A implantação de um cluster de banco de dados não é ciência de foguetes - há muitas instruções sobre como fazer isso. Mas como você sabe que o que acabou de implantar está pronto para produção? As implantações manuais também podem ser tediosas e repetitivas. Dependendo do número de nós no cluster, as etapas de implantação podem ser demoradas e propensas a erros. Ferramentas de gerenciamento de configuração como Puppet, Chef e Ansible são populares na implantação de infraestrutura, mas para clusters de banco de dados com estado, você precisa executar scripts significativos para lidar com a implantação de toda a pilha de alta disponibilidade do banco de dados. Além disso, o modelo/módulo/livro de receitas/função escolhido deve ser meticulosamente testado antes que você possa confiar nele como parte da automação de sua infraestrutura. As alterações de versão exigem que os scripts sejam atualizados e testados novamente.
A boa notícia é que o ClusterControl automatiza as implementações de toda a pilha - e de graça também! Implementamos milhares de clusters de produção e tomamos várias precauções para garantir que estejam prontos para a produção. Diferentes topologias são suportadas, desde a replicação mestre-escravo até o cluster Galera, NDB e InnoDB, com diferentes proxies de banco de dados no topo.
Uma pilha de alta disponibilidade, implantada por meio do ClusterControl, consiste em três camadas:
- Camada de banco de dados (por exemplo, Galera Cluster)
- Camada de proxy reverso (por exemplo, HAProxy ou ProxySQL)
- Camada Keepalived, que, com uso de IP Virtual, garante alta disponibilidade da camada proxy
Neste blog, mostraremos como implantar um Galera Cluster de nível de produção completo com balanceadores de carga para configuração de alta disponibilidade. A configuração completa consiste em 6 hosts:
- 1 host - ClusterControl (implantação, monitoramento, servidor de gerenciamento)
- 3 hosts - MySQL Galera Cluster
- 2 hosts - proxies reversos atuam como balanceadores de carga na frente do cluster.
O diagrama a seguir ilustra nosso resultado final após a conclusão da implantação:
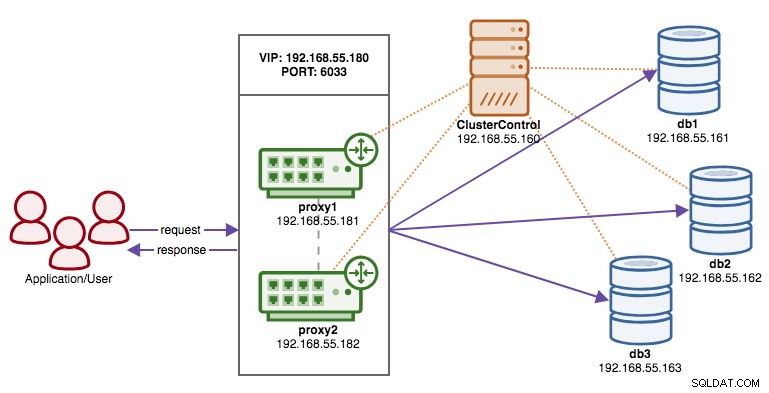
Pré-requisitos
ClusterControl deve residir em um nó independente que não faça parte do cluster. Faça o download do ClusterControl e a página gerará uma licença exclusiva para você e mostrará as etapas para instalar o ClusterControl:
$ wget -O install-cc https://severalnines.com/scripts/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userSiga as instruções onde você será guiado com a configuração do servidor MySQL, senha raiz do MySQL no nó ClusterControl, senha cmon para uso do ClusterControl e assim por diante. Você deve obter a seguinte linha quando a instalação for concluída:
Determining network interfaces. This may take a couple of minutes. Do NOT press any key.
