Hoje em dia, é bastante comum ter um banco de dados replicado em outro servidor/datacenter, e também obrigatório em alguns casos. Existem diferentes motivos para replicar seus bancos de dados em um ambiente totalmente separado.
- Migre para outro datacenter.
- Requisitos de atualização (hardware/software).
- Mantenha um sistema operacional totalmente sincronizado em um site de recuperação de desastres (DR) que pode assumir o controle a qualquer momento
- Mantenha um banco de dados escravo como parte de um plano de DR de custo mais baixo.
- Para requisitos de geolocalização (os dados precisam estar localmente em um país específico).
- Tenha um ambiente de teste.
- Propósito de solução de problemas.
- Banco de dados de relatórios.
E existem diferentes maneiras de realizar essa tarefa de replicação:
- Backup/Restauração :Fazer backup de um banco de dados de produção e restaurá-lo em um novo servidor/ambiente é a maneira clássica de fazer isso, mas também é uma maneira antiquada, pois você não manterá seus dados atualizados e precisará esperar para cada processo de restauração se você precisar de alguns dados recentes. Se você tiver um cluster (mestre-escravo, multimestre) e quiser recriá-lo, deverá restaurar o backup inicial e, em seguida, recriar o restante dos nós, o que pode ser uma tarefa demorada.
- Clone Cluster :É semelhante ao anterior, mas o processo de backup e restauração é para todo o cluster, não apenas para um servidor de banco de dados específico. Dessa forma, você pode clonar todo o cluster na mesma tarefa e não precisa recriar o restante dos nós manualmente. Esse método ainda tem o problema de manter os dados atualizados entre os clones.
- Replicação :Desta forma inclui a opção de backup/restauração, mas após a restauração inicial, o processo de replicação manterá seus dados sincronizados com o nó mestre. Dessa forma, se você tiver um cluster de banco de dados, precisará restaurar o backup em um nó e recriar todos os nós manualmente.
Neste blog, veremos um novo recurso do ClusterControl 1.7.4 que permite usar uma combinação do método que mencionamos anteriormente para melhorar essa tarefa.
O que é replicação de cluster para cluster?
A replicação entre dois clusters não é a mesma coisa que estender um cluster para ser executado em dois datacenters. Ao configurar a replicação entre dois clusters, na verdade temos 2 sistemas separados que podem operar de forma autônoma. A replicação é usada para mantê-los em sincronia, para que o sistema escravo tenha um estado atualizado e possa assumir o controle.
No ClusterControl 1.7.4, é possível criar um novo cluster clonando diretamente um cluster de origem em execução ou usando um backup recente do cluster de origem.
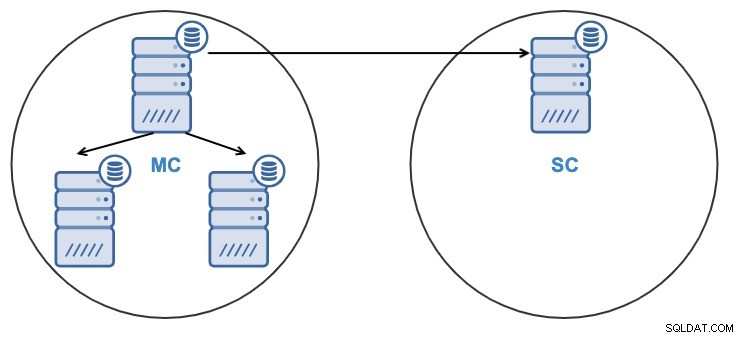
Após clonar o cluster, você terá um Slave Cluster (SC) recebendo dados e um Master Cluster (MC) enviando alterações para o slave.
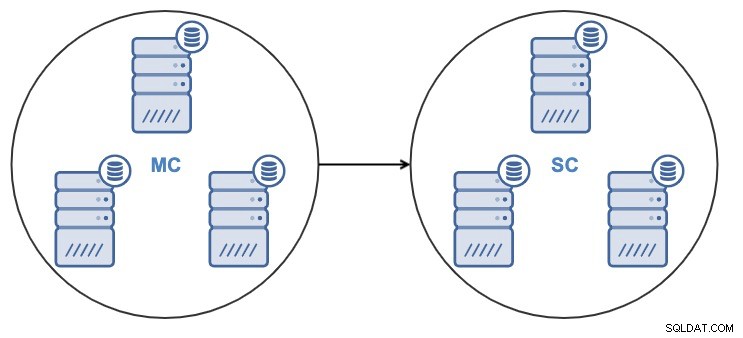
ClusterControl oferece suporte à replicação de cluster para cluster para os seguintes tipos de cluster:
- Percona XtraDB Cluster versão 5.6.xe posterior.
- MariaDB Galera Cluster versão 10.xe posterior.
- PostgreSQL 9.6 e posterior.
