Desde que o ClusterControl 1.2.11 foi lançado em 2015, o MariaDB MaxScale tem suporte como um balanceador de carga de banco de dados. Ao longo dos anos, o MaxScale cresceu e amadureceu, adicionando vários recursos avançados. Recentemente, o MariaDB MaxScale 2.2 foi lançado e apresenta vários novos recursos, incluindo gerenciamento de failover de cluster de replicação.
O MariaDB MaxScale permite implantações mestre/escravo com alta disponibilidade, failover automático, alternância manual e reingresso automático. Se o mestre falhar, o MariaDB MaxScale pode promover automaticamente o escravo mais atualizado para mestre. Se o mestre com falha for recuperado, o MariaDB MaxScale pode reconfigurá-lo automaticamente como escravo para o novo mestre. Além disso, os administradores podem realizar uma alternância manual para alterar o mestre sob demanda.
Em nossos blogs anteriores, discutimos como implantar o MaxScale usando o ClusterControl, bem como implantar o MariaDB MaxScale no Docker. Para aqueles que ainda não estão familiarizados com o MariaDB MaxScale, é um proxy de banco de dados avançado e plug-in para servidores de banco de dados MariaDB. O Maxscale fica entre os aplicativos cliente e os servidores de banco de dados, roteando as consultas do cliente e as respostas do servidor. Ele também monitora os servidores, percebendo rapidamente quaisquer alterações no status do servidor ou na topologia de replicação.
Embora o Maxscale compartilhe algumas das características de outras tecnologias de balanceamento de carga, como ProxySQL, esse novo recurso de failover (que faz parte de seu mecanismo de monitoramento e detecção automática) se destaca. Neste blog, discutiremos essa nova e empolgante função do Maxscale.
Visão geral do mecanismo de failover MariaDB MaxScale
Detecção principal
Agora é menos provável que o monitor altere repentinamente o servidor mestre, mesmo que outro servidor tenha mais escravos do que o mestre atual. O DBA pode forçar uma nova seleção do mestre definindo o mestre atual como somente leitura ou removendo todos os seus escravos se o mestre estiver inativo.
Apenas um servidor pode ter o sinalizador de status Master por vez, mesmo em uma configuração multimaster. Outros servidores no grupo multimaster recebem os sinalizadores de status Relay Master e Slave.
Alternância de seleção automática do novo mestre
O comando switchover agora pode ser chamado apenas com o nome da instância do monitor como parâmetro. Nesse caso, o monitor selecionará automaticamente um servidor para promoção.
Detecção de atraso de replicação
A medição do atraso de replicação agora simplesmente lê o Seconds_Behind_Master -campo da saída de status do escravo dos escravos. O escravo calcula este valor comparando o timestamp no evento binlog que o escravo está processando no momento com o próprio relógio do escravo. Se um escravo tiver várias conexões de escravos, o menor atraso será usado.
Alternância automática após detecção de pouco espaço em disco
Com as versões recentes do MariaDB Server, o monitor agora pode verificar o espaço em disco no backend e detectar se o servidor está com pouca carga. Quando isso acontece, o monitor pode ser configurado para alternar automaticamente de um mestre com pouco espaço em disco. Os escravos também podem ser configurados para o modo de manutenção. O espaço em disco também é um fator que é considerado ao selecionar qual novo mestre promover.
Consulte switchover_on_low_disk_space e maintenance_on_low_disk_space para obter mais informações.
Recurso de redefinição de replicação
A replicação de redefinição O comando monitor exclui todas as conexões escravas e logs binários e, em seguida, configura a replicação. Útil quando os dados estão sincronizados, mas os gtids não.
Tratamento de eventos programados em Failover/Switchover/Rejoin
Os eventos do servidor iniciados pelo encadeamento do agendador de eventos agora são tratados durante as operações de modificação do cluster. Consulte handle_server_events para obter mais informações.
Suporte mestre externo
O monitor pode detectar se um servidor no cluster está replicando de um mestre externo (um servidor que não está sendo monitorado pelo monitor MaxScale). Se o servidor de replicação for o servidor mestre do cluster, o próprio cluster será considerado como tendo um mestre externo.
