No mercado atual, onde uma enorme quantidade de dados é gerada todos os dias, é muito importante entender como lidar com dados. SQL Server é um ambiente integrado desenvolvido pela Microsoft para lidar com dados. Neste artigo sobre o tutorial do SQL Server, você aprenderá todas as operações e comandos necessários para explorar seus bancos de dados.
Para sua melhor compreensão, dividi o blog nas seguintes categorias:
| Comandos | Descrição |
Comandos de linguagem de definição de dados (DDL) | Este conjunto de comandos é usado para definir um banco de dados. |
Comandos de linguagem de manipulação de dados (DML) | Os comandos de manipulação são usados para manipular os dados presentes no banco de dados. |
Comandos de linguagem de controle de dados (DCL) | Este conjunto de comandos lida com as permissões, direitos e outros controles dos sistemas de banco de dados. |
Comandos de linguagem de controle de transações (TCL) | Esses comandos são usados para lidar com a transação do banco de dados. |
Além dos comandos, os seguintes tópicos são abordados neste artigo:

- O que é SQL Server?
- Instalar o SQL Server
- Conecte-se ao SQL Server usando SSMS
- Acessar o Mecanismo de Banco de Dados
- Arquitetura do SQL Server
- Comentários em SQL
- Tipos de dados do SQL Server
- Chaves no banco de dados
- Restrições no banco de dados
- Operadores
- Funções agregadas
- Funções definidas pelo usuário
- Consultas aninhadas
- Juntas
- Ciclos
- Procedimentos armazenados
- Tratamento de exceções
***NOTA*** Neste Tutorial do SQL Server, vou considerar o banco de dados abaixo como exemplo, para mostrar como aprender e escrever comandos.
| ID do Aluno | Nome do Aluno | ParentName | PhoneNumber | Endereço | Cidade | País |
| 1 | Vihaan | Akriti Mehra | 9955339966 | Bloqueio de estrada da brigada 9 | Hyderabad | Índia |
| 2 | Manasa | Shourya Sharma | 9234568762 | Mayo Road 15 | Calcutá | Índia |
| 3 | Sim | Soumya Mishra | 9876914261 | Casa Marathalli nº 101 | Bangaluru | Índia |
| 4 | Preet | Rohan Sinha | 9765432234 | Queens Road 40 | Delhi | Índia |
| 5 | Shanaya | Abhinay Agarwal | 9878969068 | Rua Oberoi 21 | Bombaim | Índia |
Antes de começarmos a entender os diferentes comandos usados no SQL Server, vamos entender o que é o SQL Server, sua arquitetura e como instalá-lo.
O que é SQL Server?
O Microsoft SQL Server é um sistema de gerenciamento de banco de dados relacional. Ele suporta a linguagem de consulta estruturada e vem com sua própria implementação da linguagem SQL, que é o Transact-SQL(T-SQL) . Possui um ambiente integrado para lidar com bancos de dados SQL, que é o SQL Server Management Studio.
Os principais componentes do SQL Server são os seguintes:
- Mecanismo de banco de dados: Este componente lida com armazenamento, processamento rápido de transações e proteção de dados.
- SQL Server – Este serviço é usado para iniciar, parar, pausar e continuar a instância do MS SQL Server.
- SQL Server Agent – O serviço Server Agent desempenha o papel de agendador de tarefas e é acionado por qualquer evento ou conforme o requisito.
- Navegador do SQL Server – Este serviço é usado para conectar a solicitação de entrada à instância do SQL Server desejada.
- Pesquisa de texto completo do SQL Server – Usado para permitir que o usuário execute consultas de texto completo nos dados de caracteres em tabelas SQL.
- Gravador VSS do SQL Server – Permite backups e restauração de arquivos de dados quando o SQL Server não é executado.
- SQL Server Analysis Services (SSAS) – Esse serviço é usado para fornecer recursos de análise de dados, mineração de dados e aprendizado de máquina. O SQL Server também é integrado ao Python e R para análise avançada de dados.
- SQL Server Reporting Services (SSRS) – Como o nome sugere, este serviço é usado para fornecer recursos e capacidades de tomada de decisão, incluindo integração com o Hadoop.
- SQL Server Integration Services (SSIS) – Este serviço é usado para realizar as operações de ETL para diferentes tipos de dados de várias fontes de dados.
Agora que você sabe o que é o MS SQL Server, vamos avançar neste artigo sobre o tutorial do SQL Server e entender como instalar e configurar o SQL Server.
Instalar o SQL Server
Siga as etapas abaixo para instalar o SQL Server:
Etapa 1: Vá para a página oficial do download do Microsoft SQL Server , onde você encontrará a opção de instalar o SQL Server no local ou na nuvem.
Etapa 2: Agora, role para baixo e você verá duas opções: Developer &Enterprise Edition . Aqui, farei o download da edição do desenvolvedor . Para baixar, basta clicar no botão Baixar agora opção. Consulte abaixo.
Etapa 3: Após o download do aplicativo, clique duas vezes no arquivo e você verá a seguinte janela.
Etapa 4: Agora, você pode escolher uma das 3 opções para configurar o SQL Server. Aqui, escolherei apenas a opção básica . Ao selecionar a opção de tipo de instalação, a próxima tela seria aceitar o contrato de licença. Para fazer isso, clique em Aceitar na janela a seguir.
Etapa 5: Em seguida, você deve especificar o local de instalação do SQL Server. Em seguida, você deve clicar em Instalar.
Depois de clicar em Instalar , você verá que os pacotes necessários estão sendo baixados. Agora, após a conclusão da instalação, você verá a seguinte tela:
Aqui, você pode avançar e clicar em Conectar agora ou pode Personalizar a instalação. Para sua melhor compreensão, seguirei em frente e escolherei Personalizar.
Etapa 6: Depois de clicar em Personalizar na janela acima, você verá o seguinte assistente se abrindo. na janela a seguir, clique em Próximo.
Etapa 7: Depois que as regras forem instaladas automaticamente, clique em Avançar . Consulte abaixo.
Etapa 8: Em seguida, você deve escolher o tipo de instalação. Portanto, escolha a opção Executar uma nova instalação do SQL Server 2017 opção e clique em Avançar.
Etapa 9: No assistente que se abre, escolha a edição:Desenvolvedor. Em seguida, clique em Próximo . Consulte abaixo.
Etapa 10: Agora, leia e aceite os contratos de licença fazendo check-in no botão de opção e clique em Próximo . Consulte abaixo.
Etapa 11: No assistente abaixo, você pode escolher os recursos que deseja instalar. Além disso, você pode escolher o diretório raiz da instância e clicar em Próximo . Aqui, escolherei os Serviços do Mecanismo de Banco de Dados .
Etapa 12: Em seguida, você deve nomear a instância e automaticamente o ID da instância será criado. Aqui, vou nomear a instância “edureka”. Em seguida, clique em Próximo.
Etapa 13: No assistente de configuração do servidor, clique em Avançar .
