O
ANY agregado não é algo que podemos escrever diretamente no Transact SQL. É um recurso interno usado apenas pelo otimizador de consulta e mecanismo de execução. Pessoalmente, gosto bastante do
ANY agregado, então foi um pouco decepcionante saber que ele está quebrado de uma maneira bastante fundamental. O sabor particular de “quebrado” ao qual me refiro aqui é a variedade de resultados errados. Neste post, dou uma olhada em dois lugares específicos onde o
ANY agregado geralmente aparece, demonstra o problema de resultados errados e sugere soluções alternativas quando necessário. Para obter informações sobre o
ANY agregado, veja meu post anterior Planos de consulta não documentados:O ANY Aggregate. 1. Uma linha por consultas de grupo
Este deve ser um dos requisitos de consulta mais comuns do dia a dia, com uma solução muito conhecida. Você provavelmente escreve esse tipo de consulta todos os dias, seguindo automaticamente o padrão, sem realmente pensar nisso.
A ideia é numerar o conjunto de linhas de entrada usando o
ROW_NUMBER função de janela, particionada pela coluna ou colunas de agrupamento. Isso é encapsulado em uma Expressão de tabela comum ou tabela derivada , e filtrado para linhas em que o número de linha calculado é igual a um. Desde o ROW_NUMBER reinicia em um para cada grupo, isso nos dá a linha necessária por grupo. Não há problema com esse padrão geral. O tipo de consulta de uma linha por grupo que está sujeita ao
ANY problema agregado é aquele em que não nos importamos com qual linha específica é selecionada de cada grupo. Nesse caso, não está claro qual coluna deve ser usada no
ORDER BY obrigatório cláusula do ROW_NUMBER função de janela. Afinal, explicitamente não nos importamos qual linha está selecionada. Uma abordagem comum é reutilizar o PARTITION BY coluna(s) no ORDER BY cláusula. É aqui que o problema pode ocorrer. Exemplo
Vejamos um exemplo usando um conjunto de dados de brinquedo:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222); O requisito é retornar qualquer linha completa de dados de cada grupo, onde a associação ao grupo é definida pelo valor na coluna
c1 . 
Seguindo o
ROW_NUMBER padrão, podemos escrever uma consulta como a seguinte (observe o ORDER BY cláusula do ROW_NUMBER função de janela corresponde a PARTITION BY cláusula):WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Conforme apresentado, esta consulta é executada com sucesso, com resultados corretos. Os resultados são tecnicamente não determinísticos já que o SQL Server pode retornar validamente qualquer uma das linhas em cada grupo. No entanto, se você executar essa consulta por conta própria, é bem provável que veja o mesmo resultado que eu:
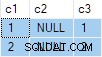
O plano de execução depende da versão do SQL Server usada e não depende do nível de compatibilidade do banco de dados.
No SQL Server 2014 e anteriores, o plano é:

Para SQL Server 2016 ou posterior, você verá:

Ambos os planos são seguros, mas por motivos diferentes. A Classificação Distinta plano contém um
ANY agregado, mas a Classificação Distinta implementação do operador não manifesta o bug. O plano mais complexo do SQL Server 2016+ não usa o
ANY agregado em tudo. A Classificação coloca as linhas na ordem necessária para a operação de numeração de linhas. O Segmento O operador define um sinalizador no início de cada novo grupo. O Projeto Sequência calcula o número da linha. Por fim, o Filtro operador passa apenas as linhas que têm um número de linha calculado de um. O erro
Para obter resultados incorretos com esse conjunto de dados, precisamos usar o SQL Server 2014 ou anterior e o
ANY agregados precisam ser implementados em um Stream Aggregate ou Hash Aggregate operador (Flow Distinct Hash Match Aggregate não produz o bug). Uma maneira de incentivar o otimizador a escolher um Stream Aggregate em vez de Classificação distinta é adicionar um índice clusterizado para fornecer ordenação por coluna
c1 :CREATE CLUSTERED INDEX c ON #Data (c1);
Após essa alteração, o plano de execução se torna:

