A importância do failover
Failover é uma das práticas de banco de dados mais importantes para a governança de banco de dados. É útil não apenas ao gerenciar grandes bancos de dados em produção, mas também se você quiser ter certeza de que seu sistema estará sempre disponível sempre que você o acessar - especialmente no nível do aplicativo.
Antes de ocorrer um failover, suas instâncias de banco de dados precisam atender a determinados requisitos. Esses requisitos são, de fato, muito importantes para alta disponibilidade. Um dos requisitos que suas instâncias de banco de dados precisam atender é a redundância. A redundância permite que o failover continue, no qual a redundância é configurada para ter um candidato a failover que pode ser um nó de réplica (secundário) ou de um pool de réplicas atuando como nós em espera ou em espera ativa. O candidato é selecionado manualmente ou automaticamente com base no nó mais avançado ou atualizado. Normalmente, você deseja uma réplica em espera ativa, pois ela pode evitar que seu banco de dados extraia índices do disco, pois uma espera ativa geralmente preenche índices no pool de buffers do banco de dados.
Failover é o termo usado para descrever que ocorreu um processo de recuperação. Antes do processo de recuperação, isso ocorre quando um nó de banco de dados primário (ou mestre) falha após uma falha, após desastres naturais, após uma falha de hardware ou pode ter sofrido um particionamento de rede; esses são os casos mais comuns pelos quais um failover pode ocorrer. O processo de recuperação geralmente prossegue automaticamente e, em seguida, procura o secundário (réplica) mais desejado e atualizado, conforme indicado anteriormente.
Failover avançado
Embora o processo de recuperação durante um failover seja automático, há certas ocasiões em que não é necessário automatizar o processo e um processo manual deve assumir o controle. A complexidade geralmente é a principal consideração associada às tecnologias que compõem toda a pilha de seu banco de dados - o failover automático também pode ser misturado com o failover manual.
Na maioria das considerações diárias com o gerenciamento de bancos de dados, a maioria das preocupações em torno do failover automático não é trivial. Muitas vezes é útil implementar e configurar um failover automático caso ocorram problemas. Embora isso pareça promissor, pois abrange as complexidades, surgem os mecanismos avançados de failover e que envolvem eventos "pré" e "pós" que são amarrados como ganchos em um software ou tecnologia de failover.
Esses eventos pré e pós vêm com verificações ou determinadas ações a serem executadas antes que ele possa finalmente prosseguir com o failover e, após a conclusão do failover, algumas limpezas para garantir que o failover seja finalmente bem-sucedido 1. Felizmente, existem ferramentas disponíveis que permitem não apenas o Failover Automático, mas também a capacidade de aplicar ganchos pré e pós script.
Neste blog, usaremos o failover automático do ClusterControl (CC) e explicaremos como usar os ganchos pré e pós script e a qual cluster eles se aplicam.
Failover de replicação do ClusterControl
O mecanismo de failover ClusterControl é eficientemente aplicável em replicação assíncrona que é aplicável a variantes do MySQL (MySQL/Percona Server/MariaDB). Também é aplicável a clusters PostgreSQL/TimescaleDB - ClusterControl suporta replicação de streaming. Os clusters MongoDB e Galera têm seu próprio mecanismo para failover automático embutido em sua própria tecnologia de banco de dados. Leia mais sobre como o ClusterControl executa recuperação e failover automáticos do banco de dados.
O failover do ClusterControl não funciona, a menos que a recuperação de nó e cluster (recuperação automática esteja habilitada). Isso significa que esses botões devem ser verdes.

A documentação afirma que essas opções de configuração também podem ser usadas para habilitar / desative o seguinte:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
Para este blog, estamos nos concentrando principalmente em como usar os ganchos de script pré/pós, o que é essencialmente uma grande vantagem para failover de replicação avançada.
Suporte de script pré/pós-script de replicação de failover de cluster
Como mencionado anteriormente, as variantes do MySQL que usam replicação assíncrona (incluindo semi-síncrona) e replicação de streaming para PostgreSQL/TimescaleDB suportam esse mecanismo. O ClusterControl tem as seguintes opções de configuração que podem ser usadas para ganchos pré e pós script. Basicamente, essas opções de configuração podem ser definidas por meio de seus arquivos de configuração ou podem ser definidas por meio da interface do usuário da web (trataremos disso mais tarde).
