Uma das formas mais populares de obter alta disponibilidade para o MySQL é a replicação. A replicação existe há muitos anos e tornou-se muito mais estável com a introdução dos GTIDs. Mas mesmo com essas melhorias, o processo de replicação pode ser interrompido devido a vários motivos - por exemplo, quando o mestre e o escravo estão fora de sincronia porque as gravações foram enviadas diretamente para o escravo. Como você soluciona problemas de replicação e como os corrige?
Nesta postagem do blog, discutiremos alguns dos problemas comuns com a replicação e como corrigi-los com o ClusterControl. Comecemos pelo primeiro.
Replicação interrompida com algum erro
A maioria dos DBAs MySQL normalmente verá esse tipo de problema pelo menos uma vez em sua carreira. Por várias razões, um escravo pode ficar corrompido ou talvez parar de sincronizar com o mestre. Quando isso acontece, a primeira coisa a fazer para iniciar a solução de problemas é verificar se há mensagens no log de erros. Na maioria das vezes, a mensagem de erro é facilmente rastreável no log de erros ou executando a consulta SHOW SLAVE STATUS.
Vamos dar uma olhada no seguinte exemplo do SHOW STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Podemos ver claramente que o erro está relacionado a Obteve erro fatal 1236 do mestre ao ler dados do log binário:'Não foi possível encontrar o estado GTID solicitado pelo escravo em nenhum arquivo de log binário. Provavelmente o estado do escravo é muito antigo e os arquivos de log binário necessários foram removidos.'. Em outras palavras, o que o erro está nos dizendo essencialmente é que há inconsistência nos dados e os arquivos de log binários necessários já foram excluídos.