Se ocorrer um failover/troca, o novo servidor mestre será configurado para replicar a partir do servidor mestre externo do cluster. O nome de usuário e a senha para a replicação são definidos em replication_user e replication_password. O endereço e a porta usados são os mostrados por SHOW ALL SLAVES STATUS no servidor mestre do cluster antigo. No caso de alternância, o antigo mestre também para de replicar do servidor externo para preservar a topologia.
Após o failover, o novo mestre está replicando do mestre externo. Se o mestre antigo com falha voltar a ficar online, ele também estará replicando do servidor externo. Para normalizar a situação, ative o auto_rejoin ou execute manualmente um rejoin. Isso redirecionará o mestre antigo para o mestre de cluster atual.
Como o Failover é útil e aplicável?
O failover ajuda você a minimizar o tempo de inatividade, realizar manutenção diária ou lidar com manutenção desastrosa e indesejada que às vezes pode ocorrer em momentos infelizes. Com a capacidade do MaxScale de isolar aplicativos cliente dos servidores de banco de dados de back-end, ele adiciona funcionalidades valiosas que ajudam a minimizar o tempo de inatividade.
O plug-in de monitoramento MaxScale monitora continuamente o estado dos servidores de banco de dados de back-end. O plug-in de roteamento do MaxScale usa essas informações de status para sempre rotear consultas para servidores de banco de dados de back-end que estão em serviço. Ele pode então enviar consultas para os clusters de banco de dados de back-end, mesmo que alguns dos servidores de um cluster estejam passando por manutenção ou passando por falhas.
A alta configurabilidade do MaxScale permite que as alterações na configuração do cluster permaneçam transparentes para os aplicativos clientes. Por exemplo, se um novo servidor precisar ser adicionado ou removido administrativamente de um cluster mestre-escravo, você pode simplesmente adicionar a configuração MaxScale à lista de servidores de plug-ins de monitor e roteador por meio do console maxadmin CLI. O aplicativo cliente não terá conhecimento dessa alteração e continuará a enviar consultas de banco de dados para a porta de escuta do MaxScale.
Configurar um servidor de banco de dados em manutenção é simples e fácil. Basta fazer o seguinte comando usando maxctrl e MaxScale interromperá o envio de consultas para este servidor. Por exemplo,
maxctrl: set server DB_785 maintenance
OKEm seguida, verificando o estado dos servidores da seguinte forma,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Uma vez no modo de manutenção, o MaxScale interromperá o roteamento de novas solicitações para o servidor. Para solicitações atuais, o MaxScale não encerrará essas sessões, mas permitirá que ele conclua sua execução e não interromperá nenhuma consulta em execução enquanto estiver no modo de manutenção. Além disso, observe que o modo de manutenção não é persistente. Se o MaxScale for reiniciado quando um nó estiver no modo de manutenção, uma nova instância do MariaDB MaxScale não respeitará esse modo. Se várias instâncias MariaDB MaxScale estiverem configuradas para usar o nó, o modo de manutenção deve ser definido em cada instância MariaDB MaxScale. No entanto, se vários serviços em uma instância do MariaDB MaxScale estiverem usando o servidor, você só precisará definir o modo de manutenção uma vez no servidor para que todos os serviços anotem a alteração do modo.
Uma vez feito com sua manutenção, basta limpar o servidor com o seguinte comando. Por exemplo,
maxctrl: clear server DB_785 maintenance
OKVerificando se voltou ao normal, basta executar o comando list servers .