Nossa documentação afirma que estas são as seguintes opções de configuração que podem alterar o mecanismo de failover usando os ganchos de script pré/pós:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
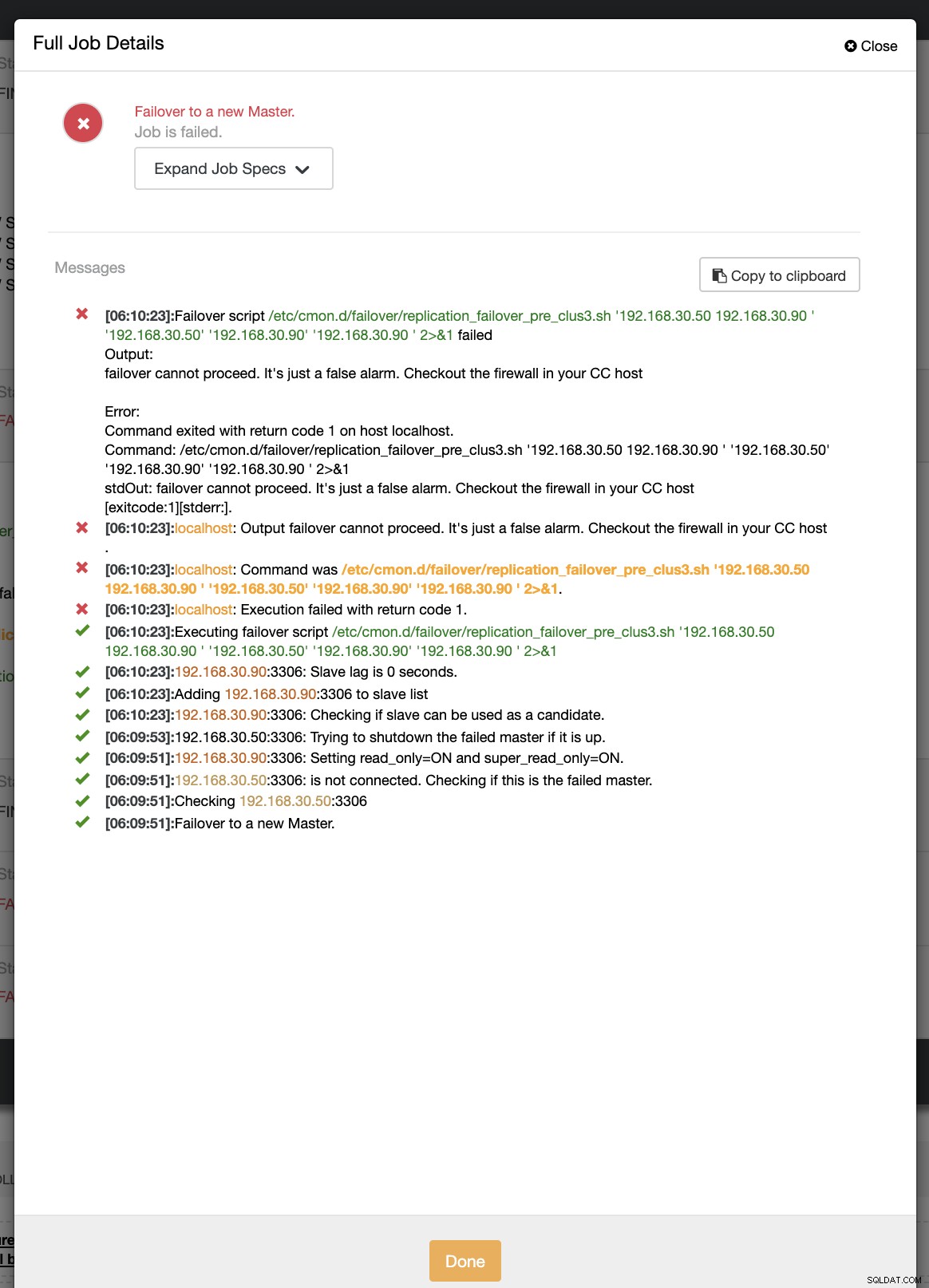
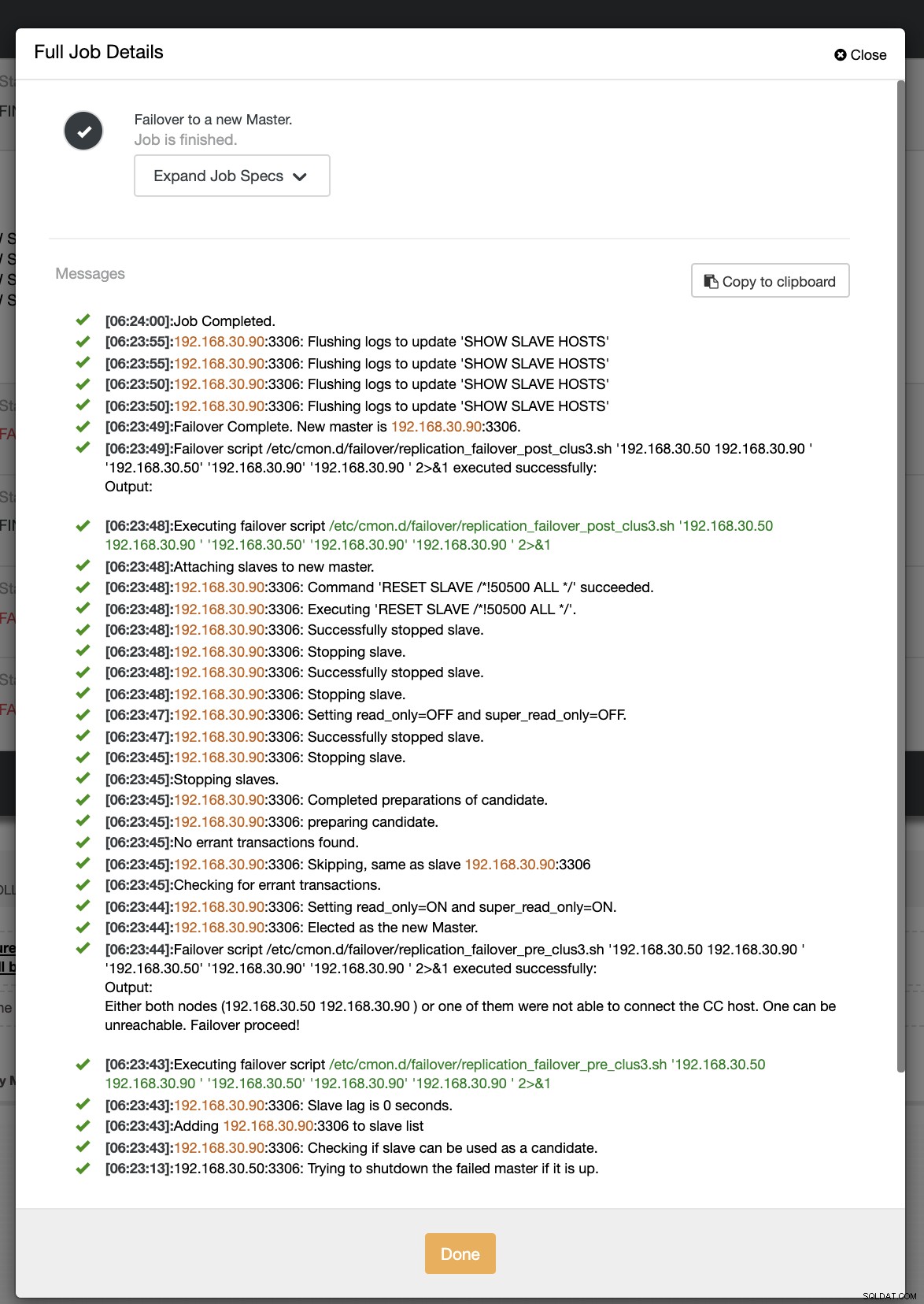
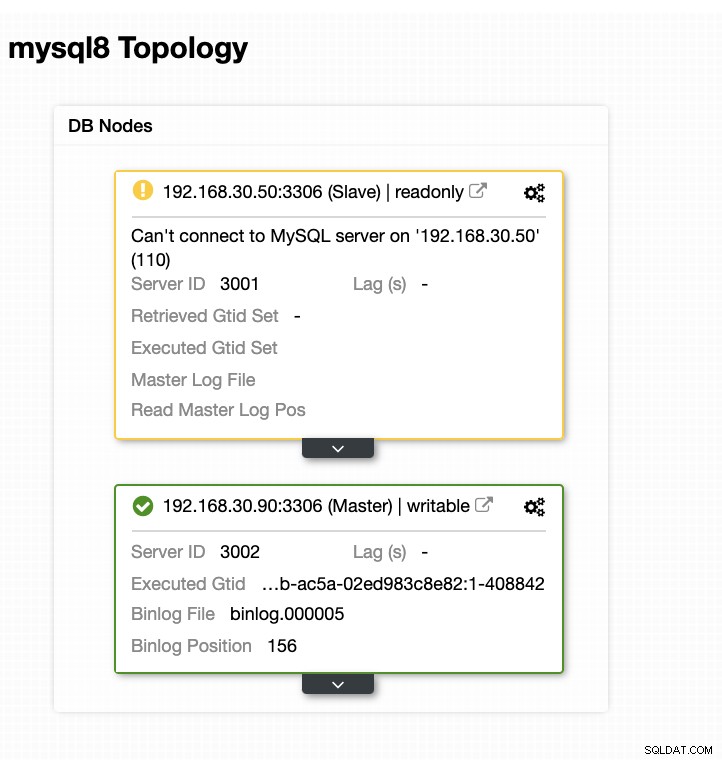
Tecnicamente, depois de definir as seguintes opções de configuração em seu arquivo de configuração /etc/cmon.d/cmon_ Como alternativa, você também pode definir as opções de configuração acessando Essa abordagem ainda exigiria uma reinicialização do serviço cmon antes que ele pudesse refletir o alterações feitas para essas opções de configuração para ganchos de script pré/pós. Idealmente, os ganchos de script pré/pós são dedicados quando você precisa de um failover avançado para o qual o ClusterControl não conseguiu gerenciar a complexidade da configuração do banco de dados. Por exemplo, se você estiver executando data centers diferentes com segurança reforçada e quiser determinar se o alerta de rede inacessível não é um alarme falso positivo. Ele deve verificar se o primário e o escravo podem alcançar um ao outro e vice-versa e também podem alcançar dos nós do banco de dados que vão para o host ClusterControl. Vamos fazer isso em nosso exemplo e demonstrar como você pode se beneficiar dele. Neste exemplo, estou usando um cluster de replicação MariaDB com apenas um primário e uma réplica. Gerenciado pelo