É bastante comum ver bancos de dados distribuídos em várias localizações geográficas. Um cenário para fazer esse tipo de configuração é para recuperação de desastres, em que o datacenter em espera está localizado em um local separado do datacenter principal. Também pode ser necessário para que os bancos de dados estejam localizados mais próximos dos usuários.
O principal desafio para alcançar essa configuração é projetar o banco de dados de uma forma que reduza a chance de problemas relacionados ao particionamento da rede. Uma das soluções pode ser usar o Galera Cluster em vez da replicação assíncrona regular (ou semi-síncrona). Neste blog vamos discutir os prós e contras desta abordagem. Esta é a primeira parte de uma série de dois blogs. Na segunda parte vamos projetar o Galera Cluster geo-distribuído e ver como o ClusterControl pode nos ajudar a implantar tal ambiente.
Por que o Galera Cluster em vez de replicação assíncrona para clusters distribuídos geograficamente?
Vamos considerar as principais diferenças entre o Galera e a replicação regular. A replicação regular fornece apenas um nó para gravar, o que significa que cada gravação do datacenter remoto teria que ser enviada pela Wide Area Network (WAN) para alcançar o mestre. Isso também significa que todos os proxies localizados no datacenter remoto precisarão monitorar toda a topologia, abrangendo todos os datacenters envolvidos, pois precisam saber qual nó é atualmente o mestre.
Isso leva ao número de problemas. Primeiro, várias conexões precisam ser estabelecidas na WAN, isso adiciona latência e diminui a velocidade de qualquer verificação que o proxy possa estar executando. Além disso, isso adiciona sobrecarga desnecessária nos proxies e bancos de dados. Na maioria das vezes, você está interessado apenas em rotear o tráfego para os nós do banco de dados local. A única exceção é o mestre e só por isso os proxies são obrigados a vigiar toda a infraestrutura e não apenas a parte localizada no datacenter local. Claro, você pode tentar superar isso usando proxies para rotear apenas SELECTs, enquanto usa algum outro método (nome de host dedicado para mestre gerenciado pelo DNS) para apontar o aplicativo para mestre, mas isso adiciona níveis desnecessários de complexidade e partes móveis, que pode afetar seriamente sua capacidade de lidar com vários nós e falhas de rede sem perder a consistência dos dados.
O Galera Cluster pode suportar vários gravadores. A latência também é um fator, já que todos os nós no cluster Galera precisam coordenar e se comunicar para certificar conjuntos de gravação, pode até ser o motivo pelo qual você pode decidir não usar o Galera quando a latência for muito alta. Também é um problema em clusters de replicação - em clusters de replicação a latência afeta apenas as gravações dos datacenters remotos, enquanto as conexões do datacenter onde o mestre está localizado se beneficiariam de confirmações de baixa latência.
Na Replicação do MySQL, você também deve considerar o pior cenário possível e garantir que o aplicativo esteja ok com gravações atrasadas. O mestre sempre pode mudar e você não pode ter certeza de que estará gravando em um nó local o tempo todo.
Outra diferença entre a replicação e o Galera Cluster é o tratamento do atraso da replicação. Os clusters distribuídos geograficamente podem ser seriamente afetados pelo atraso:latência, taxa de transferência limitada da conexão WAN, tudo isso afetará a capacidade de um cluster replicado de acompanhar a replicação. Lembre-se de que a replicação gera um para todo o tráfego.
