Introdução
Carretéis de desempenho são carretéis preguiçosos adicionados pelo otimizador para reduzir o custo estimado do lado interno de junções de loops aninhados . Eles vêm em três variedades:Carretel de mesa preguiçoso , Carretel de índice lento e Carretel de contagem de linhas lentas . Um exemplo de forma de plano mostrando um spool de desempenho de tabela lenta está abaixo:
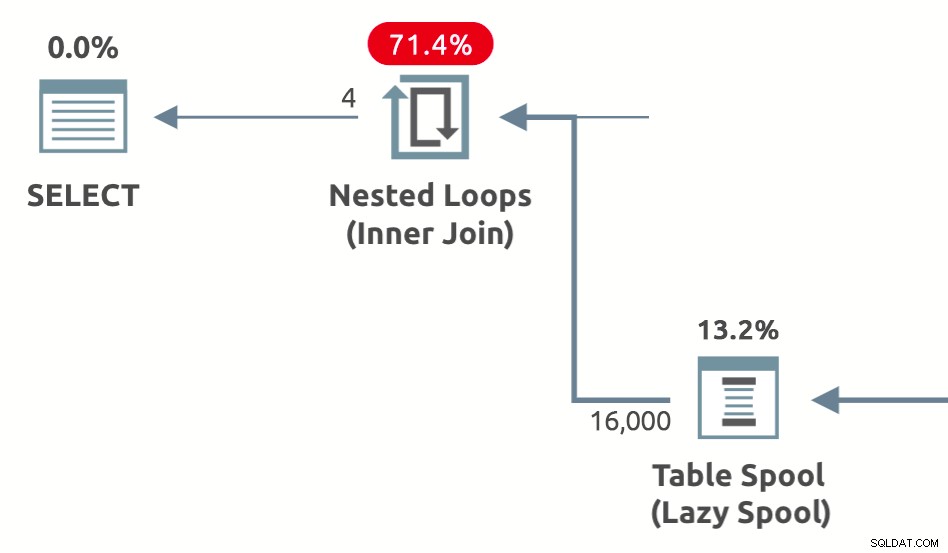
As perguntas que pretendo responder neste artigo são por que, como e quando o otimizador de consulta apresenta cada tipo de spool de desempenho.
Pouco antes de começarmos, quero enfatizar um ponto importante:há dois tipos distintos de junção de loop aninhado nos planos de execução. Vou me referir à variedade com referências externas como uma aplicação , e o tipo com um predicado de junção no próprio operador de junção como uma junção de loops aninhados . Para ser claro, essa diferença é sobre operadores de plano de execução , não sintaxe de consulta T-SQL. Para obter mais detalhes, consulte meu artigo vinculado.
Spools de desempenho
A imagem abaixo mostra o carretel de desempenho operadores de plano de execução conforme exibido no Plan Explorer (linha superior) e SSMS 18.3 (linha inferior):
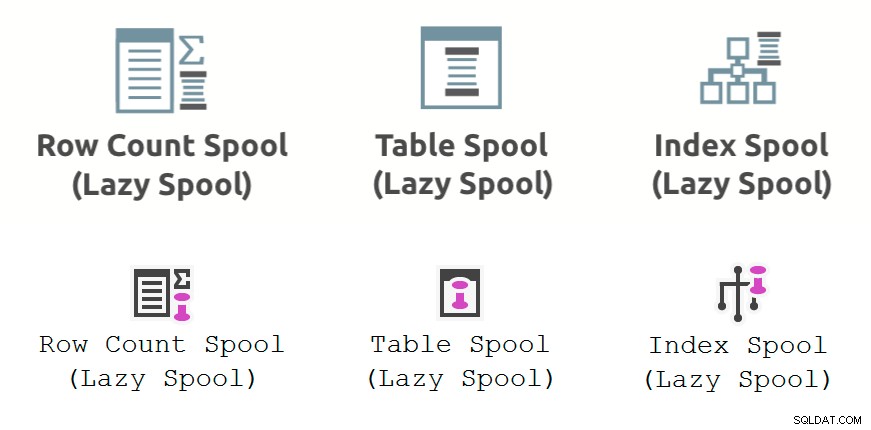
Observações gerais
Todos os spools de desempenho são preguiçosos . A mesa de trabalho do carretel é preenchida gradualmente, uma linha por vez, à medida que as linhas fluem pelo carretel. (Spools ansiosos, por outro lado, consomem toda a entrada de seu operador filho antes de retornar qualquer linha ao pai).