Replicação de cluster para cluster para Percona XtraDB / MariaDB Galera Cluster
Para mecanismos baseados em MySQL, o GTID é necessário para usar esse recurso, e a replicação assíncrona entre o cluster Mestre e o Escravo será usada.
Existem algumas ações a serem executadas para preparar o cluster atual para este trabalho. Primeiro, pelo menos um nó no cluster atual deve ter os logs binários habilitados. Em seguida, você precisa adicionar o usuário de backup configurado no nó do banco de dados no arquivo de configuração do ClusterControl, que será usado para tarefas de gerenciamento. Todas essas ações podem ser executadas usando a interface do usuário do ClusterControl ou a CLI do ClusterControl.
Agora você está pronto para criar a replicação Cluster-to-Cluster do Percona XtraDB/MariaDB Galera. Quando o trabalho estiver concluído, você terá:
- Um nó no cluster escravo será replicado de um nó no cluster mestre.
- A replicação será bidirecional entre os clusters.
- Todos os nós no cluster escravo serão somente leitura por padrão. É possível desabilitar o sinalizador somente leitura nos nós um por um.
- O clustering ativo-ativo só é recomendado se os aplicativos estiverem apenas tocando conjuntos de dados separados em um dos clusters, pois o mecanismo não oferece detecção ou resolução de conflitos.
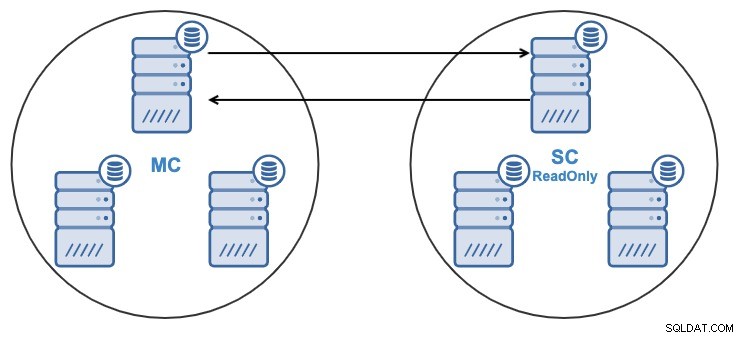
A partir da interface do usuário do ClusterControl ou da CLI do ClusterControl, você poderá:
- Crie este cluster de replicação.
- Ative a configuração Ativo-Ativo.
- Altere a topologia do cluster.
- Reconstrua um cluster de replicação.
- Parar/iniciar um escravo de replicação.
- Redefinir o escravo de replicação (implementado apenas usando o atm da CLI do ClusterControl).
Considerações
- O usuário de backup deve ser adicionado manualmente no arquivo de configuração do ClusterControl.
- As credenciais do usuário de backup devem ser as mesmas no cluster atual e no novo.
- A senha raiz do MySQL especificada ao criar o cluster escravo deve ser igual à senha raiz usada no cluster mestre.
Limitações conhecidas
- O Failover Automático ainda não é suportado. Se o mestre falhar, é responsabilidade do administrador fazer o failover para outro mestre.
- Só é possível "RESET" um escravo de replicação da CLI do ClusterControl, pois ainda não foi implementado na interface do usuário do ClusterControl.
- Só é possível reconstruir um cluster que esteja no modo somente leitura. Todos os nós em um cluster devem ser somente leitura para contar como cluster somente leitura.
Replicação de cluster para cluster para PostgreSQL
ClusterControl A replicação cluster a cluster é suportada no PostgreSQL usando a replicação de streaming.
Como requisito, deve haver um servidor PostgreSQL com a função ClusterControl 'master' e, ao configurar o cluster escravo, as credenciais de administrador devem ser idênticas ao cluster mestre.
Agora você está pronto para criar a replicação de cluster para cluster do PostgreSQL. Quando o trabalho estiver concluído, você terá:
- Um nó no cluster escravo será replicado de um nó no cluster mestre.
- A replicação será unidirecional entre os clusters.
- O nó no cluster escravo será somente leitura.
A partir da interface do usuário do ClusterControl ou da CLI do ClusterControl, você poderá:
- Crie este cluster de replicação.
- Reconstrua um cluster de replicação.
- Parar/iniciar um escravo de replicação.
Consideração
- As credenciais de administrador devem ser idênticas no cluster mestre e escravo.
Limitações conhecidas
- O tamanho máximo do cluster escravo é um nó.
- O cluster escravo não pode ser preparado a partir de um backup.
- Não há suporte para alterações de topologia.
- Apenas replicação unidirecional é compatível.
Conclusão
Usando esse novo recurso ClusterControl, você não precisa executar cada etapa para criar uma replicação de cluster separadamente ou manualmente e, como resultado, economizará tempo e esforço. De uma chance!