Este é um bom exemplo em que o processo de replicação para de funcionar. Além de SHOW SLAVE STATUS, você também pode acompanhar o status na aba “Overview” do cluster no ClusterControl. Então, como corrigir isso com o ClusterControl? Você tem duas opções para tentar:
-
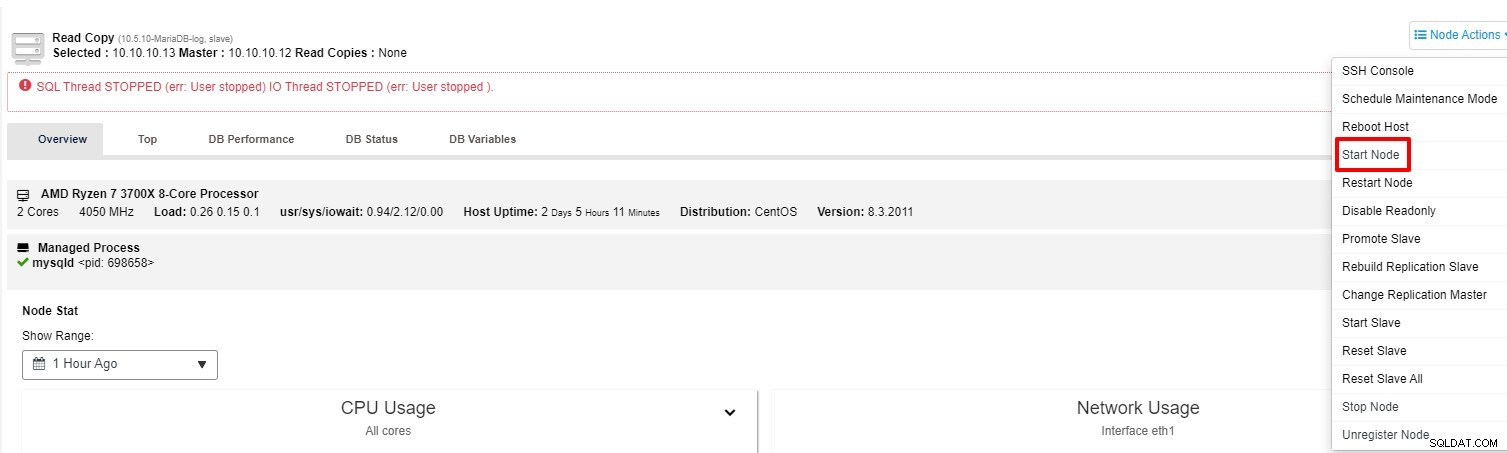
Você pode tentar iniciar o slave novamente a partir da “Node Action”
-
Se o slave ainda não estiver funcionando, você pode executar a tarefa “Rebuild Replication Slave” da "Ação do nó"
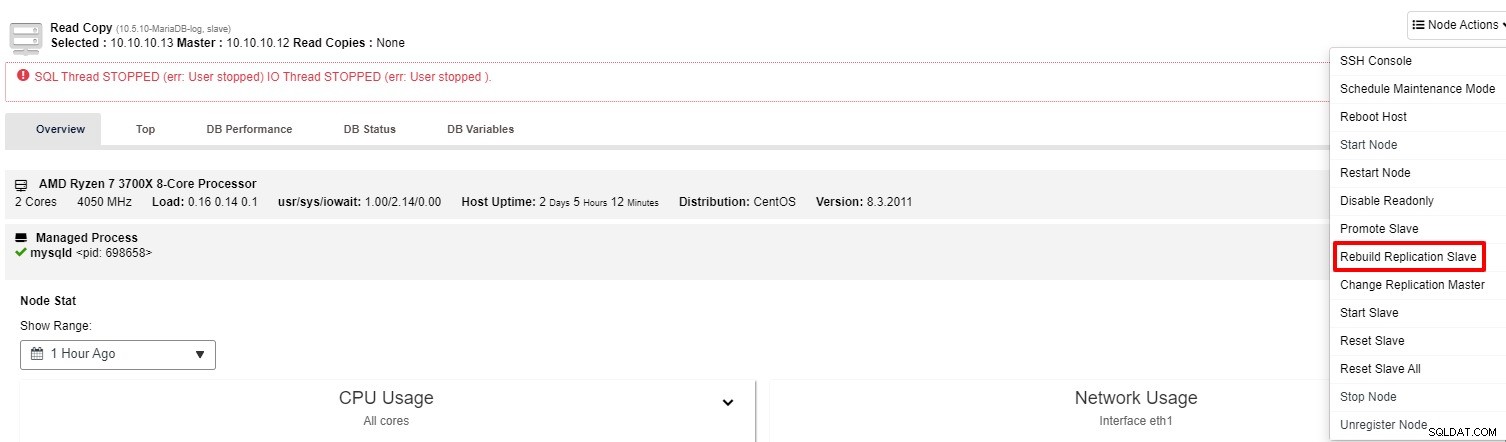
Na maioria das vezes, a segunda opção resolverá o problema. O ClusterControl fará um backup do mestre e reconstruirá o escravo quebrado restaurando os dados. Uma vez que os dados são restaurados, o escravo é conectado ao mestre para que possa recuperar o atraso.
Também existem várias maneiras manuais de reconstruir o escravo conforme listado abaixo, você também pode consultar este link para obter mais detalhes:
-
Usando o Mysqldump para reconstruir um escravo MySQL inconsistente
-
Usando o Mydumper para reconstruir um escravo MySQL inconsistente
-
Usando um instantâneo para reconstruir um escravo MySQL inconsistente
-
Usando um Xtrabackup ou Mariabackup para reconstruir um MySQL Slave inconsistente
Promova um escravo a mestre
Com o tempo, o sistema operacional ou banco de dados precisa ser corrigido ou atualizado para manter a estabilidade e a segurança. Uma das melhores práticas para minimizar o tempo de inatividade, especialmente para uma atualização importante, é promover um dos escravos para mestre após a atualização ter sido feita com sucesso nesse nó específico.