Os carretéis de desempenho sempre aparecem no lado interno (a entrada inferior em planos de execução gráfica) de um operador join ou apply de loops aninhados. A ideia geral é armazenar em cache e reproduzir resultados, salvando execuções repetidas de operadores internos sempre que possível.
Quando um spool é capaz de reproduzir resultados em cache, isso é conhecido como retroceder . Quando o spool precisa executar seus operadores filhos para obter dados corretos, um rebind ocorre.
Você pode achar útil pensar em um carretel religar como um cache miss e um rewind como um hit de cache.
Carretel de mesa preguiçoso
Este tipo de carretel de desempenho pode ser usado com aplicar e junção de loops aninhados .
Aplicar
Uma religação (cache miss) ocorre sempre que uma referência externa alterações de valor. Um carretel de mesa preguiçoso é religado truncando sua tabela de trabalho e repovoando-a totalmente a partir de seus operadores filhos.
Um retrocesso (cache hit) ocorre quando o lado interno é executado com o mesmo valores de referência externos como os imediatamente anteriores iteração do laço. Um retrocesso reproduz os resultados em cache da tabela de trabalho do spool, economizando o custo de reexecutar os operadores do plano abaixo do spool.
Observação:um spool de tabela preguiçoso armazena em cache apenas os resultados de um conjunto de aplicar referência externa valores por vez.
Unir Loops Aninhados
O spool de tabela lenta é preenchido uma vez durante a primeira iteração do loop. O spool rebobina seu conteúdo para cada iteração subsequente da junção. Com a junção de loops aninhados, o lado interno da junção é um conjunto estático de linhas porque o predicado da junção está na própria junção. O conjunto de linhas do lado interno estático pode, portanto, ser armazenado em cache e reutilizado várias vezes por meio do spool. Um spool de desempenho de junção de loops aninhados nunca é revinculado.
Carretel de contagem de linhas lentas
Um spool de contagem de linhas é pouco mais que um Spool de tabela sem colunas. Ele armazena em cache a existência de uma linha, mas não projeta dados de coluna. Além de observar sua existência e mencionar que pode ser uma indicação de um erro na consulta de origem, não terei mais a dizer sobre spools de contagem de linhas.
Deste ponto em diante, sempre que você vir “carretel de tabela” no texto, leia-o como “carretel de tabela (ou contagem de linhas)” porque eles são muito semelhantes.
Carretel de índice lento
O carretel de índice preguiçoso operador está disponível apenas com aplicação .
O spool de índice mantém uma tabela de trabalho não truncada quando referência externa os valores mudam. Em vez disso, novos dados são adicionados ao cache existente, indexados pelos valores de referência externos. Um spool de índice lento difere de um spool de tabela lento, pois pode reproduzir resultados de qualquer iteração de loop anterior, não apenas a mais recente.
A próxima etapa para entender quando os spools de desempenho aparecem nos planos de execução requer entender um pouco sobre como o otimizador funciona.
Plano de fundo do otimizador
Uma consulta de origem é convertida em uma representação de árvore lógica por análise, algebrização, simplificação e normalização. Quando a árvore resultante não se qualifica para um plano trivial, o otimizador baseado em custo procura alternativas lógicas que garantem produzir os mesmos resultados, mas a um custo estimado mais baixo.
Uma vez que o otimizador tenha gerado alternativas potenciais, ele implementa cada uma usando operadores físicos apropriados e calcula os custos estimados. O plano de execução final é construído a partir da opção de menor custo encontrada para cada grupo de operadoras. Você pode ler mais detalhes sobre o processo em minha série Deep Dive do Query Optimizer.