ClusterControl para gerenciar o failover. Controle de Cluster =192.168.40.110 primário (debnode5) =192.168.30.50 réplica (debnode9) =192.168.30.90 No nó primário, crie o script conforme indicado abaixo, Certifique-se de que o /opt/pre_failover.sh seja executável, ou seja, Então use este script para se envolver via cron. Neste exemplo, criei um arquivo /etc/cron.d/ccfailover e tenho o seguinte conteúdo: Na sua réplica, basta usar as etapas a seguir que fizemos para o primário, exceto alterar o nome do host. Veja abaixo o que tenho na minha réplica: e certifique-se de que o script invocado em nosso cron seja executável, Nesta demonstração, meu cluster_id é 3. Conforme declarado anteriormente em nossa documentação, ele requer que esses scripts residam em nosso host do controlador CC. Então, no meu /etc/cmon.d/cmon_3.cnf, tenho o seguinte: Considerando que o script de failover "pré" a seguir determina se ambos os nós conseguiram alcançar o host do controlador CC. Veja o seguinte: Agora, vamos tentar simular a interrupção da rede no nó primário e ver como ele reagirá. No meu nó primário, desativo a interface de rede que é usada para se comunicar com a réplica e o controlador CC. Durante a primeira tentativa de failover, CC conseguiu executar meu pré-script que está localizado em /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Veja abaixo como funciona: Obviamente, ele falha porque o carimbo de data/hora que foi registrado ainda