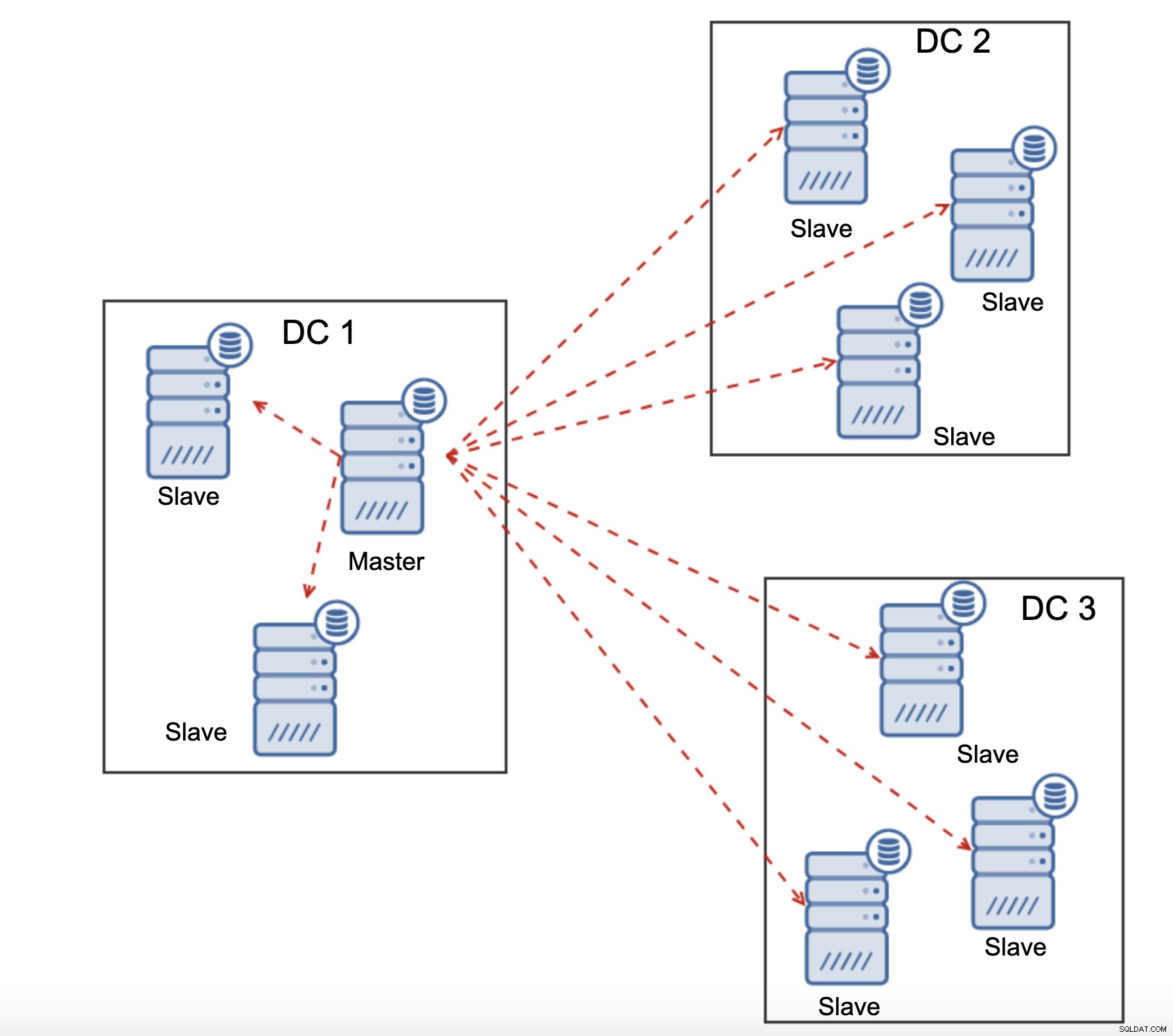
Todos os escravos precisam receber todo o tráfego de replicação - a quantidade de dados que você possui para enviar para escravos remotos pela WAN aumenta com cada escravo remoto que você adiciona. Isso pode resultar facilmente na saturação do link WAN, especialmente se você fizer muitas modificações e o link WAN não tiver uma boa taxa de transferência. Como você pode ver no diagrama acima, com três data centers e três nós em cada um deles, o mestre precisa enviar 6x o tráfego de replicação pela conexão WAN.