As condições gerais necessárias para que um spool de desempenho apareça no plano final do otimizador são:
- O otimizador deve explorar uma alternativa lógica que inclui um spool lógico em um substituto gerado. Isso é mais complexo do que parece, então vou descompactar os detalhes na próxima seção principal.
- O spool lógico deve ser implementável como um carretel físico operador no motor de execução. Para versões modernas do SQL Server, isso significa essencialmente que todas as colunas de chave em um spool de índice devem ser de um comparável tipo, não mais de 900 bytes* no total, com 64 colunas de chave ou menos.
- O melhor o plano completo após a otimização baseada em custo deve incluir uma das alternativas de spool. Em outras palavras, qualquer escolha baseada em custo feita entre opções de carretel e não carretel deve ser favorável ao carretel.
* Este valor é codificado no SQL Server e não foi alterado após o aumento para 1700 bytes para não clusterizados chaves de índice do SQL Server 2016 em diante. Isso ocorre porque o índice de spool é um agrupado índice, não um índice não clusterizado.
Regras do otimizador
Não podemos especificar um spool usando T-SQL, portanto, obter um em um plano de execução significa que o otimizador deve optar por adicioná-lo. Como primeiro passo, isso significa que o otimizador deve incluir um spool lógico em uma das alternativas que escolher explorar.
O otimizador não aplica exaustivamente todas as regras de equivalência lógica que conhece a cada árvore de consulta. Isso seria um desperdício, dado o objetivo do otimizador de produzir um plano razoável rapidamente. Existem vários aspectos para isso. Em primeiro lugar, o otimizador procede em etapas, com regras mais baratas e mais aplicáveis testadas primeiro. Se um plano razoável for encontrado em um estágio inicial ou a consulta não se qualificar para estágios posteriores, o esforço de otimização poderá terminar antecipadamente com o plano de custo mais baixo encontrado até o momento. Essa estratégia ajuda a evitar gastar mais tempo em otimização do que é economizado por melhorias incrementais de custo.
Correspondência de regras
Cada operador lógico na árvore de consulta é rapidamente verificado quanto a uma correspondência de padrão com as regras disponíveis no estágio de otimização atual. Por exemplo, cada regra corresponderá apenas a um subconjunto de operadores lógicos e também pode exigir que propriedades específicas estejam em vigor, como entrada classificada garantida. Uma regra pode corresponder a uma operação lógica individual (um único grupo) ou a vários grupos contíguos (uma subseção do plano).
Após a correspondência, uma regra candidata é solicitada a gerar um valor de promessa . Este é um número que representa a probabilidade de a regra atual produzir um resultado útil, dado o contexto local. Por exemplo, uma regra pode gerar um valor de promessa mais alto quando o destino tiver muitas duplicatas em sua entrada, um grande número estimado de linhas, entrada classificada garantida ou alguma outra propriedade desejável.
Uma vez identificadas as regras de exploração promissoras, o otimizador as classifica em ordem de valor de promessa e começa a pedir que gerem novos substitutos lógicos. Cada regra pode gerar um ou mais substitutos que posteriormente serão implementados por meio de operadores físicos. Como parte desse processo, é calculado um custo estimado.
O ponto de tudo isso como se aplica aos spools de desempenho é que a forma e as propriedades do plano lógico devem ser conducentes a regras compatíveis com spool, e o contexto local deve produzir um valor de promessa alto o suficiente para que o otimizador escolha gerar substitutos usando a regra .
Regras de spool
Existem várias regras que exploram a junção de loops aninhados lógicas ou aplicar alternativas. Algumas dessas regras podem produzir um ou mais substitutos com um tipo específico de carretel de desempenho. Outras regras que correspondem à junção ou aplicação de loops aninhados nunca geram uma alternativa de spool.