Public/external IP => https://{public_IP}/clustercontrol
Installation successful. If you want to uninstall ClusterControl then run install-cc --uninstall.Em seguida, no servidor ClusterControl, gere uma chave SSH que usaremos para configurar o SSH sem senha posteriormente. Você pode usar qualquer usuário no sistema, mas deve ter a capacidade de executar operações de superusuário (sudoer). Neste exemplo, escolhemos o usuário root:
$ whoami
root
$ ssh-keygen -t rsaConfigure o SSH sem senha para todos os nós que você gostaria de monitorar/gerenciar via ClusterControl. Nesse caso, configuraremos isso em todos os nós da pilha (incluindo o próprio nó ClusterControl). No nó ClusterControl, execute os seguintes comandos e especifique a senha de root quando solicitado:
$ ssh-copy-id example@sqldat.com # clustercontrol
$ ssh-copy-id example@sqldat.com # galera1
$ ssh-copy-id example@sqldat.com # galera2
$ ssh-copy-id example@sqldat.com # galera3
$ ssh-copy-id example@sqldat.com # proxy1
$ ssh-copy-id example@sqldat.com # proxy2Você pode verificar se está funcionando executando o seguinte comando no nó ClusterControl:
$ ssh example@sqldat.com "ls /root"Certifique-se de que consegue ver o resultado do comando acima sem a necessidade de digitar a senha.
Implantando o cluster
ClusterControl suporta todos os fornecedores de Galera Cluster (Codership, Percona e MariaDB). Existem algumas pequenas diferenças que podem influenciar sua decisão de escolher o fornecedor. Se você quiser aprender sobre as diferenças entre eles, confira nossa postagem anterior no blog - Galera Cluster Comparison - Codership vs Percona vs MariaDB.
Para implantação de produção, um Galera Cluster de três nós é o mínimo que você deve ter. Você sempre pode dimensioná-lo mais tarde, depois que o cluster for implantado, manualmente ou por meio do ClusterControl. Abriremos nossa interface do usuário do ClusterControl em https://192.168.55.160/clustercontrol e criaremos o primeiro usuário administrador. Em seguida, vá para o menu superior e clique em Implantar -> MySQL Galera e você verá a seguinte caixa de diálogo:
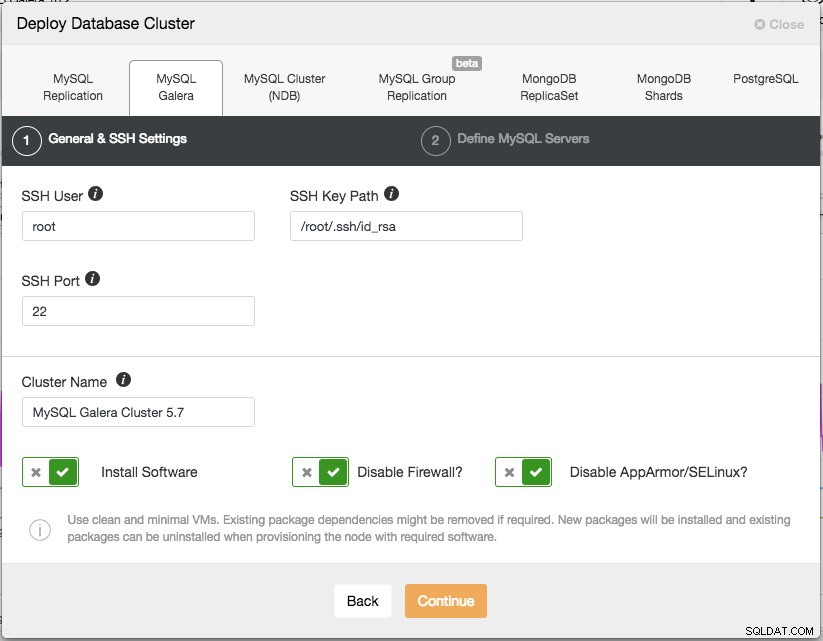
Existem duas etapas, a primeira é as "Configurações gerais e SSH". Aqui precisamos configurar o usuário SSH que o ClusterControl deve usar para se conectar aos nós do banco de dados, juntamente com o caminho para a chave SSH (conforme gerado na seção Pré-requisitos), bem como a porta SSH dos nós do banco de dados. O ClusterControl presume que todos os nós do banco de dados estão configurados com o mesmo usuário, chave e porta SSH. Em seguida, dê um nome ao cluster, neste caso usaremos "MySQL Galera Cluster 5.7". Este valor pode ser alterado posteriormente. Em seguida, selecione as opções para instruir o ClusterControl a instalar o software necessário, desativar o firewall e também desativar o módulo de aprimoramento de segurança na distribuição Linux específica. Recomenda-se que todos eles sejam ativados para maximizar o potencial de implantação bem-sucedida.