Você também pode aplicar determinadas ações administrativas por meio da interface do usuário do ClusterControl. Veja a captura de tela de exemplo abaixo:
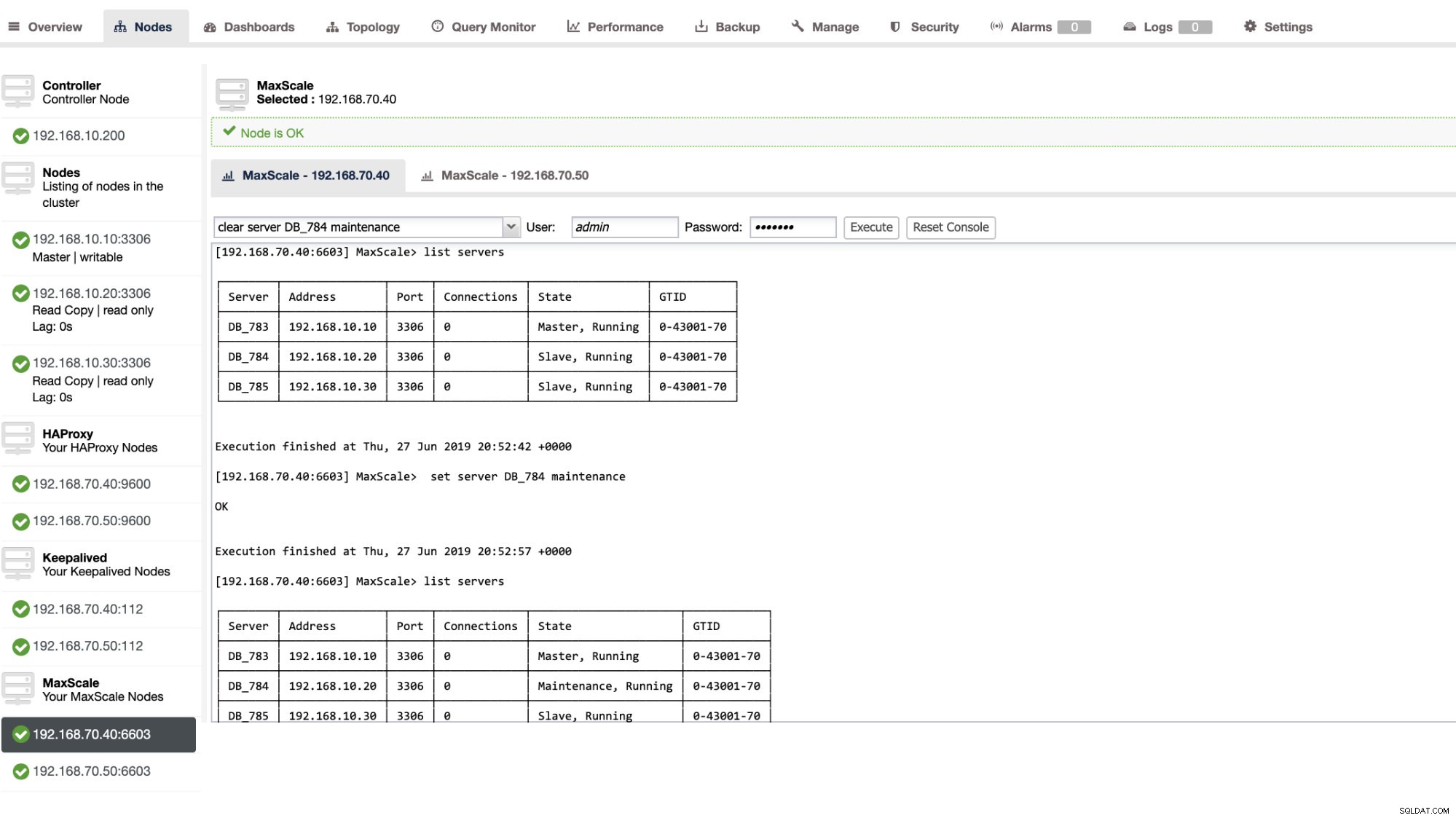
MaxScale Failover em ação
O Failover Automático
O failover MaxScale do MariaDB é executado com muita eficiência e reconfigura o escravo de acordo com o esperado. Neste teste, temos o seguinte conjunto de arquivos de configuração que foi criado e gerenciado pelo ClusterControl. Ver abaixo:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonObserve que somente o auto_failover e auto_rejoin são as variáveis que adicionei, pois o ClusterControl não adicionará isso por padrão quando você configurar um balanceador de carga MaxScale (confira este blog sobre como configurar o MaxScale usando o ClusterControl). Não esqueça que você precisa reiniciar o MariaDB MaxScale depois de aplicar as alterações em seu arquivo de configuração. Apenas corra,
systemctl restart maxscalee você está pronto para ir.
Antes de prosseguir com o teste de failover, vamos verificar primeiro a integridade do cluster:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Parece ótimo!
Matei o mestre apenas com o comando assassino puro KILL -9 $(pidof mysqld) no meu nó mestre e veja, sem surpresa, o monitor foi rápido em perceber isso e acionar o failover. Veja os logs da seguinte forma:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Agora vamos dar uma olhada na integridade do cluster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘O nó 192.168.10.10 que anteriormente era o mestre foi desativado. Tentei reiniciar e ver se o reingresso automático seria acionado e, como você notou no log no momento 2019-06-28 06:39:20.165, foi tão rápido para capturar o estado do nó e, em seguida, configurar a configuração automaticamente, sem problemas para o DBA ativá-lo.