Por exemplo, a regra
ApplyToNL implementa uma lógica aplicar como um loop físico se junta a referências externas. Esta regra pode gerar várias alternativas cada vez que é executado. Além do operador de junção física, cada substituto pode conter um spool de tabela lento, um spool de índice lento ou nenhum spool. Os substitutos lógicos de spool são posteriormente implementados individualmente e custeados como os spools físicos adequadamente tipados, por outra regra chamada BuildSpool . Como segundo exemplo, a regra
JNtoIdxLookup implementa uma junção lógica como um aplicar físico , com uma busca de índice imediatamente no lado interno. Esta regra nunca gera uma alternativa com um componente de carretel. JNtoIdxLookup é avaliado antecipadamente e retorna um alto valor de promessa quando corresponde, portanto, planos simples de pesquisa de índice são encontrados rapidamente. Quando o otimizador encontra uma alternativa de baixo custo como essa logo no início, alternativas mais complexas podem ser agressivamente eliminadas ou totalmente ignoradas. O raciocínio é que não faz sentido buscar opções que provavelmente não melhorarão em uma alternativa de baixo custo já encontrada. Da mesma forma, não vale a pena explorar mais se o melhor plano completo atual já tiver um custo total baixo o suficiente.
Um terceiro exemplo de regra:A regra
JNtoNL é semelhante a ApplyToNL , mas apenas implementa junção de loop aninhado física , com um carretel de mesa preguiçoso ou sem carretel. Esta regra nunca gera um spool de índice porque esse tipo de spool requer uma aplicação. Geração e custo de spool
Uma regra capaz de gerar um spool lógico não necessariamente o fará toda vez que for chamado. Seria um desperdício gerar alternativas lógicas que têm quase nenhuma chance de serem escolhidas como mais baratas. Há também um custo para gerar novas alternativas, que podem, por sua vez, produzir ainda mais alternativas – cada uma das quais pode precisar de implementação e custeio.
Para gerenciar isso, o otimizador implementa uma lógica comum para todas as regras com capacidade de spool para determinar quais tipos de alternativas de spool gerar com base nas condições do plano local.
Unir Loops Aninhados
Para uma junção de loops aninhados , a chance de obter um carretel de mesa preguiçoso aumenta de acordo com:
- O número estimado de linhas na entrada externa da junção.
- O custo estimado de operadores de planos internos.
O custo do carretel é reembolsado por economias feitas evitando execuções de operadores internos. As economias aumentam com mais iterações internas e maior custo interno. Isso é especialmente verdadeiro porque o modelo de custo atribui números de custo de E/S e CPU relativamente baixos para retrocessos de spool de tabela (acertos de cache). Lembre-se de que um spool de tabela em uma junção de loops aninhados só experimenta retrocessos, porque a falta de parâmetros significa que o conjunto de dados do lado interno é estático.
Um spool pode armazenar dados mais densamente do que os operadores que o alimentam. Por exemplo, um índice clusterizado de tabela base pode armazenar, em média, 100 linhas por página. Digamos que uma consulta precise apenas de um único valor de coluna inteiro de cada linha de índice clusterizado amplo. Armazenar apenas o valor inteiro na tabela de trabalho do spool significa que mais de 800 dessas linhas podem ser armazenadas por página. Isso é importante porque o otimizador avalia o custo do spool da tabela em parte usando uma estimativa do número de páginas da tabela de trabalho precisava. Outros fatores de custo incluem o custo de CPU por linha envolvido na gravação e leitura do spool, sobre o número estimado de iterações de loop.
O otimizador está indiscutivelmente um pouco interessado em adicionar spools de tabela preguiçosos ao lado interno de uma junção de loops aninhados. No entanto, a decisão do otimizador sempre faz sentido em termos de custo estimado. Eu pessoalmente considero a junção de loops aninhados como alto risco , porque eles podem se tornar rapidamente lentos se a estimativa de cardinalidade de entrada de junção for muito baixa.
Um carretel de mesa pode ajuda a reduzir o custo, mas não pode ocultar totalmente o desempenho de pior caso de uma junção de loops aninhados ingênuos. Uma junção de aplicação indexada é normalmente preferível e mais resiliente a erros de estimativa. Também é uma boa ideia escrever consultas que o otimizador possa implementar com hash ou merge join quando apropriado.