Clique em Continuar e você verá a seguinte caixa de diálogo:
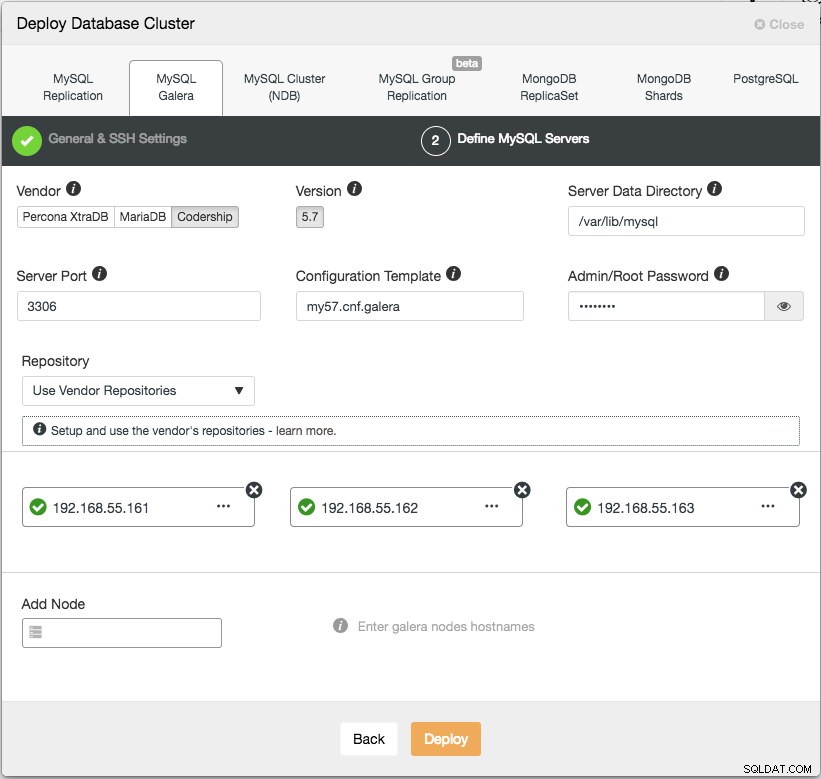
Na próxima etapa, precisamos configurar os servidores de banco de dados - fornecedor, versão, datadir, porta, etc - que são bastante autoexplicativos. "Modelo de configuração" é o nome do arquivo de modelo em /usr/share/cmon/templates do nó ClusterControl. "Repositório" é como o ClusterControl deve configurar o repositório no nó do banco de dados. Por padrão, ele usará o repositório do fornecedor e instalará a versão mais recente fornecida pelo repositório. No entanto, em alguns casos, o usuário pode ter um repositório pré-existente espelhado do repositório original devido à restrição da política de segurança. No entanto, o ClusterControl suporta a maioria deles, conforme descrito no guia do usuário, em Repositório.