O
ANY agregados são visíveis nas Propriedades janela quando o Stream Aggregate operador é selecionado:
O resultado da consulta é:
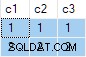
Isso está errado . O SQL Server retornou linhas que não existem nos dados de origem. Não há linhas de origem em que
c2 = 1 e c3 = 1 por exemplo. Como lembrete, os dados de origem são: O plano de execução calcula erroneamente separado
ANY agregados para o c2 e c3 colunas, ignorando nulos. Cada agregado independentemente retorna o primeiro não nulo valor que encontra, dando um resultado onde os valores para c2 e c3 vêm de diferentes linhas de origem . Isso não é o que a especificação de consulta SQL original solicitou. O mesmo resultado errado pode ser produzido com ou sem o índice clusterizado adicionando uma
OPTION (HASH GROUP) dica para produzir um plano com um Eager Hash Aggregate em vez de um Stream Aggregate . Condições
Este problema só pode ocorrer quando vários
ANY agregados estão presentes e os dados agregados contêm nulos. Conforme observado, o problema afeta apenas o Stream Aggregate e Ansioso Agregado de Hash operadores; Classificação distinta e Fluxo distinto não são afetados. O SQL Server 2016 em diante faz um esforço para evitar a introdução de vários
ANY agrega para qualquer padrão de consulta de numeração de linha por linha por grupo quando as colunas de origem são anuláveis. Quando isso acontecer, o plano de execução conterá Segmento , Projeto de sequência e Filtrar operadores em vez de um agregado. Esta forma de plano é sempre segura, pois não há ANY agregados são usados. Reproduzindo o bug no SQL Server 2016+
O otimizador do SQL Server não é perfeito para detectar quando uma coluna originalmente restrita para ser
NOT NULL ainda pode produzir um valor intermediário nulo por meio de manipulações de dados. Para reproduzir isso, começaremos com uma tabela onde todas as colunas são declaradas como
NOT NULL :IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3); Podemos produzir nulos a partir desse conjunto de dados de várias maneiras, a maioria das quais o otimizador pode detectar com sucesso e, portanto, evitar a introdução de
ANY agregados durante a otimização. Uma maneira de adicionar nulos que passam despercebidos é mostrada abaixo:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Essa consulta produz a seguinte saída:
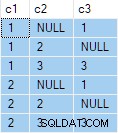
A próxima etapa é usar essa especificação de consulta como os dados de origem para a consulta padrão “qualquer linha por grupo”:
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Em qualquer versão do SQL Server, que produz o seguinte plano:
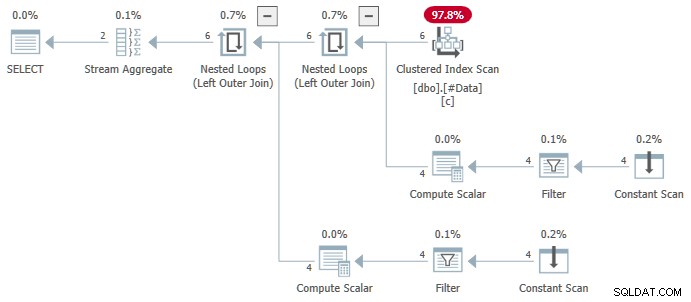
O Agregado de fluxo contém vários
ANY agregados, e o resultado é errado . Nenhuma das linhas retornadas aparece no conjunto de dados de origem: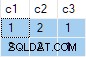
db<>demonstração online de violino
Solução
A única solução totalmente confiável até que esse bug seja corrigido é evitar o padrão em que o
ROW_NUMBER tem a mesma coluna no ORDER BY cláusula como está no PARTITION BY cláusula. Quando não nos importamos qual uma linha é selecionada de cada grupo, é lamentável que um
ORDER BY cláusula é absolutamente necessária. Uma maneira de contornar o problema é usar uma constante de tempo de execução como ORDER BY @@SPID na função janela. 2. Atualização não determinística
O problema com vários
ANY agregações em entradas anuláveis não são restritas a qualquer linha por padrão de consulta de grupo. O otimizador de consulta pode introduzir um ANY interno agregado em várias circunstâncias. Um desses casos é uma atualização não determinística. Um não determinístico update é onde a instrução não garante que cada linha de destino seja atualizada no máximo uma vez. Em outras palavras, há várias linhas de origem para pelo menos uma linha de destino. A documentação alerta explicitamente sobre isso:
Tenha cuidado ao especificar a cláusula FROM para fornecer os critérios para a operação de atualização.
Os resultados de uma instrução UPDATE são indefinidos se a instrução incluir uma cláusula FROM não especificada de forma que apenas um valor esteja disponível para cada ocorrência de coluna atualizada, que é se a instrução UPDATE não for determinística.
Para lidar com uma atualização não determinística, o otimizador agrupa as linhas por uma chave (índice ou RID) e aplica
ANY agrega às colunas restantes. A ideia básica é escolher uma linha de vários candidatos e usar os valores dessa linha para realizar a atualização. Existem paralelos óbvios com o ROW_NUMBER anterior problema, portanto, não é surpresa que seja muito fácil demonstrar uma atualização incorreta. Ao contrário da edição anterior, o SQL Server atualmente não executa nenhuma etapa especial para evitar vários
ANY agrega em colunas anuláveis ao executar uma atualização não determinística. Portanto, o seguinte se refere a todas as versões do SQL Server , incluindo SQL Server 2019 CTP 3.0. Exemplo
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>demonstração online de violino
Logicamente, esta atualização deve sempre produzir um erro:A tabela de destino não permite nulos em nenhuma coluna. Qualquer que seja a linha correspondente escolhida na tabela de origem, uma tentativa de atualizar a coluna
c2 ou c3 para nulo deve ocorrer. Infelizmente, a atualização é bem-sucedida e o estado final da tabela de destino é inconsistente com os dados fornecidos:
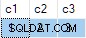
Eu relatei isso como um bug. A solução é evitar escrever
UPDATE não determinístico declarações, então ANY agregados não são necessários para resolver a ambiguidade. Como mencionado, o SQL Server pode introduzir
ANY agregados em mais circunstâncias do que os dois exemplos dados aqui. Se isso acontecer quando a coluna agregada contiver nulos, existe a possibilidade de resultados errados.