Aplicar Spool de Mesa Preguiçoso
Para uma candidatura , as chances de obter um carretel de mesa preguiçoso aumentar com o número estimado de duplicatas valores de chave de junção na entrada externa do apply. Com mais duplicatas, há um estatisticamente maior chance de o carretel rebobinar seus resultados atualmente armazenados em cada iteração. Um carretel de mesa preguiçoso aplicado com um custo estimado mais baixo tem uma chance melhor de aparecer no plano de execução final.
Quando as linhas que chegam na entrada externa apply não têm uma ordenação específica, o otimizador faz uma avaliação estatística da probabilidade de cada iteração resultar em um retrocesso barato ou um religamento caro. Essa avaliação usa dados de etapas do histograma quando disponíveis, mas mesmo esse melhor cenário é mais uma suposição. Sem uma garantia, a ordem das linhas que chegam na entrada externa aplicada é imprevisível.
As mesmas regras do otimizador que geram alternativas lógicas de spool podem também especifique que o operador apply requer linhas classificadas em sua entrada externa. Isso maximiza o spool lento rebobina porque é garantido que todas as duplicatas serão encontradas em um bloco. Quando a ordem de classificação de entrada externa é garantida, seja por ordenação preservada ou por uma Classificação explícita , o custo do carretel é muito reduzido. O otimizador leva em consideração o impacto da ordem de classificação no número de rebobinas e religações de spool.
Planos com uma Classificação na entrada externa de aplicação e um Spool de tabela preguiçoso na entrada interna são bastante comuns. A otimização de classificação do lado externo ainda pode acabar sendo contraproducente. Por exemplo, isso pode acontecer quando a estimativa de cardinalidade do lado externo é tão baixa que a classificação acaba sendo derramada para tempdb .
Aplicar spool de índice lento
Para uma candidatura , obtendo um spool de índice lento alternativa depende da forma do plano, bem como do custo.
O otimizador requer:
- Alguns duplicados valores de junção na entrada externa.
- Uma igualdade join predicate (ou um equivalente lógico que o otimizador entenda, como
x <= y AND x >= y). - Uma garantia que as referências externas são únicas abaixo do spool de índice lento proposto.
Nos planos de execução, a exclusividade necessária geralmente é fornecida por um agrupamento agregado pelas referências externas ou um agregado escalar (um sem agrupar por). A exclusividade também pode ser fornecida de outras maneiras, por exemplo, pela existência de um índice ou restrição única.