Etapa 14: Agora, você precisa habilitar os modos de autenticação. Aqui, você verá o modo de autenticação do Windows e Modo misto . Eu vou escolher o Modo Misto. Em seguida, mencione a senha e adicionarei o usuário atual como Admin escolhendo a opção Adicionar usuário atual opção.
Etapa 15: Em seguida, escolha o caminho do arquivo de configuração e clique em Instalar .
Após a conclusão da instalação, você verá a seguinte tela:
Conecte-se ao SQL Server usando SSMS
Após a instalação do SQL Server, sua próxima etapa é conectar o SQL Server ao SQL Server Management Studio. Para isso siga os passos abaixo:
Etapa 1: Volte para a janela a seguir e clique no botão instalar SSMS opção.
Etapa 2: Depois de clicar nessa opção, você será redirecionado para a página a seguir, onde deverá escolher Baixar SSMS.
Etapa 3: Após o download da configuração, clique duas vezes no aplicativo e você verá o seguinte assistente se abrindo.
Etapa 4: Clique na opção Instalar , na janela acima e você verá que essa instalação começará.
Etapa 5: Após a conclusão da instalação, você receberá uma caixa de diálogo conforme mostrado abaixo.
Depois de instalar o SSMS, a próxima etapa é acessar o Database Engine .
Acessando o Mecanismo de Banco de Dados
Quando você abre o estúdio de gerenciamento de servidor SQL no menu iniciar , uma janela será aberta semelhante à janela mostrada na figura abaixo.
Aqui, mencione o Nome do Servidor, Modo de Autenticação e clique em Conectar.
Depois de clicar em Conectar , Você verá a seguinte tela.
Bem pessoal, é assim que você instala e configura o SQL Server. Agora, avançando neste tutorial do SQL Server, vamos entender os diferentes componentes da arquitetura do SQL Server.
Arquitetura do SQL Server
A arquitetura do SQL Server é a seguinte:
- Servidor − É aqui que os serviços SQL são instalados e o banco de dados reside
- Mecanismo Relacional − Contém o analisador de consultas, o otimizador e o executor; e a execução acontece no mecanismo relacional.
- Analisador de Comando − Verifica a sintaxe da consulta e converte a consulta em linguagem de máquina.
- Otimizador − Prepara o plano de execução como saída tomando estatísticas, consulta e árvore do Algebrator como entrada.
- Executor de consultas − Este é o local onde as consultas são executadas passo a passo
- Mecanismo de armazenamento − Este é responsável pelo armazenamento e recuperação de dados no sistema de armazenamento, manipulação de dados, gerenciamento e bloqueio de transações.
Agora que você sabe como configurar e instalar o SQL Server e seus vários componentes, vamos começar a escrever comandos no SQL Server. Mas, antes disso, deixe-me falar sobre como escrever comentários no SQL Server.
Comentários no SQL Server
Existem duas maneiras de comentar em SQL, ou seja, usar os s comentários de linha única ou o m comentários de última linha .
Comentários de linha única
Os comentários de linha única começam com dois hífens (–). Assim, o texto mencionado após (–), até o final de uma única linha, será ignorado pelo compilador.
Exemplo:
--Example of single line comments
Comentários de várias linhas
Os comentários de várias linhas começam com /* e terminam com */ . Portanto, o texto mencionado entre /* e */ será ignorado pelo compilador.
Exemplo:
/* Example for multi-line comments */
Agora, neste artigo sobre o tutorial do SQL Server, vamos começar com o primeiro conjunto de comandos, ou seja, comandos da Linguagem de Definição de Dados.
Comandos da linguagem de definição de dados
Esta seção do artigo lhe dará uma idéia sobre os comandos com a ajuda dos quais você pode definir seu banco de dados. Os comandos são os seguintes:
- CRIAR
- DEIXAR
- ALTER
- TRUNCAR
- RENOMEAR
CRIAR
Esta instrução é usada para criar uma tabela, banco de dados ou visualização.
A declaração "CREATE DATABASE"
Esta instrução é usada para criar um banco de dados.
Sintaxe
CREATE DATABASE DatabaseName;
Exemplo
CREATE DATABASE Students;
A declaração "CREATE TABLE"
Como o nome sugere, esta instrução é usada para criar uma tabela.
Sintaxe
CREATE TABLE TableName ( Column1 datatype, Column2 datatype, Column3 datatype, .... ColumnN datatype );
Exemplo
CREATE TABLE StudentInfo ( StudentID int, StudentName varchar(8000), ParentName varchar(8000), PhoneNumber int, AddressofStudent varchar(8000), City varchar(8000), Country varchar(8000) );
DEIXAR
Esta instrução é usada para eliminar uma tabela, banco de dados ou visualização existente.
A declaração 'DROP DATABASE'
Esta instrução é usada para eliminar um banco de dados existente. As informações completas presentes no banco de dados serão perdidas assim que você executar o comando abaixo.
Sintaxe
DROP DATABASE DatabaseName;
Exemplo
DROP DATABASE Students;
A declaração 'DROP TABLE'
Esta instrução é usada para eliminar uma tabela existente. As informações completas presentes na tabela serão perdidas assim que você executar o comando abaixo.
Sintaxe
DROP TABLE TableName;
Exemplo
DROP TABLE StudentInfo;
ALTER
O comando ALTER é usado para adicionar, excluir ou modificar colunas ou restrições em uma tabela existente.
A declaração "ALTER TABLE"
Esta instrução é usada para adicionar, excluir, modificar colunas em uma tabela pré-existente.
A declaração 'ALTER TABLE' com ADD/DROP COLUMN
A instrução ALTER TABLE é usada com o comando ADD/DROP Column para adicionar e excluir uma coluna.
Sintaxe
ALTER TABLE TableName ADD ColumnName Datatype; ALTER TABLE TableName DROP COLUMN ColumnName;
Exemplo
--ADD Column BloodGroup: ALTER TABLE StudentInfo ADD BloodGroup varchar(8000); --DROP Column BloodGroup: ALTER TABLE StudentInfo DROP COLUMN BloodGroup ;
A declaração 'ALTER TABLE' com ALTER COLUMN
A instrução ALTER TABLE pode ser usada com a coluna ALTER para alterar o tipo de dados de uma coluna existente em uma tabela.
Sintaxe
ALTER TABLE TableName ALTER COLUMN ColumnName Datatype;
Exemplo
--Add a column DOB and change the data type from date to datetime. ALTER TABLE StudentInfo ADD DOB date; ALTER TABLE StudentInfo ALTER COLUMN DOB datetime;
TRUNCAR
Este comando SQL é usado para excluir as informações presentes na tabela, mas não exclui a própria tabela. Portanto, se você deseja excluir as informações presentes na tabela, e não excluir a própria tabela, deve usar o comando TRUNCATE. Caso contrário, use o comando DROP.
Sintaxe
TRUNCATE TABLE TableName;
Exemplo
TRUNCATE TABLE StudentInfo;
RENOMEAR
Esta instrução é usada para renomear uma ou mais tabelas.