Por fim, adicione o endereço IP ou o nome do host (deve ser um FQDN válido) dos nós do banco de dados. Você verá um ícone de visto verde à esquerda do nó, indicando que o ClusterControl conseguiu se conectar ao nó via SSH sem senha. Agora você está pronto para ir. Clique em Implantar para iniciar a implantação. Isso pode levar de 15 a 20 minutos para ser concluído. Você pode monitorar o progresso da implantação em Atividade (menu superior) -> Trabalhos -> Criar cluster :
Concluída a implantação, neste ponto, nossa arquitetura pode ser ilustrada conforme abaixo:
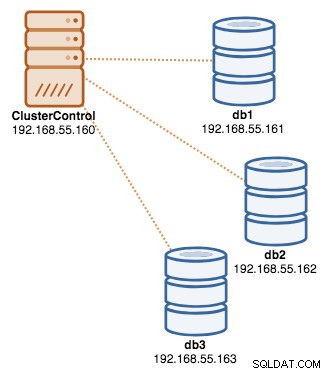
Implantando os balanceadores de carga
No Galera Cluster, todos os nós são iguais - cada nó tem a mesma função e o mesmo conjunto de dados. Portanto, não há failover no cluster se um nó falhar. Somente o lado do aplicativo requer failover, para ignorar os nós inoperantes enquanto o cluster é particionado. Portanto, é altamente recomendável colocar balanceadores de carga em cima de um Galera Cluster para:
- Unifique os vários endpoints do banco de dados em um único endpoint (host do balanceador de carga ou endereço IP virtual como endpoint).
- Equilibrar as conexões de banco de dados entre os servidores de banco de dados de back-end.
- Realize verificações de integridade e encaminhe apenas as conexões de banco de dados para nós íntegros.
- Redirecionar/reescrever/bloquear consultas ofensivas (mal escritas) antes que elas atinjam os servidores de banco de dados.
Existem três opções principais de proxies reversos para o Galera Cluster - HAProxy, MariaDB MaxScale ou ProxySQL - todos podem ser instalados e configurados automaticamente pelo ClusterControl. Nesta implantação, escolhemos o ProxySQL porque ele verifica todos os itens acima e entende o protocolo MySQL dos servidores de back-end.