Um exemplo de brinquedo que mostra a forma do plano está abaixo:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c); 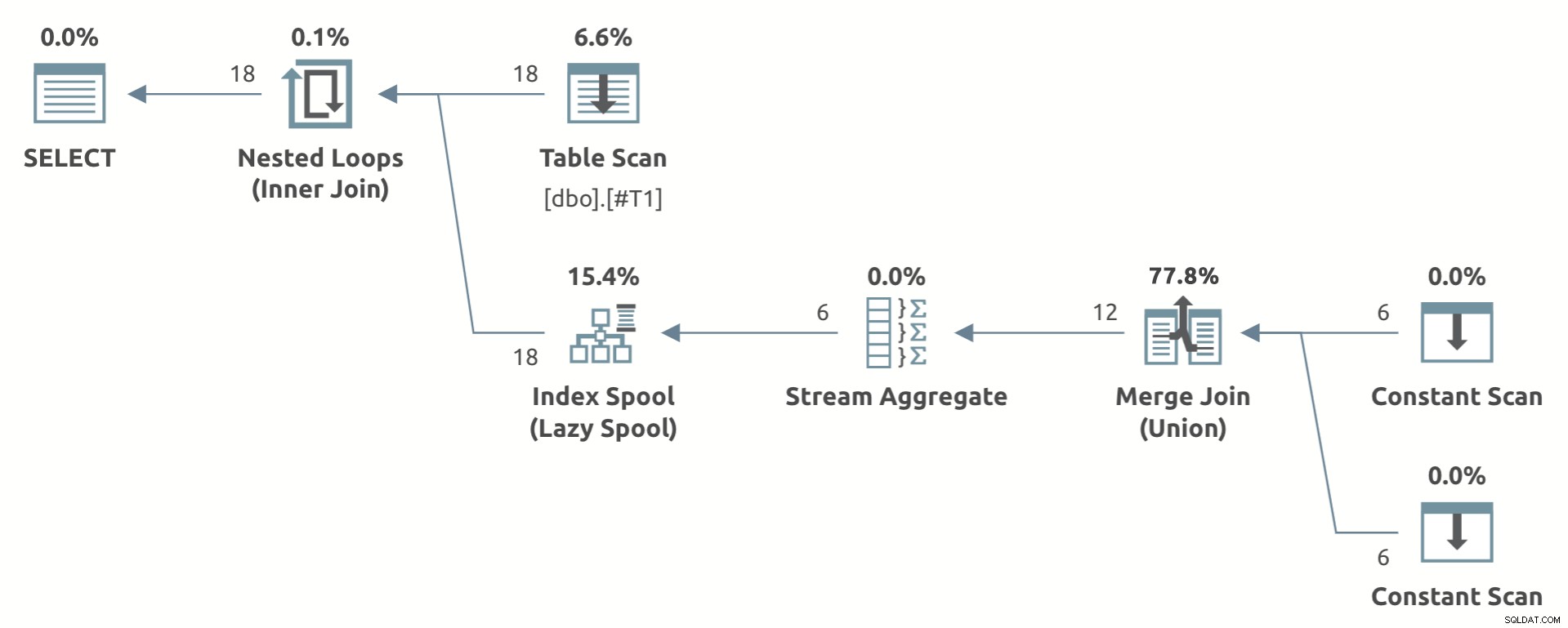
Observe o Stream Aggregate abaixo do Carretel de índice lento .
Se os requisitos de forma do plano forem atendidos, o otimizador geralmente gerará uma alternativa de índice lento (sujeito às advertências mencionadas anteriormente). Se o plano final inclui um spool de índice lento ou não depende do custo.
Spool de índice versus spool de tabela
O número estimado de retrocessos e revincula para um spool de índice lento é o mesmo quanto a um carretel de mesa preguiçoso sem classificado aplicar entrada externa.
Isso pode parecer um estado de coisas bastante infeliz. A principal vantagem de um spool de índice é que ele armazena em cache todos os resultados vistos anteriormente. Isso deve fazer o spool de índice rebobinar mais provável do que para um carretel de mesa (sem classificação de entrada externa) nas mesmas circunstâncias. Meu entendimento é que essa peculiaridade existe porque, sem ela, o otimizador escolheria um spool de índice com muita frequência.
Independentemente disso, o modelo de custo se ajusta até certo ponto ao descrito acima usando diferentes números de custo de CPU e E/S de linha inicial e subsequente para spools de índice e tabela. O efeito líquido é que um spool de índice geralmente custa menos do que um spool de tabela sem entrada externa classificada, mas lembre-se dos requisitos restritivos de forma de plano, que tornam os spools de índice lentos relativamente cru.
Ainda assim, o principal concorrente de custo de um índice de spool lento é um spool de tabela com entrada externa classificada. A intuição para isso é bastante direta:a entrada externa classificada significa que o spool da tabela tem a garantia de ver todas as referências externas duplicadas sequencialmente. Isso significa que ele religará apenas uma vez por valor distinto e retroceder para todas as duplicatas. Isso é o mesmo que o comportamento esperado de um spool de índice (pelo menos logicamente falando).
Na prática, é mais provável que um spool de índice seja preferido em relação a um spool de tabela otimizado para classificação para menos valores de chave de aplicação duplicados. Ter menos chaves duplicadas reduz o retrocesso vantagem do spool de tabela otimizado para classificação, em comparação com as estimativas de spool de índice “infelizes” observadas anteriormente.