Com o Galera cluster as coisas são um pouco diferentes. Para começar, o Galera usa o controle de fluxo para manter os nós sincronizados. Se um dos nós começar a ficar para trás, ele tem a capacidade de pedir ao resto do cluster para diminuir a velocidade e deixá-lo acompanhar. Claro, isso reduz o desempenho de todo o cluster, mas ainda é melhor do que quando você não pode realmente usar escravos para SELECTs, pois eles tendem a atrasar de tempos em tempos - nesses casos, os resultados obtidos podem estar desatualizados e incorretos.
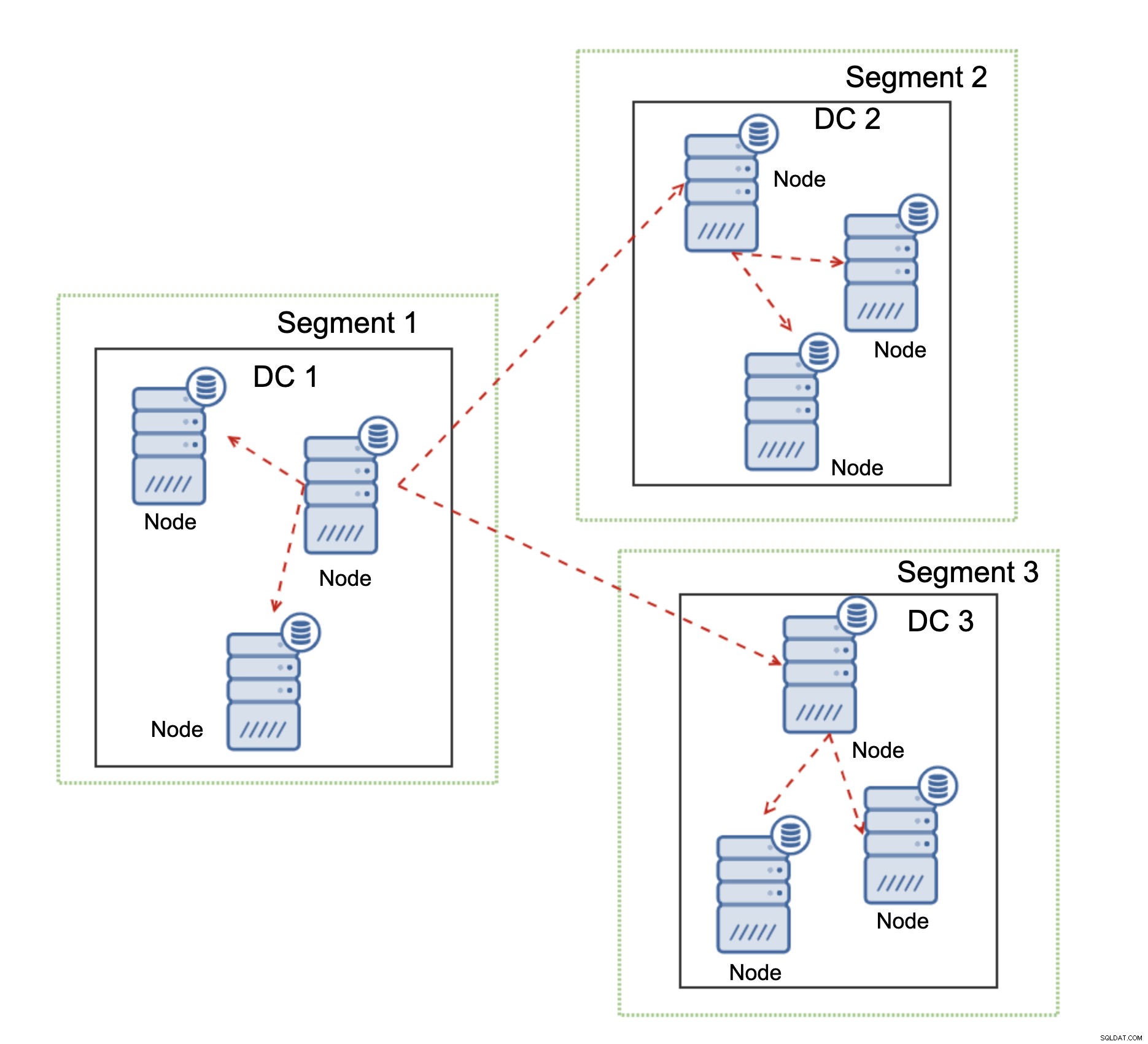
Outro recurso do Galera Cluster, que pode melhorar significativamente seu desempenho quando usado em WAN, são segmentos. Por padrão, o Galera usa a comunicação all to all e cada writeset é enviado pelo nó para todos os outros nós do cluster. Esse comportamento pode ser alterado usando segmentos. Os segmentos permitem que os usuários dividam o cluster Galera em várias partes. Cada segmento pode conter vários nós e elege um deles como um nó de retransmissão. Esse