não tem mais de um minuto ou foi apenas alguns segundos atrás que o primário ainda conseguiu se conectar ao controlador CC. Obviamente, essa não é a abordagem perfeita quando você está lidando com um cenário real. No entanto, o ClusterControl conseguiu invocar e executar o script perfeitamente conforme o esperado. Agora, que tal se realmente atingir mais de um minuto (ou seja,> 60 segundos)? Em nossa segunda tentativa de failover, como o timestamp atinge mais de 60 segundos, então ele considera um verdadeiro positivo, e isso significa que temos que fazer o failover conforme pretendido. CC foi capaz de executá-lo perfeitamente e até mesmo executar o script de postagem conforme pretendido. Isso pode ser visto no log de trabalho. Veja a imagem abaixo: Verificando se meu post script foi executado, foi possível criar o log arquivo no diretório CC /tmp como esperado, script de pós-falha no cluster 3 com argumentos:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90 Agora, minha topologia foi alterada e o failover foi bem-sucedido! Para qualquer configuração de banco de dados complicada que você possa ter, quando um failover avançado é necessário, scripts pré/pós podem ser muito úteis para tornar as coisas viáveis. Como o ClusterControl oferece suporte a esses recursos, demonstramos como ele é poderoso e útil. Mesmo com suas limitações, sempre há maneiras de tornar as coisas viáveis e úteis, especialmente em ambientes de produção.