Nesta arquitetura, queremos usar dois servidores ProxySQL para eliminar qualquer ponto único de falha (SPOF) na camada do banco de dados, que será vinculado usando um endereço IP virtual flutuante. Explicaremos isso na próxima seção. Um nó atuará como proxy ativo e o outro como hot-standby. Qualquer nó que mantenha o endereço IP virtual em um determinado momento é o nó ativo.
Para implantar o primeiro servidor ProxySQL, basta ir ao menu de ação do cluster (lado direito da barra de resumo) e clicar em Adicionar balanceador de carga -> ProxySQL -> Implantar ProxySQL e você verá o seguinte:
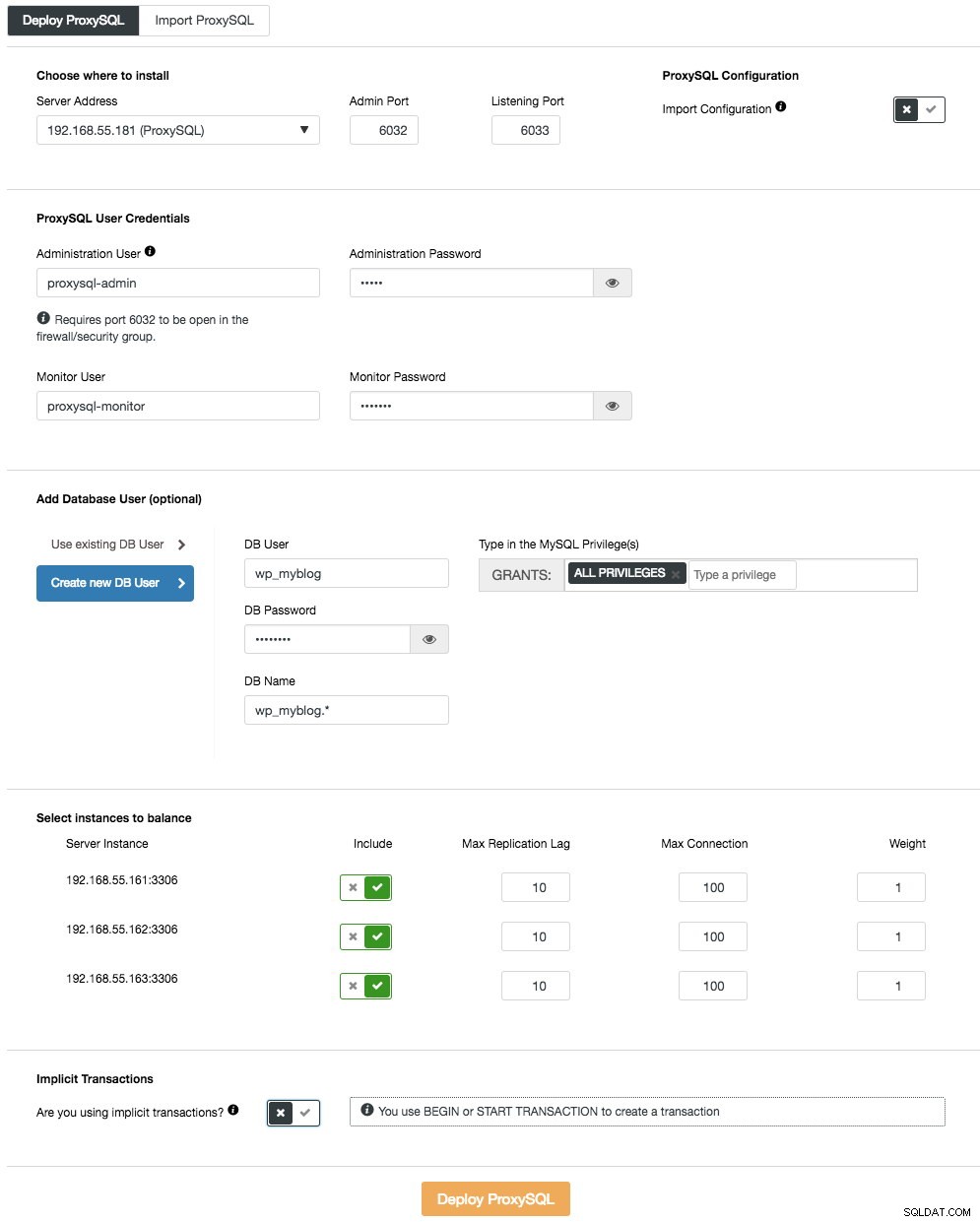
Novamente, a maioria dos campos são autoexplicativos. Na seção "Usuário do banco de dados", o ProxySQL atua como um gateway por meio do qual seu aplicativo se conecta ao banco de dados. O aplicativo é autenticado no ProxySQL, portanto, você deve adicionar todos os usuários de todos os nós MySQL de back-end, juntamente com suas senhas, no ProxySQL. A partir do ClusterControl, você pode criar um novo usuário para ser usado pelo aplicativo - você pode decidir sobre seu nome, senha, acesso a quais bancos de dados são concedidos e quais privilégios MySQL esse usuário terá. Esse usuário será criado no lado do MySQL e do ProxySQL. A segunda opção, mais adequada para infraestruturas existentes, é usar os usuários de banco de dados existentes. Você precisa passar nome de usuário e senha, e tal usuário será criado apenas no ProxySQL.
Na última seção, "Transação Implícita", o ClusterControl configurará o ProxySQL para enviar todo o tráfego para o mestre se iniciarmos a transação com SET autocommit=0. Caso contrário, se você usar BEGIN ou START TRANSACTION para criar uma transação, o ClusterControl configurará a divisão de leitura/gravação nas regras de consulta. Isso é para garantir que o ProxySQL trate as transações corretamente. Se você não tem ideia de como seu aplicativo faz isso, você pode escolher o último.