Ao fazer isso, você pode apontar seu aplicativo para o novo mestre e a replicação mestre-escravo continuará funcionando. Enquanto isso, você também pode prosseguir com a atualização do antigo mestre com tranquilidade. Com o ClusterControl, isso pode ser executado com apenas alguns cliques, desde que a replicação esteja configurada como baseada em ID de transação global ou baseada em GTID. Para evitar qualquer perda de dados, vale a pena interromper qualquer consulta do aplicativo caso o antigo mestre esteja funcionando corretamente. Esta não é a única situação em que você pode promover o escravo. Caso o nó mestre esteja inativo, você também pode executar esta ação.
Sem o ClusterControl, existem algumas etapas para promover o escravo. Cada uma das etapas requer que algumas consultas sejam executadas também:
-
Remova manualmente o mestre
-
Selecione o escravo mais avançado para ser um mestre e prepare-o
-
Reconecte outros escravos ao novo mestre
-
Alterar o antigo mestre para escravo
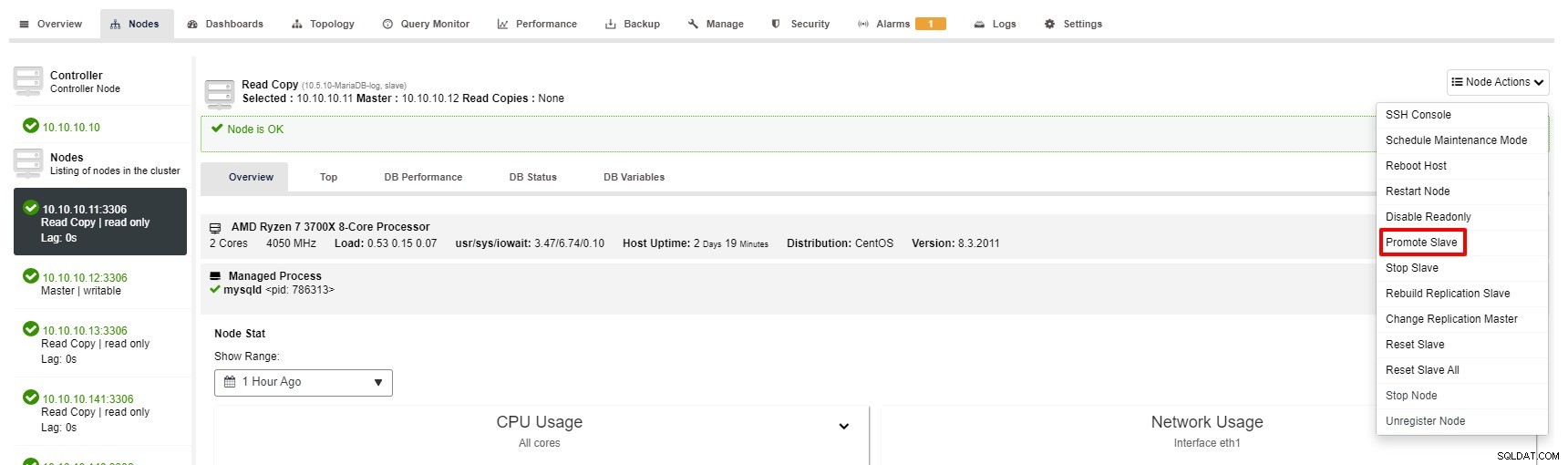
No entanto, os passos para Promover Slave com ClusterControl são apenas alguns cliques:Cluster> Nodes> escolha slave node> Promova Slave conforme a imagem abaixo:
Mestre fica indisponível
Imagine que você tem grandes transações para executar, mas o banco de dados está inativo. Não importa o quão cuidadoso você seja, esta é provavelmente a situação mais séria ou crítica para uma configuração de replicação. Quando isso acontece, seu banco de dados não consegue aceitar uma única gravação, o que é ruim. Além disso, seu(s) aplicativo(s), é claro, não funcionará corretamente.
Existem alguns motivos ou causas que levam a esse problema. Alguns dos exemplos são falha de hardware, corrupção do sistema operacional, corrupção de banco de dados e assim por diante. Como DBA, você precisa agir rapidamente para restaurar o banco de dados mestre.