nó recebe writesets de outros segmentos e os redistribui entre os nós Galera locais para o segmento. Como resultado, como você pode ver no diagrama acima, é possível reduzir três vezes o tráfego de replicação que passa pela WAN - apenas duas “réplicas” do fluxo de replicação estão sendo enviadas pela WAN:uma por datacenter comparada a uma por escravo na replicação do MySQL.
Galera Cluster Network Partitioning Handling
O Galera Cluster se destaca no manuseio do particionamento de rede. O Galera Cluster monitora constantemente o estado dos nós do cluster. Cada nó tenta se conectar com seus pares e trocar o estado do cluster. Se o subconjunto de nós não for alcançável, o Galera tentará retransmitir a comunicação para que, se houver uma maneira de alcançar esses nós, eles sejam alcançados.

Um exemplo pode ser visto no diagrama acima:DC 1 perdeu a conectividade com DC2, mas DC2 e DC3 podem se conectar. Neste caso, um dos nós em DC3 será usado para retransmitir dados de DC1 para DC2 garantindo que a comunicação intra-cluster possa ser mantida.
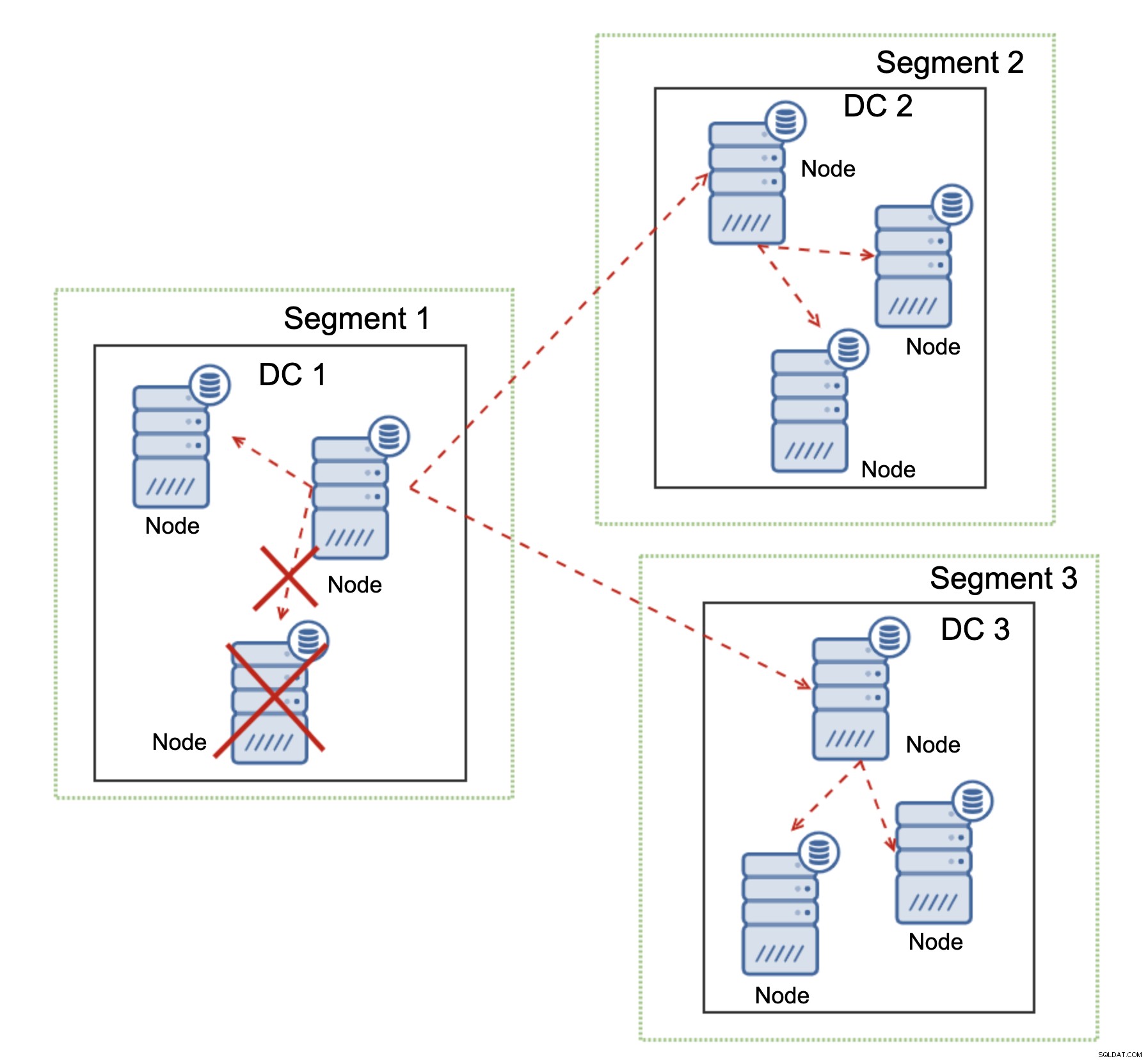
O Galera Cluster pode executar ações com base no estado do cluster. Ele implementa o quorum - a maioria dos nós precisa estar disponível para que o cluster possa operar. Se o nó for desconectado do cluster e não puder alcançar nenhum outro nó, ele deixará de operar.
Como pode ser visto no diagrama acima, há uma perda parcial da comunicação de rede no DC1 e o nó afetado é removido do cluster, garantindo que o aplicativo não acesse dados desatualizados.
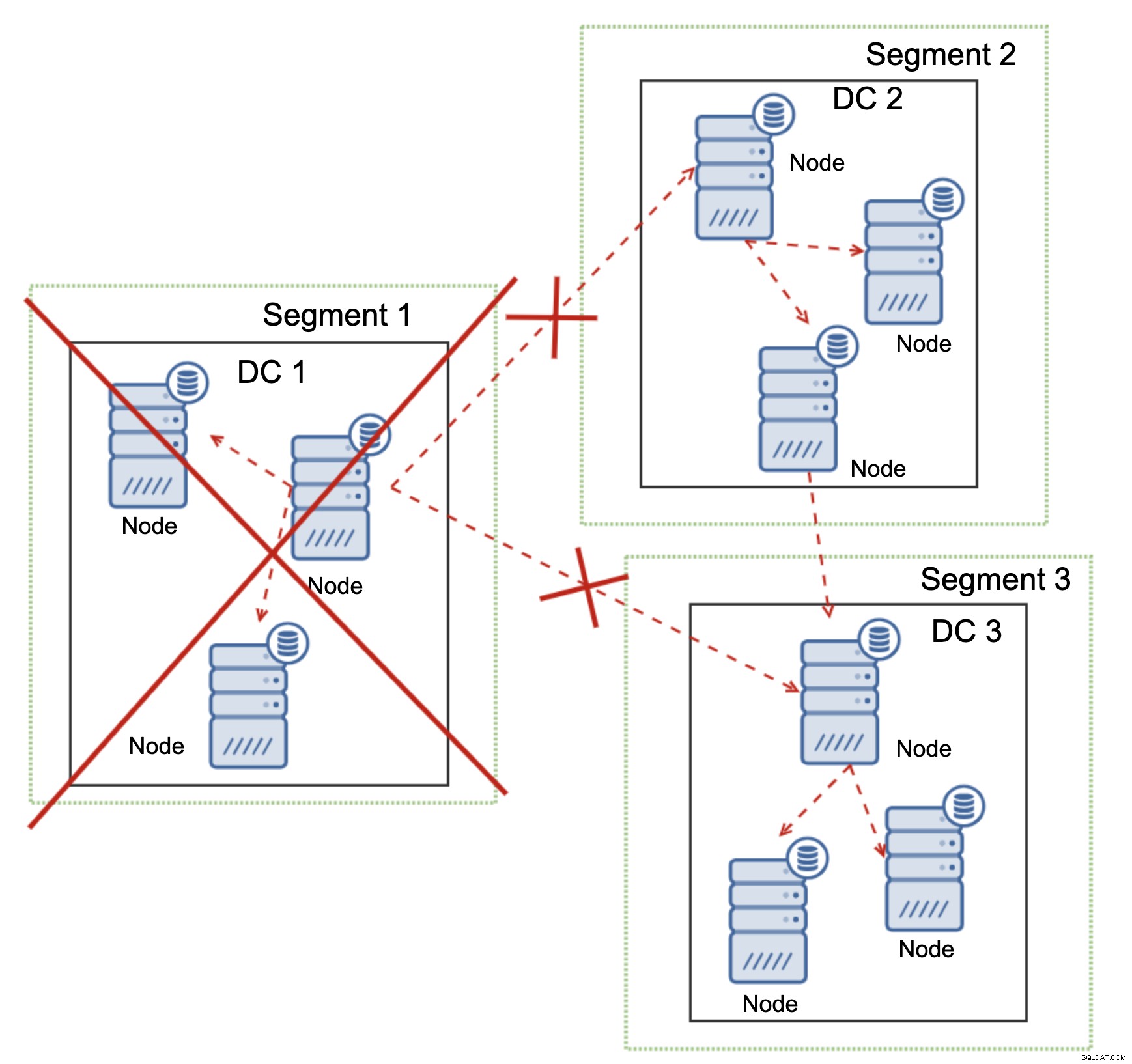
Isso também é verdade em uma escala maior. O DC1 teve todas as comunicações cortadas. Como resultado, todo o datacenter foi removido do cluster e nenhum de seus nós atenderá ao tráfego. O resto do cluster manteve a maioria (6 de 9 nós estão disponíveis) e se reconfigurou para manter a conexão entre DC 2 e DC3. No diagrama acima, assumimos que a gravação atinge o nó no DC2, mas lembre-se de que o Galera é capaz de executar com vários gravadores.
A Replicação MySQL não tem nenhum tipo de reconhecimento de cluster, tornando problemático lidar com problemas de rede. Ele não pode se desligar ao perder a conexão com outros nós. Não há uma maneira fácil de impedir que o antigo mestre apareça após a divisão da rede.
As únicas possibilidades são limitadas à camada proxy ou até mesmo superior. Você tem que projetar um sistema, que tentaria entender o estado do cluster e tomar as ações necessárias. Uma maneira possível é usar ferramentas com reconhecimento de cluster, como o Orchestrator, e executar scripts que verificariam o estado do cluster RAFT do Orchestrator e, com base nesse estado, executar as ações necessárias na camada de banco de dados. Isso está longe de ser o ideal porque qualquer ação realizada em uma camada superior ao banco de dados adiciona latência adicional:possibilita que o problema apareça e a consistência dos dados seja comprometida antes que a ação correta possa ser tomada. O Galera, por outro lado, realiza ações no nível do banco de dados, garantindo a reação mais rápida possível.