Agora, verificando por último seu estado, parece funcionar perfeitamente como esperado. Ver abaixo:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Meu ex-mestre foi consertado e recuperado e eu quero mudar
Mudar para o seu mestre anterior também não é incômodo. Você pode operar isso com maxctrl (ou maxadmin nas versões anteriores do MaxScale) ou por meio da interface do usuário do ClusterControl (como demonstrado anteriormente).
Vamos apenas nos referir ao estado anterior da integridade do cluster de replicação anterior e desejamos alternar o 192.168.10.10 (atualmente escravo), de volta ao seu estado mestre. Antes de prosseguirmos, talvez seja necessário identificar primeiro o monitor que você usará. Você pode verificar isso com o seguinte comando abaixo:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Depois de tê-lo, você pode executar o seguinte comando abaixo para alternar:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKEm seguida, verifique novamente o estado do cluster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Parece perfeito!
Os logs mostrarão detalhadamente como foi e sua série de ações durante a transição. Veja os detalhes abaixo:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]No caso de uma troca errada, ela não prosseguirá e, portanto, gerará um erro conforme mostrado no log acima. Assim você estará seguro e sem surpresas assustadoras.
Tornando seu MaxScale altamente disponível
Embora seja um pouco fora do tópico em relação ao failover, eu queria adicionar alguns pontos valiosos aqui em relação à alta disponibilidade e como ela está relacionada ao failover MariaDB MaxScale.
Tornar seu MaxScale altamente disponível é uma parte importante no caso de seu sistema travar, ocorrer corrupção de disco ou corrupção de máquina virtual. Essas situações são inevitáveis e podem afetar o estado de sua configuração de failover automatizada quando esses ciclos de manutenção inesperados ocorrerem.
Para um ambiente do tipo cluster de replicação, isso é muito benéfico e altamente recomendado para uma configuração específica do MaxScale. O objetivo disso é que apenas uma instância MaxScale deve ter permissão para modificar o cluster a qualquer momento. Se você configurou com Keepalived, é aqui que ficam as instâncias com o status MASTER. O próprio MaxScale não conhece seu estado, mas com maxctrl (ou maxadmin nas versões anteriores) pode definir uma instância MaxScale para o modo passivo. A partir da versão 2.2.2, um MaxScale passivo se comporta de maneira semelhante a um ativo, com a diferença de que não executará failover, switchover ou rejoin. Mesmo as versões manuais desses comandos terminarão com erro. As diferenças de modo passivo/ativo podem ser expandidas no futuro, portanto, fique atento a essas alterações no MaxScale. Para fazer isso, basta fazer o seguinte:
maxctrl: alter maxscale passive true
OKVocê pode verificar isso depois executando o comando abaixo:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Se você quiser conferir como configurar altamente disponível com Keepalived, confira este post do MariaDB.
Gerenciamento de VIP
Além disso, como o MaxScale não possui tratamento VIP integrado, você pode usar o Keepalived para lidar com isso para você. Você pode apenas usar o virtual_ipaddress atribuído ao nó de estado MASTER. É provável que isso ocorra com o gerenciamento de IP virtual, assim como o MHA faz com a variável master_failover_script. Como mencionado anteriormente, confira esta postagem no blog de configuração Keepalived with MaxScale do MariaDB.
Conclusão
O MariaDB MaxScale é rico em recursos e tem muitos recursos, não apenas limitado a ser um proxy e balanceador de carga, mas também oferece o mecanismo de failover que as grandes organizações estão procurando. É quase um software de tamanho único, mas é claro que vem com limitações que um determinado aplicativo pode precisar em contraste com outros balanceadores de carga, como ProxySQL.
O ClusterControl também oferece um mecanismo de auto-failover e detecção automática mestre, além de recuperação de cluster e nó com a capacidade de implantar Maxscale e outras tecnologias de balanceamento de carga.
Cada uma dessas ferramentas tem seus diversos recursos e funcionalidades, mas o MariaDB MaxScale é bem suportado no ClusterControl e pode ser implantado de forma viável junto com Keepalived, HAProxy para ajudá-lo a acelerar sua tarefa de rotina diária.