Graças à função de cluster “Auto Recovery” que está disponível no ClusterControl, o processo de failover pode ser automatizado. Ele pode ser ativado ou desativado com um único clique. Como o nome diz, o que ele fará é exibir toda a topologia do cluster quando necessário. Por exemplo, uma replicação mestre-escravo deve ter pelo menos um mestre ativo em um determinado momento, independentemente do número de escravos disponíveis. Quando o mestre não estiver disponível, ele promoverá automaticamente um dos escravos.
Vamos dar uma olhada na captura de tela abaixo:
Na captura de tela acima, podemos ver que “Auto Recovery” está habilitado para Cluster e Node. Na topologia, observe que o endereço IP mestre atual é 10.10.10.11. O que acontecerá se derrubarmos o nó mestre para fins de teste?
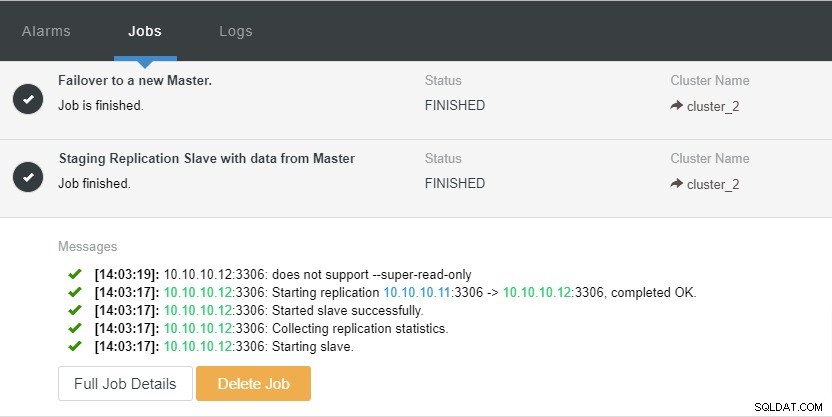
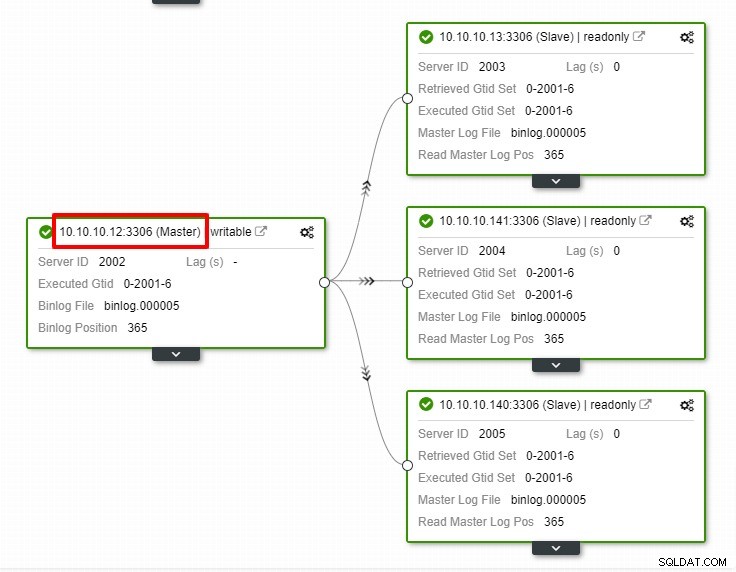
Como você pode ver, o nó escravo com IP 10.10.10.12 é automaticamente promovido a mestre, para que a topologia de replicação seja reconfigurada. Em vez de fazê-lo manualmente, o que, obviamente, envolverá muitas etapas, o ClusterControl ajuda você a manter sua configuração de replicação, eliminando o incômodo de suas mãos.
Conclusão
Em qualquer evento infeliz com sua replicação, a correção é muito simples e menos complicada com o ClusterControl. O ClusterControl ajuda você a recuperar seus problemas de replicação rapidamente, o que aumenta o tempo de atividade de seus bancos de dados.