A opção de carretel de índice também se beneficia como o custo estimado de um carretel de mesa do lado externo Classificar aumenta. Isso seria mais frequentemente associado a mais (ou mais largas) linhas naquele ponto do plano.
Trace sinalizadores e dicas
-
Os spools de desempenho podem ser desativados com sinalizador de rastreamento levemente documentado 8690 , ou a dica de consulta documentadaNO_PERFORMANCE_SPOOLno SQL Server 2016 ou posterior.
-
Sinalizador de rastreamento não documentado 8691 pode ser usado (em um sistema de teste) para sempre adicionar um spool de desempenho quando possivel. O tipo do spool lento que você obtém (contagem de linhas, tabela ou índice) não pode ser forçado; ainda depende da estimativa de custos.
-
Sinalizador de rastreamento não documentado 2363 pode ser usado com o novo modelo de estimativa de cardinalidade para ver a derivação da estimativa distinta na entrada externa para uma aplicação e estimativa de cardinalidade em geral.
-
Sinalizador de rastreamento não documentado 9198 pode ser usado para desativar spools de desempenho de índice lento especificamente. Você ainda pode obter uma tabela preguiçosa ou um spool de contagem de linhas (com ou sem otimização de classificação), dependendo do custo.
-
Sinalizador de rastreamento não documentado 2387 pode ser usado para reduzir o custo da CPU de ler linhas de um spool de índice lento . Esse sinalizador afeta as estimativas gerais de custo de CPU para ler um intervalo de linhas de uma árvore b. Esse sinalizador tende a tornar a seleção de spool de índice mais provável, por motivos de custo.
Outros sinalizadores e métodos de rastreamento para determinar quais regras do otimizador foram ativadas durante a compilação da consulta podem ser encontrados em minha série Query Optimizer Deep Dive.
Considerações finais
Há muitos detalhes internos que afetam se o plano de execução final usa ou não um spool de desempenho. Tentei cobrir as principais considerações neste artigo, sem entrar muito nos detalhes extremamente intrincados das fórmulas de custeio do operador de carretel. Espero que haja conselhos gerais suficientes aqui para ajudá-lo a determinar possíveis razões para um determinado tipo de spool de desempenho em um plano de execução (ou a falta dele).
Carretéis de desempenho geralmente têm uma má reputação, acho que é justo dizer. Parte disso é, sem dúvida, merecido. Muitos de vocês já viram uma demonstração em que um plano é executado mais rapidamente sem um “spool de desempenho” do que com. Até certo ponto, isso não é inesperado. Existem casos extremos, o modelo de custo não é perfeito e, sem dúvida, as demonstrações geralmente apresentam planos com estimativas de cardinalidade ruins ou outros problemas que limitam o otimizador.
Dito isso, às vezes desejo que o SQL Server forneça algum tipo de aviso ou outro feedback quando recorrer a adicionar um spool de tabela preguiçoso a uma junção de loops aninhados (ou uma aplicação sem um índice interno de suporte utilizado). Como mencionado no corpo principal, essas são as situações que eu acho mais frequentemente erradas, quando as estimativas de cardinalidade se tornam terrivelmente baixas.
Talvez um dia o otimizador de consultas leve em consideração algum conceito de risco para planejar escolhas ou fornecer recursos mais “adaptativos”. Enquanto isso, vale a pena dar suporte a suas junções de loops aninhados com índices úteis e evitar escrever consultas que só podem ser implementadas usando loops aninhados sempre que possível. Estou generalizando, é claro, mas o otimizador tende a se sair melhor quando tem mais opções, um esquema razoável, bons metadados e instruções T-SQL gerenciáveis para trabalhar. Assim como eu, penso nisso.
Outros artigos de spool
Os spools sem desempenho são usados para muitas finalidades no SQL Server, incluindo:
- Proteção de Halloween
- Algumas funções da janela de modo de linha
- Cálculo de vários agregados
- Otimização de instruções que alteram dados