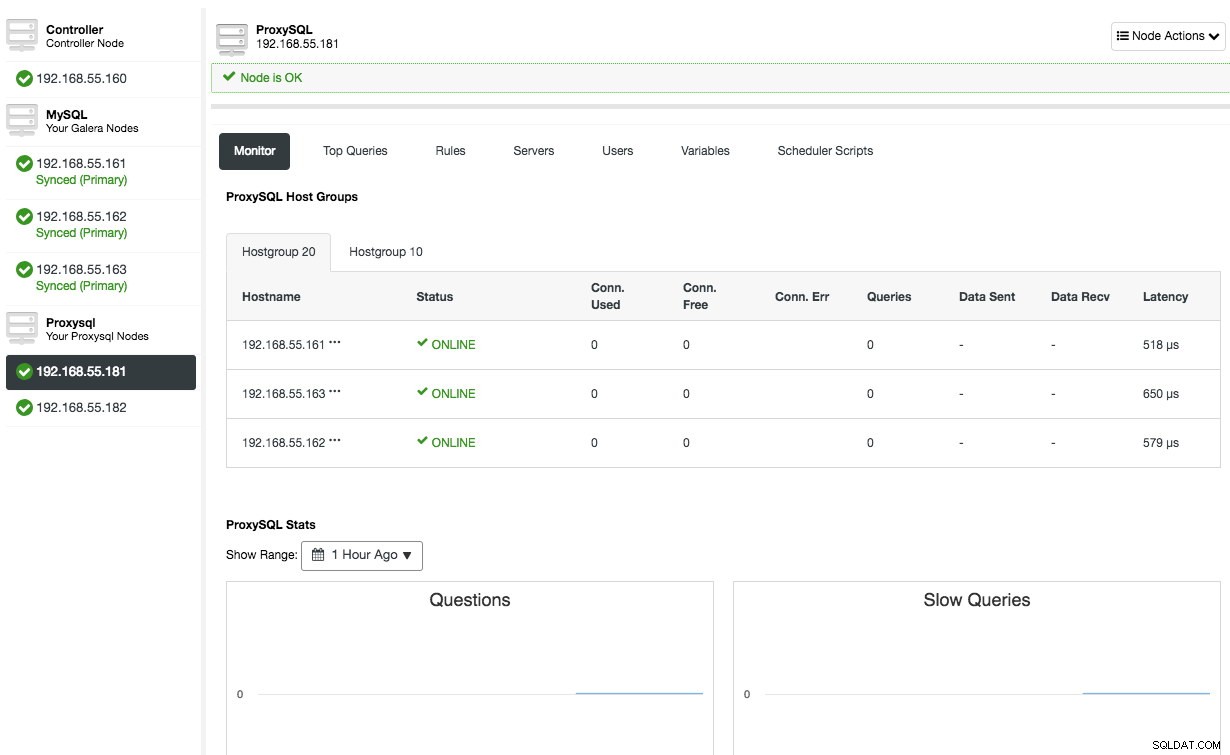
Repita a mesma configuração para o segundo nó ProxySQL, exceto o valor "Server Address" que é 192.168.55.182. Uma vez feito, ambos os nós serão listados na aba "Nodes" -> ProxySQL onde você pode monitorá-los e gerenciá-los diretamente da interface do usuário:
Neste ponto, nossa arquitetura agora está assim:
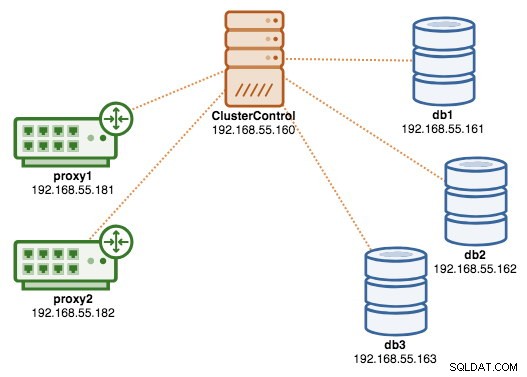
Se você quiser saber mais sobre ProxySQL, confira este tutorial - Database Load Balancing for MySQL and MariaDB with ProxySQL - Tutorial.