Sintaxe
sp_rename 'OldTableName', 'NewTableName';
Exemplo
sp_rename 'StudentInfo', 'Infostudents';
Continuando neste artigo sobre o tutorial do SQL Server, vamos entender os diferentes tipos de dados suportados pelo SQL Server.
Tipos de dados do SQL Server
| Categoria de tipo de dados | Nome do tipo de dados | Descrição | Intervalo/Sintaxe |
| Números exatos | numérico | Usado para armazenar valores numéricos e ter números de escala e precisão fixos | – 10^38 +1 a 10^38 – 1. |
| tinyint | Usado para armazenar valores inteiros | 0 a 255 | |
| pequeno | Usado para armazenar valores inteiros | -2^15 (-32.768) a 2^15-1 (32.767) | |
| grande | Usado para armazenar valores inteiros | -2^63 (-9.223.372.036.854.775.808) a 2^63-1 (9.223.372.036.854.775.807) | |
| int | Usado para armazenar valores inteiros | -2^31 (-2.147.483.648) a 2^31-1 (2.147.483.647) | |
| bit | Armazena um tipo de dados inteiro que contém um valor de 0, 1 ou NULL | 0, 1 ou NULL | |
| decimal | Usado para armazenar valores numéricos e ter números de escala e precisão fixos | – 10^38 +1 a 10^38 – 1. | |
| pequeno dinheiro | Usado para armazenar valores monetários ou monetários. | – 214.748,3648 a 214.748,3647 | |
| dinheiro | Usado para armazenar valores monetários ou monetários. | -922.337.203.685.477,5808 a 922.337.203.685.477,5807 (-922.337.203.685.477,58 para 922.337.203.685.477,58 para Informatica. | |
| Números aproximados | float | Usado para armazenar dados numéricos de ponto flutuante | – 1,79E+308 a -2,23E-308, 0 e 2,23E-308 a 1,79E+308 |
| real | Usado para armazenar dados numéricos de ponto flutuante | – 3,40E + 38 a -1,18E – 38, 0 e 1,18E – 38 a 3,40E + 38 | |
| Data e hora | data | Usado para definir uma data no SQL Server. | Sintaxe:data |
| smalldatetime | Usado para definir uma data que é combinada com uma hora do dia; em que a hora é baseada em um dia de 24 horas, com segundos sempre zero (:00) e sem segundos fracionários. | Sintaxe:smalldatetime | |
| datahora | Usado para definir uma data combinada com uma hora do dia com segundos fracionários com base em um relógio de 24 horas. | Sintaxe:datetime | |
| datetime2 | datetime2 é como uma extensão do datetime existente tipo que tem uma precisão fracionária padrão maior, maior intervalo de datas. | Sintaxe:datetime2 | |
| datetimeoffset | Usado para definir uma data que é combinada com uma hora do dia que tem reconhecimento de fuso horário. É baseado em um relógio de 24 horas. | Sintaxe:datetimeoffset | |
| hora | Usado para definir uma hora do dia. | Sintaxe:hora | |
| Sequências de caracteres | char | Usado para armazenar caracteres de tamanho fixo. | char [ ( n ) ] onde o valor de n varia de 1 a 8.000 |
| varchar | Usado para armazenar caracteres de comprimento variável. | varchar [ ( n | max ) ] onde o valor de n varia de 1 a 8000 e o armazenamento máximo permitido é de 2 GB. | |
| texto | Usado para armazenar dados não Unicode de comprimento variável | Comprimento máximo de string permitido – 2^31-1 (2.147.483.647) | |
| cadeias de caracteres Unicode | nchar | Usado para armazenar caracteres de tamanho fixo. | nchar [ ( n ) ] onde o valor de n varia de 1-4000 |
| nvarchar | Usado para armazenar caracteres de comprimento variável. | varchar [ ( n | max ) ] em que o valor de n varia de 1 a 4000 e o armazenamento máximo permitido é de 2 GB. | |
| ntext | Usado para armazenar dados Unicode de comprimento variável | Comprimento máximo de string permitido – 2^30-1 (2.147.483.647) | |
| Strings binárias | binário | Usado para armazenar tipos de dados binários de comprimento fixo | binário [ ( n ) ] onde o valor de n varia de 1 a 8.000 |
| varbinary | Usado para armazenar tipos de dados binários de comprimento fixo | varbinary [ ( n ) ] onde o valor n varia de 1-8000 e o armazenamento máximo permitido é de 2^31-1 bytes. | |
| imagem | Usado para armazenar dados binários de comprimento variável | 0 – 2^31-1 (2.147.483.647) bytes | |
| Outros tipos de dados | cursor | É um tipo de dados para procedimentos armazenados ou parâmetros de SAÍDA de variáveis que contêm uma referência a um cursor. | – |
| rowversion | Usado para expor números binários exclusivos gerados automaticamente em um banco de dados. | – | |
| hierarchyid | Usado para representar a posição em uma hierarquia. | – | |
| identificador único | É um GUID de 16 bytes. | Sintaxe:identificador único | |
| sql_variant | Usado para armazenar os valores de vários tipos de dados suportados pelo SQL Server | Sintaxe:sql_variant | |
| xml | Usado para armazenar o tipo de dados XML. | xml ( [ CONTEÚDO | DOCUMENTO ] xml_schemacollection ) | |
| Tipos de geometria espacial | Usado para representar dados em um sistema de coordenadas euclidianas (planas). | – | |
| Tipos de Geografia Espacial | Usado para armazenar dados elipsoidais (terra redonda), como coordenadas de latitude e longitude do GPS. | – | |
| tabela | Usado para armazenar um conjunto de resultados para processamento posterior | – |
A seguir, neste artigo vamos entender os diferentes tipos de chaves e restrições no banco de dados.
Diferentes tipos de chaves no banco de dados
A seguir estão os diferentes tipos de chaves usadas no banco de dados:
- Chave do candidato – Chave Candidata é um conjunto de atributos que podem identificar exclusivamente uma tabela. Uma tabela pode ter mais de uma chave candidata e, das chaves candidatas escolhidas, uma chave é escolhida como chave primária.
- Super Chave – O conjunto de atributos pode identificar exclusivamente uma tupla. Portanto, chaves candidatas, chaves exclusivas e chaves primárias são superchaves, mas o contrário não é verdade.
- Chave primária – As chaves primárias são usadas para identificar exclusivamente cada tupla.
- Chave alternativa – Chaves alternativas são aquelas chaves candidatas que não são escolhidas como chave primária.
- Chave exclusiva – As chaves exclusivas são semelhantes à chave primária, mas permitem um único valor NULL na coluna.
- Chave estrangeira – Um atributo que só pode receber os valores presentes como valores de algum outro atributo é a chave estrangeira do atributo ao qual se refere.
- Chave composta – As chaves compostas são uma combinação de duas ou mais colunas que identificam cada tupla de forma exclusiva.
Restrições usadas no banco de dados
Restrições são usadas em um banco de dados para especificar as regras para dados armazenados em uma tabela. Os diferentes tipos de restrições no SQL são os seguintes:
- NÃO NULO
- ÚNICO
- VERIFICAR
- PADRÃO
- ÍNDICE
NÃO NULO
A restrição NOT NULL garante que uma coluna não pode ter um valor NULL.
