíceis de encontrar.