$ systemctl restart cmon
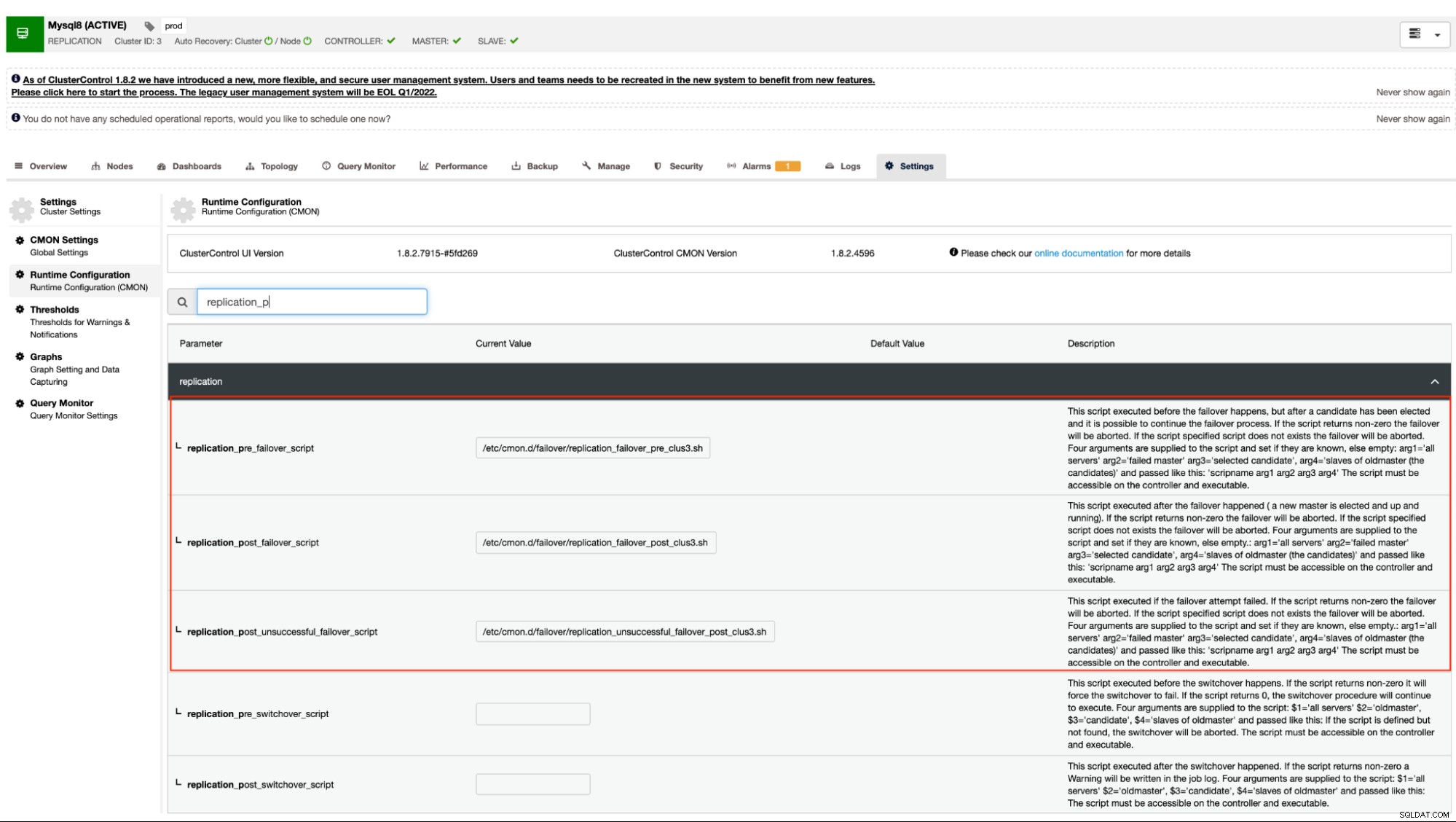
Exemplo de ganchos de script pré/pós
Detalhes do servidor e os scripts
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"
$ chmod +x /opt/pre_failover.sh
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shScripts pré/pós do ClusterControl
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.sh
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Demonstração do failover
example@sqldat.com:~# ip link set enp0s8 down
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txt
Conclusão