Exemplo
CREATE TABLE StudentsInfo ( StudentID int NOT NULL, StudentName varchar(8000) NOT NULL, ParentName varchar(8000), PhoneNumber int , AddressofStudent varchar(8000) NOT NULL, City varchar(8000), Country varchar(8000) ); --NOT NULL on ALTER TABLE ALTER TABLE StudentsInfo ALTER COLUMN PhoneNumber int NOT NULL;
ÚNICO
Essa restrição garante que todos os valores em uma coluna sejam exclusivos.
Exemplo
--UNIQUE on Create Table CREATE TABLE StudentsInfo ( StudentID int NOT NULL UNIQUE, StudentName varchar(8000) NOT NULL, ParentName varchar(8000), PhoneNumber int , AddressofStudent varchar(8000) NOT NULL, City varchar(8000), Country varchar(8000) ); --UNIQUE on Multiple Columns CREATE TABLE StudentsInfo ( StudentID int NOT NULL, StudentName varchar(8000) NOT NULL, ParentName varchar(8000), PhoneNumber int , AddressofStudent varchar(8000) NOT NULL, City varchar(8000), Country varchar(8000) CONSTRAINT UC_Student_Info UNIQUE(StudentID, PhoneNumber) ); --UNIQUE on ALTER TABLE ALTER TABLE StudentsInfo ADD UNIQUE (StudentID); --To drop a UNIQUE constraint ALTER TABLE StudentsInfo DROP CONSTRAINT UC_Student_Info;
CHECK
The CHECK constraint ensures that all the values in a column satisfy a specific condition.
Example
--CHECK Constraint on CREATE TABLE CREATE TABLE StudentsInfo ( StudentID int NOT NULL, StudentName varchar(8000) NOT NULL, ParentName varchar(8000), PhoneNumber int , AddressofStudent varchar(8000) NOT NULL, City varchar(8000), Country varchar(8000) CHECK (Country ='India') ); --CHECK Constraint on multiple columns CREATE TABLE StudentsInfo ( StudentID int NOT NULL, StudentName varchar8000) NOT NULL, ParentName varchar(8000), PhoneNumber int , AddressofStudent varchar(8000) NOT NULL, City varchar(8000), Country varchar(8000) CHECK (Country ='India' AND City = 'Hyderabad') ); --CHECK Constraint on ALTER TABLE ALTER TABLE StudentsInfo ADD CHECK (Country ='India'); --To give a name to the CHECK Constraint ALTER TABLE StudentsInfo ADD CONSTRAINT CheckConstraintName CHECK (Country ='India'); --To drop a CHECK Constraint ALTER TABLE StudentsInfo DROP CONSTRAINT CheckConstraintName;
DEFAULT
The DEFAULT constraint consists of a set of default values for a column when no value is specified.
Example
--DEFAULT Constraint on CREATE TABLE CREATE TABLE StudentsInfo ( StudentID int, StudentName varchar(8000) NOT NULL, ParentName varchar(8000), PhoneNumber int , AddressofStudent varchar(8000) NOT NULL, City varchar(8000), Country varchar(8000) DEFAULT 'India' ); --DEFAULT Constraint on ALTER TABLE ALTER TABLE StudentsInfo ADD CONSTRAINT defau_Country DEFAULT 'India' FOR Country; --To drop the Default Constraint ALTER TABLE StudentsInfo ALTER COLUMN Country DROP defau_Country;
INDEX
The INDEX constraint is used to create indexes in the table, through which you can create and retrieve data from the database very quickly.
Syntax
--Create an Index where duplicate values are allowed CREATE INDEX IndexName ON TableName (Column1, Column2, ...ColumnN); --Create an Index where duplicate values are not allowed CREATE UNIQUE INDEX IndexName ON TableName (Column1, Column2, ...ColumnN);
Example
CREATE INDEX idex_StudentName ON StudentsInfo (StudentName); --To delete an index in a table DROP INDEX StudentsInfo.idex_StudentName;
Moving forward in this article on SQL Server tutorial, let us now understand the different Data Manipulation Language commands used in Microsoft SQL Server.
Data Manipulation Language commands
This section of the article will cover all those commands through which you can manipulate the database. The commands are as follows:
- USE
- INSERT INTO
- ATUALIZAÇÃO
- EXCLUIR
- MERGE
- SELECIONAR
- CUBE
- ROLLUP
- OFFSET
- FETCH
- TOP
- PIVOT
Além desses comandos, existem também outros operadores/funções manipulativas, como:
- Operators
- Arithmetic Operators
- Assignment Operators
- Bitwise Operators
- Comparison Operators
- Compound Operators
- Logical Operators
- Scope Resolution Operators
- Set Operators
- String Concatenation Operators
- Funções agregadas
- User-Defined Functions
USE
This statement is used to select the database to start performing various operations on it.
Syntax
USE DatabaseName;
Example
USE Students;
INSERT INTO
The INSERT INTO statement is used to insert new records into an existing table.
Syntax
INSERT INTO TableName (Column1, Column2, Column3, ...,ColumnN) VALUES (value1, value2, value3, ...); --If you don't want to mention the column names then use the below syntax INSERT INTO TableName VALUES (Value1, Value2, Value3, ...);
Example
INSERT INTO StudentsInfo(StudentID, StudentName, ParentName, PhoneNumber, AddressofStudent, City, Country)
VALUES ('06', 'Sanjana','Kapoor', '9977331199', 'Buffalo Street House No 10', 'Kolkata', 'India');
INSERT INTO StudentsInfo
VALUES ('07', 'Vishal','Mishra', '9876509712', 'Nice Road 15', 'Pune', 'India');
ATUALIZAÇÃO
The UPDATE statement is used to modify or update the records already present in the table.
Syntax
UPDATE TableName SET Column1 = Value1, Column2 = Value2, ... WHERE Condition;
Example
UPDATE StudentsInfo SET StudentName = 'Aahana', City= 'Ahmedabad' WHERE StudentID = 1;
DELETE
The DELETE statement is used to delete the existing records in a table.
Syntax
DELETE FROM TableName WHERE Condition;
Example
DELETE FROM StudentsInfo WHERE StudentName='Aahana';
MERGE
The MERGE statement is used to perform the INSERT, UPDATE and DELETE operations on a specific table, where the source table is provided. Consulte abaixo.
Syntax
MERGE TagretTableName USING SourceTableName ON MergeCondition WHEN MATCHED THEN Update_Statement WHEN NOT MATCHED THEN Insert_Statement WHEN NOT MATCHED BY SOURCE THEN DELETE;
Example
To understand the MERGE statement, consider the following tables as the Source table and the Target table.