Implantando o endereço IP virtual
A parte final é o endereço IP virtual. Sem ele, nossos balanceadores de carga (proxies reversos) seriam o elo fraco, pois seriam um ponto único de falha - a menos que o aplicativo tenha a capacidade de redirecionar automaticamente conexões de banco de dados com falha para outro balanceador de carga. No entanto, é uma boa prática unificá-los usando o endereço IP virtual e simplificar o endpoint de conexão com a camada de banco de dados.
De ClusterControl UI -> Adicionar balanceador de carga -> Keepalived -> Implantar Keepalived e selecione os dois hosts ProxySQL que implantamos:
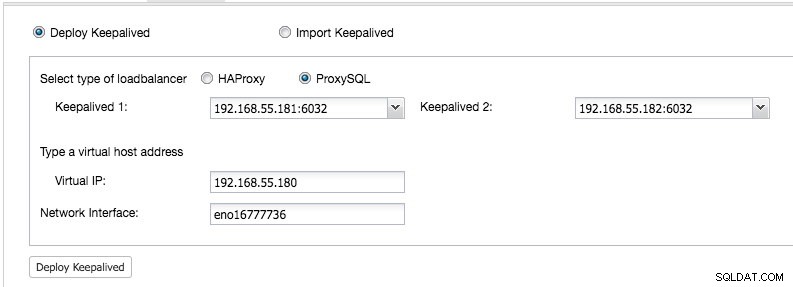
Além disso, especifique o endereço IP virtual e a interface de rede para vincular o endereço IP. A interface de rede deve existir em ambos os nós ProxySQL. Depois de implantado, você verá as seguintes verificações verdes na barra de resumo do cluster:

Neste ponto, nossa arquitetura pode ser ilustrada como abaixo:
Nosso cluster de banco de dados agora está pronto para uso em produção. Você pode importar seu banco de dados existente para ele ou criar um novo banco de dados. Você pode usar o recurso Gerenciamento de esquemas e usuários se a licença de avaliação não tiver expirado.
Para entender como o ClusterControl configura o Keepalived, confira esta postagem de blog, Como o ClusterControl configura o IP virtual e o que esperar durante o failover.
Conectando-se ao cluster de banco de dados
Do ponto de vista do aplicativo e do cliente, eles precisam se conectar a 192.168.55.180 na porta 6033, que é o endereço IP virtual flutuando sobre os balanceadores de carga. Por exemplo, a configuração do banco de dados Wordpress será algo assim:
/** The name of the database for WordPress */
define( 'DB_NAME', 'wp_myblog' );
/** MySQL database username */
define( 'DB_USER', 'wp_myblog' );
/** MySQL database password */
define( 'DB_PASSWORD', 'mysecr3t' );
/** MySQL hostname - virtual IP address with ProxySQL load-balanced port*/
define( 'DB_HOST', '192.168.55.180:6033' );Se você quiser acessar o cluster de banco de dados diretamente, ignorando o balanceador de carga, basta conectar-se à porta 3306 dos hosts do banco de dados. Isso geralmente é exigido pela equipe do DBA para administração, gerenciamento e solução de problemas. Com o ClusterControl, a maioria dessas operações pode ser executada diretamente da interface do usuário.
Considerações finais
Conforme mostrado acima, implantar um cluster de banco de dados não é mais uma tarefa difícil. Uma vez implantado, há um conjunto completo de recursos de monitoramento gratuitos, bem como recursos comerciais para gerenciamento de backup, failover/recuperação e outros. A implementação rápida de diferentes tipos de topologias de cluster/replicação pode ser útil ao avaliar soluções de banco de dados de alta disponibilidade e como elas se ajustam ao seu ambiente específico.