Source Table:
| StudentID | StudentName | Marks |
| 1 | Vihaan | 87 |
| 2 | Manasa | 92 |
| 4 | Anay | 74 |
Target Table:
| StudentID | StudentName | Marks |
| 1 | Vihaan | 87 |
| 2 | Manasa | 67 |
| 3 | Saurabh | 55 |
MERGE SampleTargetTable TARGET USING SampleSourceTable SOURCE ON (TARGET.StudentID = SOURCE.StudentID) WHEN MATCHED AND TARGET.StudentName <> SOURCE.StudentName OR TARGET.Marks <> SOURCE.Marks THEN UPDATE SET TARGET.StudentName = SOURCE.StudentName, TARGET.Marks = SOURCE.Marks WHEN NOT MATCHED BY TARGET THEN INSERT (StudentID,StudentName,Marks) VALUES (SOURCE.StudentID,SOURCE.StudentName,SOURCE.Marks) WHEN NOT MATCHED BY SOURCE THEN DELETE;
Output
| StudentID | StudentName | Marks |
| 1 | Vihaan | 87 |
| 2 | Manasa | 92 |
| 4 | Anay | 74 |
SELECT
The SELECT statement is used to select data from a database, table or view. The data returned is stored in a result table, called the result-set .
Syntax
SELECT Column1, Column2, ...ColumN FROM TableName; --(*) is used to select all from the table SELECT * FROM table_name; -- To select the number of records to return use: SELECT TOP 3 * FROM TableName;
Example
-- To select few columns SELECT StudentID, StudentName FROM StudentsInfo; --(*) is used to select all from the table SELECT * FROM StudentsInfo; -- To select the number of records to return use: SELECT TOP 3 * FROM StudentsInfo;
We can also use the following keywords with the SELECT statement:
- DISTINTO
- ORENDER POR
- GRUPO POR
- GROUPING SETS
- Cláusula HAVING
- INTO
DISTINCT
The DISTINCT keyword is used with the SELECT statement to return only different values.
Syntax
SELECT DISTINCT Column1, Column2, ...ColumnN FROM TableName;
Example
SELECT DISTINCT PhoneNumber FROM StudentsInfo;
ORDER BY
This statement is used to sort the required results either in the ascending or descending order. By default, the results are stored in ascending order. Yet, if you wish to get the results in descending order, you have to use the DESC palavra-chave.
Syntax
SELECT Column1, Column2, ...ColumnN FROM TableName ORDER BY Column1, Column2, ... ASC|DESC;
Example
-- Select all students from the 'StudentsInfo' table sorted by ParentName: SELECT * FROM StudentsInfo ORDER BY ParentName; -- Select all students from the 'StudentsInfo' table sorted by ParentName in Descending order: SELECT * FROM StudentsInfo ORDER BY ParentName DESC; -- Select all students from the 'StudentsInfo' table sorted by ParentName and StudentName: SELECT * FROM StudentsInfo ORDER BY ParentName, StudentName; /* Select all students from the 'StudentsInfo' table sorted by ParentName in Descending order and StudentName in Ascending order: */ SELECT * FROM StudentsInfo ORDER BY ParentName ASC, StudentName DESC;
GROUP BY
Esta instrução é usada com as funções agregadas para agrupar o conjunto de resultados por uma ou mais colunas.
Syntax
SELECT Column1, Column2,..., ColumnN FROM TableName WHERE Condition GROUP BY ColumnName(s) ORDER BY ColumnName(s);
Example
-- To list the number of students from each city. SELECT COUNT(StudentID), City FROM StudentsInfo GROUP BY City;
GROUPING SETS
GROUPING SETS were introduced in SQL Server 2008, used to generate a result-set that can be generated by a UNION ALL of the multiple simple GROUP BY clauses.
Syntax
SELECT ColumnNames(s) FROM TableName GROUP BY GROUPING SETS(ColumnName(s));
Example
SELECT StudentID, StudentName, COUNT(City) from StudentsInfo Group BY GROUPING SETS ((StudentID, StudentName, City),(StudentID),(StudentName),(City));
HAVING
This clause is used in the scenario where the WHERE keyword cannot be used.
Syntax
SELECT ColumnName(s) FROM TableName WHERE Condition GROUP BY ColumnName(s) HAVING Condition ORDER BY ColumnName(s);
Example
SELECT COUNT(StudentID), City FROM StudentsInfo GROUP BY City HAVING COUNT(StudentID) > 2 ORDER BY COUNT(StudentID) DESC;
INTO
The INTO keyword can be used with the SELECT statement to copy data from one table to another. Well, you can understand these tables to be temporary tables. The temporary tables are generally used to perform manipulations on data present in the table, without disturbing the original table.
Syntax
SELECT * INTO NewTable [IN ExternalDB] FROM OldTable WHERE Condition;
Example
-- To create a backup of table 'StudentsInfo' SELECT * INTO StudentsBackup FROM StudentsInfo; --To select only few columns from StudentsInfo SELECT StudentName, PhoneNumber INTO StudentsDetails FROM StudentsInfo; SELECT * INTO PuneStudents FROM StudentsInfo WHERE City = 'Pune';
CUBE
CUBE is an extension of the GROUP BY clause. It allows you to generate the sub-totals for all the combinations of the grouping columns specified in the GROUP BY clause.
Syntax
SELECT ColumnName(s) FROM TableName GROUP BY CUBE(ColumnName1, ColumnName2, ....., ColumnNameN);
Example
SELECT StudentID, COUNT(City) FROM StudentsInfo GROUP BY CUBE(StudentID) ORDER BY StudentID;
ROLLUP
ROLLUP is an extension of the GROUP BY clause. This allows you to include the extra rows which represent the subtotals. These are referred to as super-aggregated rows along with the grand total row.
Syntax
SELECT ColumnName(s) FROM TableName GROUP BY ROLLUP(ColumnName1, ColumnName2, ....., ColumnNameN);
Example
SELECT StudentID, COUNT(City) FROM StudentsInfo GROUP BY ROLLUP(StudentID);
OFFSET
The OFFSET clause is used with the SELECT and ORDER BY statement to retrieve a range of records. It must be used with the ORDER BY clause since it cannot be used on its own. Also, the range that you mention must be equal to or greater than 0. If you mention a negative value, then it shows an error.
Syntax
SELECT ColumnNames) FROM TableName WHERE Condition ORDER BY ColumnName(s) OFFSET RowsToSkip ROWS;
Example
Consider a new column Marks in the StudentsInfo tabela.
SELECT StudentName, ParentName FROM StudentsInfo ORDER BY Marks OFFSET 1 ROWS;
FETCH
The FETCH clause is used to return a set of a number of rows. It has to be used in conjunction with the OFFSET clause.
Syntax
SELECT ColumnNames) FROM TableName WHERE Condition ORDER BY ColumnName(s) OFFSET RowsToSkip FETCH NEXT NumberOfRows ROWS ONLY;
Example
SELECT StudentName, ParentName FROM StudentsInfo ORDER BY Marks OFFSET 1 ROWS FETCH NEXT 1 ROWS ONLY;
TOP
The TOP clause is used with the SELECT statement to mention the number of records to return.
Syntax
SELECT TOP Number ColumnName(s) FROM TableName WHERE Condition;
Example
SELECT TOP 3 * FROM StudentsInfo;
PIVOT
PIVOT is used to rotate the rows to column values and runs aggregations when required on the remaining column values.
Syntax
SELECT NonPivoted ColumnName,
[First Pivoted ColumnName] AS ColumnName,
[Second Pivoted ColumnName] AS ColumnName,
[Third Pivoted ColumnName] AS ColumnName,
...
[Last Pivoted ColumnName] AS ColumnName
FROM
(SELECT query which produces the data)
AS [alias for the initial query]
PIVOT
(
[AggregationFunction](ColumName)
FOR
[ColumnName of the column whose values will become column headers]
IN ( [First Pivoted ColumnName], [Second Pivoted ColumnName], [Third Pivoted ColumnName]
... [last pivoted column])
) AS [alias for the Pivot Table]; Example
To get a detailed example, you can refer to my article on SQL PIVOT and UNPIVOT. Next in this SQL Server Tutorial let us look into the different operators supported by Microsoft SQL Server.
Operators
The different types of operators supported by SQL Server are as follows:
- Arithmetic Operators
- Assignment Operators
- Bitwise Operators
- Comparison Operators
- Compound Operators
- Logical Operators
- Scope Resolution Operators
- Set Operators
- String Concatenation Operators
Let us discuss each one of them one by one.
Arithmetic Operators
| Operator | Meaning | Syntax |
+ | Addition | expression + expression |
– | Subtraction | expression – expression |
* | Multiplication | expression * expression |
/ | Divison | expression / expression |
% | Modulous | expression % expression |
Assignment Operators
| Operator | Meaning | Syntax |
= | Assign a value to a variable | variable =‘value’ |
Bitwise Operators
| Operator | Meaning | Syntax |
&(Bitwise AND) | Used to perform a bitwise logical AND operation between two integer values. | expression &expression |
&=(Bitwise AND Assignment) | Used to perform a bitwise logical AND operation between two integer values. It also sets a value to the output of the operation. | expression &=expression |
| (Bitwise OR) | Used to perform a bitwise logical OR operation between two integer values as translated to binary expressions within Transact-SQL statements. | expression | expressão |
|=(Bitwise OR Assignment) | Used to perform a bitwise logical OR operation between two integer values as translated to binary expressions within Transact-SQL statements. It also sets a value to the output of the operation. | expression |=expression |
^ (Bitwise Exclusive OR) | Used to perform a bitwise exclusive OR operation between two integer values. | expression ^ expression |
^=(Bitwise Exclusive OR Assignment) | Used to perform a bitwise exclusive OR operation between two integer values. It also sets a value to the output of the operation. | expression ^=expression |
~ (Bitwise NOT) | Used to perform a bitwise logical NOT operation on an integer value. | ~ expression |
Comparison Operators
| Operator | Meaning | Syntax |
= | Equal to | expression =expression |
> | Greater than | expression> expression |
< | Less than | expression |
>= | Greater than or equal to | expression>=expression |
<= | Less than or equal to | expression <=expression |
<> | Not equal to | expression <> expression |
!= | Not equal to | expression !=expression |
!< | Not less than | expression ! |
!> | Not greater than | expression !> expression |
Compound Operators
| Operator | Meaning | Syntax |
+ = | Used to add value to the original value and set the original value to the result. | expression +=expression |
-= | Used to subtract a value from the original value and set the original value to the result. | expression -=expression |
*= | Used to multiply value to the original value and set the original value to the result. | expression *=expression |
/= | Used to divide a value from the original value and set the original value to the result. | expression /=expression |
%= | Used to divide a value from the original value and set the original value to the result. | expression %=expression |
&= | Used to perform a bitwise AND operation and set the original value to the result. | expression &=expression |
^= | Used to perform a bitwise exclusive OR operation and set the original value to the result. | expression ^=expression |
|= | Used to perform a bitwise OR operation and set the original value to the result. | expression |=expression |
Logical Operators
| Operator | Meaning | Syntax |
ALL | Returns TRUE if all of set of comparisons are TRUE. | scalar_expression { =| <> | !=|> |>=| !> | <| <=| !<} ALL ( subquery ) |
AND | Returns TRUE if both the expressions are TRUE. | boolean_expression AND boolean_expression |
ANY | Returns TRUE if any one of a set of comparisons are TRUE. | scalar_expression { =| <> | ! =|> |> =| !> | <| <=| ! <} { ANY } ( subquery ) |
BETWEEN | Returns TRUE if an operand is within a range. | sampleexpression [ NOT ] BETWEEN beginexpression AND endexpression |
EXISTS | Returns TRUE if a subquery contains any rows. | EXISTS (sub query) |
IN | Returns TRUE if an operand is equal to one of a list of expressions. | test_expression [ NOT ] IN( subquery | expression [ ,…n ]) |
LIKE | Returns TRUE if an operand matches a pattern. | match_expression [ NOT ] LIKE pattern [ ESCAPE escape_character ] |
NOT | Reverses the value of any boolean operator. | [ NOT ] boolean_expression |
OR | Returns TRUE if either of the boolean expression is TRUE. | boolean_expression OR boolean_expression |
SOME | Returns TRUE if some of a set of comparisons are TRUE. | scalar_expression { =| <> | ! =|> |> =| !> | <| <=| ! <} { SOME} ( subquery ) |
Scope Resolution Operators
| Operator | Meaning | Example |
:: | Provides access to static members of a compound data type. Compound data types are those data types which contain multiple methods and simple data types. Compound data types These include the built-in CLR types and custom SQLCLR User-Defined Types (UDTs). | DECLARE @hid hierarchyid; SELECT @hid =hierarchyid::GetRoot(); PRINT @hid.ToString(); |
Set Operators
Existem principalmente três operações de conjunto:UNION, INTERSECT, MINUS. Você pode consultar a imagem abaixo para entender as operações de conjunto no SQL. Consulte a imagem abaixo:
| Operator | Meaning | Syntax |
UNION | The UNION operator is used to combine the result-set of two or more SELECT statements. | SELECT ColumnName(s) FROM Table1 UNIÃO SELECT ColumnName(s )FROM Table2; |
INTERSECT | The INTERSECT clause is used to combine two SELECT statements and return the intersection of the data-sets of both the SELECT statements. | SELECT Column1 , Column2 …. FROM TableName; WHERE Condition INTERSECT SELECT Column1 , Column2 …. FROM TableName; WHERE Condition |
EXCEPT | The EXCEPT operator returns those tuples that are returned by the first SELECT operation, and are not returned by the second SELECT operation. | SELECT ColumnName FROM TableName; EXCETO SELECT ColumnName FROM TableName; |
String Operators
| Operator | Meaning | Syntax/ Example |
+ (String Concatenation) | Concatenates two or more binary or character strings, columns, or a combination of strings and column names into a single expression | expression+expression |
+=(String Concatenation) | Used to concatenate two strings and sets the string to the result of the operation. | expression+=expression |
% (Wildcard Characters to match) | Used to matches any string of zero or more characters. | Example:‘sample%’ |
[] (Wildcard Characters to match) | Used to match a single character within the specified range or set that is specified between brackets []. | Example:m[n-z]%’ |
[^] (Wildcard Characters to match) | Used to match a single character which is not within the range or set specified between the square brackets. | Example:‘Al[^a]%’ |
_ (Wildcard Characters to match) | Used to match a single character in a string comparison operation | test_expression [ NOT ] IN( subquery | expression [ ,…n ]) |
Aggregate Functions
The different aggregate functions supported by SQL Server are as follows:
| Function | Description | Syntax | Example |
SUM() | Used to return the sum of a group of values. | SELECT SUM(ColumnName) FROM TableName; | SELECT SUM(Marks) FROM StudentsInfo; |
COUNT() | Returns the number of rows either based on a condition, or without a condition. | SELECT COUNT(ColumnName) FROM TableName WHERE Condition; | SELECT COUNT(StudentID) FROM StudentsInfo; |
AVG() | Used to calculate the average value of a numeric column. | SELECT AVG(ColumnName) FROM TableName; | SELECT AVG(Marks) FROM StudentsInfo; |
MIN() | This function returns the minimum value of a column. | SELECT MIN(ColumnName) FROM TableName; | SELECT MIN(Marks) FROM StudentsInfo; |
MAX() | Returns a maximum value of a column. | SELECT MAX(ColumnName) FROM TableName; | SELECT MAX(Marks) FROM StudentsInfo; |
FIRST() | Used to return the first value of the column. | SELECT FIRST(ColumnName) FROM TableName; | SELECT FIRST(Marks) FROM StudentsInfo; |
LAST() | This function returns the last value of the column. | SELECT LAST(ColumnName) FROM TableName; | SELECT LAST(Marks) FROM StudentsInfo; |
User-Defined Functions
Microsoft SQL Server allows the users to create user-defined functions which are routines. These routines accept parameters, can perform simple to complex actions and return the result of that particular action as a value. Here, the value returned can either be a single scalar value or a complete result-set.
You can use user-defined functions to:
- Allow modular programming
- Reduce network traffic
- Allow faster execution of queries
Also, there are different types of user-defined functions you can create. Eles estão:
- Scalar Functions: Used to return a single data value of the type defined in the RETURNS clause.
- Table-Valued Functions: Used to return a table data type.
- System Functions: A variety of system functions are provided by the SQL Server to perform different operations.
Well, apart from the user-defined functions, there is a bunch of in-built functions in SQL Server; which can be used to perform a variety of tasks. Moving on in this article on SQL Server tutorial, let us now understand what are nested queries.
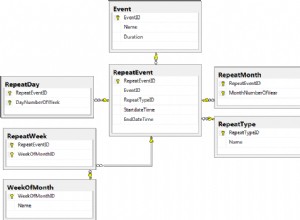
Nested Queries
Nested queries are those queries that have an outer query and inner subquery. So, basically, the subquery is a query which is nested within another query such as SELECT, INSERT, UPDATE or DELETE. Refer to the image below:
Next in this SQL Server tutorial, let us understand the different types of joins in SQL.
Joins
Joins are used to combine tuples from two or more tables, based on a related column between the tables. There are four types of joins:
- INNER JOIN: Returns records that have matching values in both the tables.
- LEFT JOIN: Returns records from the left table, and also those records which satisfy the condition from the right table.
- RIGHT JOIN: Returns records from the right table, and also those records which satisfy the condition from the left table.
- FULL JOIN: Returns records which either have a match in the left or the right table.
Consider the following table along with the StudentsInfo table, to understand the syntax of joins.
| SubjectID | StudentID | SubjectName |
| 10 | 10 | Maths |
| 2 | 11 | Physics |
| 3 | 12 | Chemistry |
INNER JOIN
Syntax
SELECT ColumnName(s) FROM Table1 INNER JOIN Table2 ON Table1.ColumnName = Table2.ColumnName;
Example
SELECT Subjects.SubjectID, StudentsInfo.StudentName FROM Subjects INNER JOIN StudentsInfo ON Subjects.StudentID = StudentsInfo.StudentID;
LEFT JOIN
Syntax
SELECT ColumnName(s) FROM Table1 LEFT JOIN Table2 ON Table1.ColumnName = Table2.ColumnName;
Example
SELECT StudentsInfo.StudentName, Subjects.SubjectID FROM StudentsInfo LEFT JOIN Subjects ON StudentsInfo.SubjectID = Subjects.SubjectID ORDER BY StudentsInfo.StudentName;
RIGHT JOIN
Syntax
SELECT ColumnName(s) FROM Table1 RIGHT JOIN Table2 ON Table1.ColumnName = Table2.ColumnName;
Example
SELECT StudentsInfo.StudentName, Subjects.SubjectID FROM StudentsInfo RIGHT JOIN Subjects ON StudentsInfo.SubjectID = Subjects.SubjectID ORDER BY StudentsInfo.StudentName;
FULL JOIN
Syntax
SELECT ColumnName(s) FROM Table1 FULL OUTER JOIN Table2 ON Table1.ColumnName = Table2.ColumnName;
Example
SELECT StudentsInfo.StudentName, Subjects.SubjectID FROM StudentsInfo FULL OUTER JOIN Subjects ON StudentsInfo.SubjectID = Subjects.SubjectID ORDER BY StudentsInfo.StudentName;
Next, in this article on SQL Server tutorial, let us understand the different types of loops supported by the SQL Server.
Loops
The different control-of-flow commands are as follows:
- BEGIN..END
- BREAK
- CONTINUE
- GOTO
- IF..ELSE
- RETURN
- WAITFOR
- WHILE
Let us discuss each one of them one by one.
BEGIN..END
These keywords are used to enclose a series of SQL statements. Then, this group of SQL statements can be executed.
Syntax
BEGIN
{ SQLStatement | StatementBlock }
END
BREAK
This statement is used to exit the current WHILE loop. In case, the current WHILE loop is nested inside another loop, then the BREAK statement exits only the current loop and the control is passed on to the next statement in the current loop. The BREAK statement is generally used inside an IF statement.
Syntax
BREAK;
CONTINUE
The CONTINUE statement is used to restart a WHILE loop. So, any statements after the CONTINUE keyword will be ignored.
Syntax
CONTINUE;
Here, Label is the point after which processing starts if a GOTO is targeted to that particular label.
GOTO
Used to alter the flow of execution to a label. The statements written after the GOTO keyword are skipped and processing continues at the label.
Syntax
Define Label: Label: Alter Execution: GOTO Label
Here, Label is the point after which processing starts if a GOTO is targeted to that particular label.
IF..ELSE
Like any other programming language, the If-else statement in SQL Server tests the condition and if the condition is false then ‘else’ statement is executed.
Syntax
IF BooleanExpression
{ SQLStatement | StatementBlock }
[ ELSE
{ SQLStatement | StatementBlock } ]
RETURN
Used to exit unconditionally from a query or procedure. So, the statements which are written after the RETURN clause are not executed.
Syntax
RETURN [ IntegerExpression ]
Here, an integer value is returned.
WAITFOR
The WAITFOR control flow is used to block the execution of a stored procedure, transaction or a batch until a specific statement modifies, returns at least one row or a specified time or time interval elapses.
Syntax
WAITFOR
{
DELAY 'TimeToPass'
| TIME 'TimeToExecute'
| [ ( RecieveStatement ) | ( GetConversionGroupStatement ) ]
[ , TIMEOUT timeout ]
} Onde,
- DELAY – Period of time that must pass
- TimeToPass – Period of time to wait
- TIME – The time when the stored procedure, transaction or the batch runs.
- TimeToExecute – The time at which the WAITFOR statement finishes.
- RecieveStatement – A valid RECEIVE statement.
- GetConversionGroupStatement – A valid GET CONVERSATION GROUP statement.
- TIMEOUT timeout – Specifies the period of time, in milliseconds, to wait for a message to arrive on the queue.
WHILE
This loop is used to set a condition for repeated execution of a particular SQL statement or a SQL statement block. The statements are executed as long as the condition mentioned by the user is TRUE. As soon as the condition fails, the loop stops executing.
Syntax
WHILE BooleanExpression
{ SQLStatement | StatementBlock | BREAK | CONTINUE } Now, that you guys know the DML commands, let’s move onto our next section in this article on SQL Tutorial i.e. the DCL commands.
Data Control Language Commands (DCL)
This section of SQL Server tutorial will give you an idea about the command through which are used to enforce database security in multiple user database environments. The commands are as follows:
- GRANT
- REVOKE
GRANT
The GRANT command is used to provide access or privileges on the database and its objects to the users.
Syntax
GRANT PrivilegeName
ON ObjectName
TO {UserName |PUBLIC |RoleName}
[WITH GRANT OPTION]; Onde,
- PrivilegeName – Is the privilege/right/access granted to the user.
- ObjectName – Name of a database object like TABLE/VIEW/STORED PROC.
- UserName – Name of the user who is given the access/rights/privileges.
- PUBLIC – To grant access rights to all users.
- RoleName – The name of a set of privileges grouped together.
- WITH GRANT OPTION – To give the user access to grant other users with rights.
Example
-- To grant SELECT permission to StudentsInfo table to user1 GRANT SELECT ON StudentsInfo TO user1;
REVOKE
The REVOKE command is used to withdraw the user’s access privileges given by using the GRANT command.
Syntax
REVOKE PrivilegeName
ON ObjectName
FROM {UserName |PUBLIC |RoleName} Example
-- To revoke the granted permission from user1 REVOKE SELECT ON StudentsInfo TO user1;
Moving on in this SQL Server tutorial, let us understand the how to create and use Stored Procedures.
Stored Procedures
Stored Procedures are reusable units that encapsulate a specific business logic of the application. So, it is a group of SQL statements and logic, compiled and stored together to perform a specific task.
Syntax
CREATE [ OR REPLACE] PROCEDURE procedure_name [
(parameter_name [IN | OUT | IN OUT] type [ ])]
{IS | AS }
BEGIN [declaration_section]
executable_section
//SQL statement used in the stored procedure
END
GO Example
--Create a procedure that will return a student name when the StudentId is given as the input parameter to the stored procedure Create PROCEDURE GetStudentName ( @StudentId INT, --Input parameter , @StudName VARCHAR(50) OUT --Output parameter, AS BEGIN SELECT @StudName = StudentName FROM StudentsInfo WHERE StudentID=@StudentId END
Passos para executar:
- Declare @StudName as nvarchar(50)
- EXEC GetStudentName 01, @StudName output
- SELECT @StudName
The above procedure returns the name of a particular student, on giving that students id as input. Next in this SQL Server tutorial, let us understand the transaction control language commands.
Transaction Control Language Commands (TCL)
This section of SQL Server tutorial will give you an insight into the commands which are used to manage transactions in the database. The commands are as follows:
- COMMIT
- ROLLBACK
- SAVEPOINT
COMMIT
The COMMIT command is used to save the transaction into the database.
Syntax
COMMIT;
ROLLBACK
The ROLLBACK command is used to restore the database to the last committed state.
Syntax
ROLLBACK;
OBSERVAÇÃO: When you use ROLLBACK with SAVEPOINT, then you can directly jump to a savepoint in an ongoing transaction. Syntax:ROLLBACK TO SavepointName;
SAVEPOINT
The SAVEPOINT command is used to temporarily save a transaction. So if you wish to rollback to any point, then you can save that point as a ‘SAVEPOINT’.
Syntax
SAVEPOINT SAVEPOINTNAME;
Consider the below table to understand the working of transactions in the database.
| StudentID | StudentName |
| 1 | Rohit |
| 2 | Suhana |
| 3 | Ashish |
| 4 | Prerna |
Now, use the below SQL queries to understand the transactions in the database.
INSERT INTO StudentTable VALUES(5, 'Avinash'); COMMIT; UPDATE StudentTable SET name = 'Akash' WHERE id = '5'; SAVEPOINT S1; INSERT INTO StudentTable VALUES(6, 'Sanjana'); SAVEPOINT S2; INSERT INTO StudentTable VALUES(7, 'Sanjay'); SAVEPOINT S3; INSERT INTO StudentTable VALUES(8, 'Veena'); SAVEPOINT S4; SELECT * FROM StudentTable;
Next in this article on SQL Server tutorial let us understand how to handle exceptions in Transact-SQL.
Exception Handling
There are two types of exceptions, i.e, the system-defined exceptions and the user-defined exceptions. As the name suggests, exception handling is a process through which a user can handle the exceptions generated. To handle exceptions you have to understand the following control flow statements:
- THROW
- TRY…CATCH
THROW
This clause is used to raise an exception and transfers the execution to a CATCH block of a TRY…CATCH construct.
Syntax
THROW [ { ErrorNumber | @localvariable },
{ Message | @localvariable },
{ State | @localvariable } ]
[ ; ] Onde,
- ErrorNumber – A constant or variable that represents the exception.
- Message – A variable or string that describes the exception.
- State – A constant or variable between 0 and 255 that indicates the state to associate with the message.
THROW 51000, 'Record does not exist.', 1;
TRY..CATCH
Used to implement exception handling in Transact-SQL. A group of statements can be enclosed in the TRY block. In case an error occurs in the TRY block, control is passed to another group of statements that are enclosed in a CATCH block.
Syntax
BEGIN TRY
{ SQLStatement | StatementBlock}
END TRY
BEGIN CATCH
[ { SQLStatement | StatementBlock } ]
END CATCH
[ ; ]
BEGIN TRY
SELECT * FROM StudentsInfo;
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErNum , ERROR_MESSAGE() AS ErMsg;
END CATCH
W ith this, we come to the end of this article on SQL Server Tutorial. I hope you enjoyed reading this article on SQL Server Tutorial For Beginners. I f you wish to get a structured training on MySQL, then check out our MySQL DBA Certification Training que vem com treinamento ao vivo conduzido por instrutor e experiência de projeto na vida real. This training will help you understand MySQL in-depth and help you achieve mastery over the subject. Got a question for us? Please mention it in the comments section of ”SQL Server Tutorial ” e entrarei em contato com você.